

“The first thing you need to do is get all the data in the same place”. We all remember the mantra that launched a thousand painful IT projects. The argument was that this would enable a “360-degree view of the customer” or “data-driven” decisions. After millions of dollars and multi-year implementations, many companies are hard-pressed to quantify the business benefits of these initiatives. The telling term here is these efforts were supposed to ‘enable’ analytics, rather than deliver value.
The ‘data first’ enterprise is misguided from a data science perspective. Firstly, there is an infinite amount of useful data out there. Secondly, rigorous data science works from the top down — from objective to the dependent data. Accordingly, the first thing you have to do is define a business objective and metric.
A new breed of charlatan has arisen, and he is selling actionable insights — which is about as tangible as gelatin. We are now a few years into an AI-hype bubble. Every consulting firm, system integrator, IT firm, software provider, even tax and audit firm — is now claiming expertise. They all profess to occupy prime real-estate in a magic quadrant. When focused on delivering value, a well-conceived data science project should be able to break even within 6 months. How do you sift through the mathematics, visualizations, and magic demos to choose an analytic partner who can deliver on this promise?
In this article, we argue analytics is no different from any other business endeavor and can be assessed and managed accordingly. This article offers suggestions for both phases. The first part highlights key questions to discriminate and evaluate vendors at the proposal phase. The second part highlights some best practices in managing an engagement for success.
1. Vendor Due Diligence
The first question to ask should be obvious: “What is their Unique Value Proposition (UVP)?” Yet, a large number of vendors are hard pressed to provide a credible answer. Do they have a unique data source? Do they have proven analytic assets? Can they readily integrate and assess the value of third-party data? Do they have a stable of experienced, world-class scientists?
Most large organizations run on inertia. They also tend to value only what they know, leading them to conflate their legacy practices with Data Science. If their legacy practices were selling mainframes, they are now pushing cloud. System integrators and consultancies continue to sell complex integrations and consulting. The Big 4 tend to sell BI and reporting tools. Others are selling ‘platforms.’ The familiar pitch has been, “You need this stuff first; the data science can be added on later.” This pitch has the convenient side benefit in that infrastructure, BI, computing resources, platforms, and software tools do not have to be justified by business value or ROI. There may be a need for many of these things, but their costs should be justified by empirical analysis, in other words, Data Science.
Does the leadership actually have data science expertise? Many firms have simply re-branded their services and staff as ‘Data Science.’ Therefore, it is not rude to ask for credentials. Try looking up their profiles on Linkedin or Google Scholar. It is surprising how many organizations have literally no scientists on staff, or claim to have “a bunch of data scientists off-shore, somewhere.”
In an illuminating interview, a Big 4 Senior Partner of Artificial Intelligence admitted that his team has no data assets, no analytics assets, no data scientists, and one successful consulting project in two years. He went on to boast he has never hired a data scientist that was over 26 years old. His practice lead did not even have a college degree. Meeting the full team over a dinner, the Global Head of Artificial Intelligence regaled us with stories about how socially awkward scientists are. When asked how can his firm compete with other providers, he explained his strategy: “[w]e are a trusted professional services partner. We are already embedded in their business. We can do their data science as well.” Apparently, their primary UVP is chutzpah.
Contrary to current zeitgeist, the industry is not suffering from a shortage of skills or junior resources. But there is certainly a shortage of leaders with a deep understanding of the underlying mathematics and track record of successful data science solutions. Most engagements also require a field engineering lead — someone to work directly with the Business and Operations lead, to capture the process flows and business constraints, IT, decision points, ultimate source of both input and outcome data. No one wants to run a project through intermediaries, across time zones, etc. It adds a great deal of confusion, delay, and overhead and puts delivery at risk.
Is their proposal detailed enough to be technically assessed? The vendor’s approach needs to be both technically credible and feasible. If they cannot explain their technologies, why should you trust them? If the vendor evades detail by citing proprietary IP, there is no ‘There’ there. Intellectual Property that is so basic that it can be stolen in a 15-minute dialogue is not very impressive.
