

Castaneda, Eduardo. Carl Sagan with the planets. 1981. Photograph. https://www.loc.gov/item/cosmos000104/. (Photo taken on the set of the TV show Cosmos.)
The Metaverse is a term appearing more and more in the tech press lately. Which begs the question, what does the term really mean? What does the concept actually imply from a feasibility standpoint? And most importantly, what are the prospects for something like a metaverse to appear and gain adoption?
The vision of a metaverse or mirrorworld
The Metaverse is a term coined by author Neal Stephenson for his 2003 book Snow Crash. In the book, Stephenson presents the Metaverse as an alternate, more manipulable and explicitly informative virtual and augmented reality. That overlay provided a pervasive, interactive, digital complement to physical reality. The term gained popularity among tech enthusiasts beginning in the 2000s.
More recently, folks like Mark Zuckerberg have co-opted the term. According to Zuckerberg as quoted by Kyle Chayka of The New Yorker, The metaverse is a virtual environment where you can be present with people in digital spaces. Its an embodied Internet that youre inside of rather than just looking at. We believe that this is going to be the successor to the mobile Internet. https://www.newyorker.com/culture/infinite-scroll/facebook-wants-us-to-live-in-the-metaverse
Facebook clearly hopes to expand the market for its Oculus goggles and its advertising, and is using the metaverse metaphor to help describe to its users how they might shop, game and interact more immersively online. Its a narrow, frankly self-serving view of what a metaverse might consist of.
Since Stephensons book was published, other terms have cropped up that describe a comparable concept. Kevin Kelly, for example, introduced his concept of a Mirrorworld (a term hardly original to him) in an article in Wired magazine in March 2019.
In a discussion with Forbes contributor Charlie Fink onstage at Augmented World Expo in August 2019, Kelly said,Mirrorworld is a one-to-one map of the real world thats in digital form. That is, theres a digital skin right over the real world that can be revealed using AR. Its at the same scale and in the same place, so its a skin. Or you could say its a ghost or its embedded in the same way. https://arinsider.co/2019/08/02/xr-talks-what-on-earth-is-mirrorworld/
During the discussion, Kelly and Fink both agreed that it could well take 25 years for the Mirrorworld to fully emerge as a commonly useful and scaled out digital skin.
Digital twins imagined
More explicitly, Kelly and Fink were really talking about the presentation layer or digital skin as 3D representations of people, places, things and concepts, and how they interact. Fink previously used the term metaverse in a similar context a year earlier. Either the mirrorworld or the metaverse, in other words, starts with interacting, interoperable representations known as digital twins (a term often used by academic MIchael Grieves beginning in 2002 in a product lifecycle manufacturing context).
At present, useful digital twins behave in limited, purpose-specific ways like the physical objects they represent. Manufacturers–GE, Schneider Electric and Siemens, for example–create digital twins of equipment such as gas turbines designed for use in power plants to predict failures at various points in each products lifecycle. Those twins help the manufacturers refine those designs.
But the longer-term vision is more expansive. All of these companies also have promising, but still nascent, initiatives in the works that could potentially expand and further connect digital twins in use. Consider, for instance, Siemens concept–at least four years old now–for an industrial knowledge graph that could empower many digital twins with relationship-rich, contextualizing data:
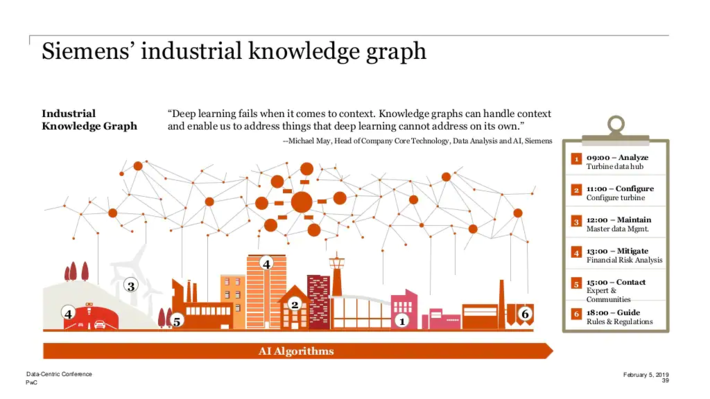
Some organizations envision even larger and more intricately interactive and useful aggregations of digital twins. The UKs Centre for Digital Built Britain(CDBB), for instance, imagines the entire built environment as an interconnected system if digital twins are developed to be interoperable, secure and connected.
Digital models of government agencies, when up and running, could conceivably be interconnected as a combination of models to provide views of past, present and future states of how these agencies interact in different contexts. For their part, asset-intensive industries such as pharmaceuticals, consumer products, transportation and agriculture are all working toward whole supply chain digitization.
Unfortunately, most data and knowledge management shops are not versed in the kind of web scale data management the UKs CDBB hopes to harness for these organization-sized digital twins. Nor do they have the authority or the budget to scale out their capabilities.
The Data (and Logic) Challenges of Interactive Virtual and Augmented Things
Stephenson, Kelly, and Finks visions are inspiring, but they are mainly imagining the possible from the perspective of users, without exploring the depths of the challenges organizations face to make even standalone twins of components of the vision a reality.
Data siloing and logic sprawl have long been the rule, rather than the exception, and companies are even less capable of managing data and limiting logic sprawl than they were during the advent of smartphones and mobile apps in the late 2000s and early 2010s.(See https://www.datasciencecentral.com/profiles/blogs/how-business-can-clear-a-path-for-artificial-general-intelligence for more information.)
What has this meant to the typical information-intensive enterprise? A mountain of 10,000+ databases to manage, thousands of SaaS and other subscriptions to oversee, custom code and many operating systems, tools, and services to oversee. All of these are spread across multiple clouds and controlled by de facto data cartels, each of which claims control based on its role in purposing the data early on in the provenance of that data.

Despite long-term trends that have helped with logic and data sharing such as current and future generations of the web, data is now more balkanized than ever, and the complexity is spiraling out of control.
The truth is, most of this out-of-control legacy + outsourced, application-centric cloud stack gets in the way of what were trying to do in a data-centric fashion with the help of knowledge graphs and a decentralized web.
Getting beyond data silos and code sprawl to a shared data and logic foundation
As you can imagine, moving beyond an entrenched paradigm that schools have been reinforcing for 40 years requires stepping back and rethinking how the digital ecosystem, such as it is, needs to be approached with a more critical eye. For starters, claims of automated data integration that are everywhere need to be considered with a grain of salt. The truth is, data agreement is hard, data integration is even harder, and interoperability is the hardest. And there are no interactive digital twins without interoperability.
So there are tiers of difficulty the data and knowledge science community has to confront. Predictably, the more capability needed, the more care and nurturing a knowledge foundation requires. In simple terms, the tiers can be compared and contrasted as follows:
- Agreement. Compatibility with and consistency of two or more entities or datasets
- Integration. Consolidation within a single dataset that provides broad data access and delivery
- Interoperability. Real-time data exchange and interpretation between different systems that share a common language. This exchange and interpretation happens in a way that preserves the originating context of that data.
In Part II, Ill delve more into the knowledge foundation that will be necessary for a shared metaverse or mirrorworld to exist.
){kind=link}