Also, the specific algorithms proposed may or may not have relevance or value to your business problems. A “neural network” is a real thing, quite well-defined over decades of research. “Natural Language Processing” simply means “we extract information from text” and can refer to technology as simple as keyword matches. “Cognitive” is an adjective.

A sound, technical approach is a necessary, but of course not a sufficient condition for success. For example, commercially successful fraud detection solutions have employed a wide variety of advanced algorithms, including anomaly detection, network analysis, graph theory, cluster analysis, number theory, decision trees, neural networks, linear programming, and Kalman filtering. Figure 1 compares the performance of two real-time fraud solutions. The incumbent solution (blue) combines expert rules with optimized decision trees. The challenger solution (yellow) combines temporal signal processing, NLP, and neural networks. (A third approach, using a cognitive linear programming solution failed to improve on the legacy solution and was dropped from the competition.) The challenger solution has nearly double the statistical performance of the former, which directly translates into a 100% reduction in either fraud losses or operating costs. All three approaches have credible analytical and theoretical foundations; the only way to resolve which approach is superior is an empirical test.
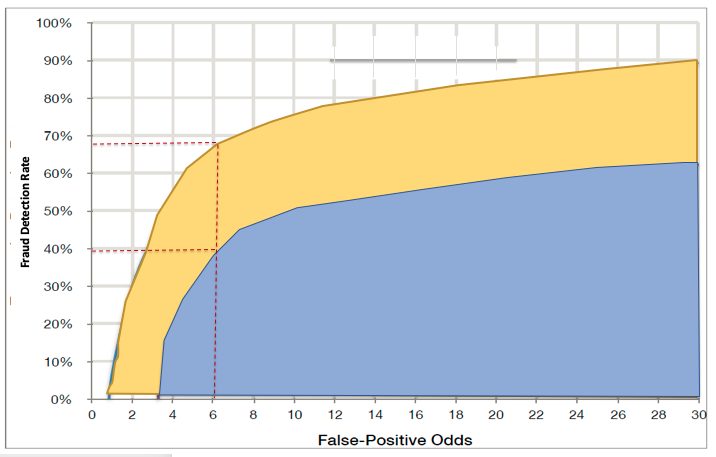
Figure 1: Performance Comparisons: don’t leave home without it
Do they have an ROI or statistical performance comparison in their case studies? There really is no excuse for not being able to quote performance. Data science implies a disciplined, empirical approach to business problems. Performance and business benefit over the BAU practice can be directly calculated on the data, or if necessary, tested in a champion/ challenger live rollout.
Were the case studies performed on real, client data? This question should rightly raise alarm, but a surprising number of solutions on the market have never actually been tested on live data, or were developed on ancillary or unrelated datasets. To a data scientist, this is literally inconceivable, but solutions built on “synthetic data” are common in legacy software companies, as the focus historically has been on establishing a standardized API, rather than extracting value from the data. Many firms do not even secure access their client data, so literally cannot validate whether their solution can deliver value. Such systems are often essentially rules engines, and can severely limit the sophistication and value of downstream decisioning technologies.
Can they provide a reference site? A frustrating fact of life is that customers are not always willing to serve as a reference site. Given the sensitivity of some projects, this is understandable. However, if a promising vendor does not have an “Alpha” deployment and its technical approach and team seem credible, you have a unique opportunity to negotiate price. Being a public reference site and data research rights are all assets that are traded for services. Entering into a co-development agreement allows you to build out bespoke new functionality at a discount. At many of the large consultancies, the Data Science teams have been running as a loss for many years, and they will be eager to publicly prove their bonafide as well as have access to a real dataset for research and product improvements.
2. Vendor Management Best Practices
Ideally, a data science engagement should generate three deliverables: a diagnostic, a proof of value, and an implementation plan. A steering committee should be convened to review each deliverable in the course of the engagement.
Establish a steering/review committee. From the onset, the project should be overseen by a standing committee of the key stakeholders (typically the P&L owner, line of business or product owner, the operations lead, and an analytics lead). Internal IT team leaders can be used to conduct due diligence, But IT departments typically do not have data science skills and can ‘cost’ a project out of existence (inflating the implementation cost estimates) no matter how trivial, if they don’t understand the mission or the technologies being used. Analytics teams can actively or passive sabotage an objective test, by non-cooperation. Another route is to engage a third-party advisor to conduct vendor due diligence.
Define business objectives and performance metrics. As much as practicable, the engineering objective should be defined by the business metrics (profit, revenue, costs, losses, incidence rates, conversion rates, and so on.). Clear metrics also simplifies due diligence, establishing concrete client expectations and a ‘success criteria’ for the vendor. Two examples of poor choices for proof-of-concept goals are predicting customer attrition or creating a customer segmentation. Neither of these efforts has any direct business benefit. (An attrition model just predicts you are going to lose certain customers, not what to do about it.) Both use cases can be delivered quickly, with moderately-skilled analysts; hence, neither use case serves as a strong test of the vendor’s competence or technology.
Any business outcome or KPI can be used as a target, and if it can be measured, it can be predicted. In a full data diagnostic, the information value of current and potential data sources can be measured against these metrics. Even the value of an “Art of the Possible” POC can be simply and clearly stated in terms of cost reduction or revenue opportunities identified.
Schedule a “Go/No-Go” review early in the project. “No plan survives contact with the data,” an aphorism borrowed from Clausewitz, is rarely proven wrong. Within 2–3 weeks of providing access to the data, an interim review should be scheduled to review the preliminary results. By this time, the vendor should have been able to verify if objective is supported by the data and provide a guarantee of minimal performance. On the other hand, in the course of analysis, the vendor may have discovered and recommended alternative objectives and priorities.
This initial report, sometimes called a ‘Diagnostic,’ or ‘Sizing and Opportunity Analysis’ — in and of itself — should be viewed as a deliverable. Oftentimes, deep empirical analyses of efficiencies, performance drivers, and root causes produces value-added recommendations of policy and process that do not require a predictive analytic solution. In this sense, such ‘actionable insights’ are a bonus, collateral benefits of a data science engagement. While there is no guarantee that such ‘quick fixes’ exist, typically the benefits of implementing these recommendations can exceed the entire project cost.
After reviewing the results, the steering committee can then decide to abort the project, re-commit or reprioritize the objectives, and create a plan to exploit and test the learnings to date. From this point on, there should be no doubt whether the approach will deliver value; there should only be questions regarding the magnitude of the benefits and implementation costs.
Lastly, beware of expensive implementation plans. Up front, sometimes only indicative implementation costs be estimated, as many of the constraints and data and infrastructure requirements are discovered or established in the process of building a prototype. Whether the vendor is selling SaaS, a platform, on installing on-premises, reasonable provisions should be established early for the cost of expanded functionality, including the ability to install third party and in-house solutions.
Some firms will try to recoup their costs at this stage, by overselling platforms and infrastructure. Several industries heavily rely on decades-old decision engines. Replacing these systems is an expensive proposition, and often not necessary for data science delivery. An infrastructure agnostic scoring engine can be used to create customer decisions, which in turn, can be ‘pushed’ into legacy decision engines, loaded as a table into a database, or fed into existing BI tools. This minimally invasive approach, working in parallel with production data flows or systems of record, is both the fastest course to value and the lowest cost. Enhancements and added functionality are relatively painless, as the Data Science delivery team has ongoing ownership of the engine.
The potential of data science continues to be diluted by ill-conceived initiatives and pretender practitioners. The keys to success are to conduct rigorous due diligence, define the business problem, establish clear metrics, and run a proof of value. There is gold in these hills, but be careful of who you choose to prospect with.
Russell Anderson (Director, Transaction Analytics Advisory) has over 25 years’ experience developing data science solutions in the financial services, retail, ecommerce, and biomedical industries. He has served as Scientific Advisor for several prominent analytics firms, including IBM, KPMG, Opera Solutions, NICE/Actimize, HCL, HNC Software, Mastercard Europe, JP Morgan Chase, and Halifax Bank of Scotland. He has a Ph.D. in Bioengineering from the University of California, has authored over 30 scientific publications, and holds several patents for commercial predictive solutions.
Original post can be viewed here.
Questions/Comments are welcome: [email protected]
{kind=link}