
Summary: Someone had to say it. In my opinion R is not the best way to learn data science and not the best way to practice it either. More and more large employers agree.
 Someone had to say it. I know this will be controversial and I welcome your comments but in my opinion R is not the best way to learn data science and not the best way to practice it either.
Someone had to say it. I know this will be controversial and I welcome your comments but in my opinion R is not the best way to learn data science and not the best way to practice it either.
Why Should We Care What Language You Use For Data Science
Here’s why this rises to the top of my thoughts. Recently my local Meetup had a very well attended hackathon to walk people through the Titanic dataset using R. The turnout was much higher than I expected which was gratifying. The result, not so much.
Not everyone in the audience was a beginner and many were folks who had probably been exposed to R at some point but were just out of practice. What struck me was how everyone was getting caught up in the syntax of each command, which is reasonably complex, and how many commands were necessary for example, to run the simplest decision tree.
Worse, it was as though they were learning a programming language and not the data science. There was little or no conversation or questioning around cleansing, prep, transforms, feature engineering, feature selection, model selection, and absolutely none about about hyperparameter tuning. In short, I am convinced that group left thinking that data science is about a programming language whose syntax they had to master, and not about the underlying major issues in preparing a worthwhile model.
Personal Experience
I have been a practicing data scientist with an emphasis on predictive modeling for about 16 years. I know enough R to be dangerous but when I want to build a model I reach for my SAS Enterprise Miner (could just as easily be SPSS, Rapid Miner or one of the other complete platforms).
The key issue is that I can clean, prep, transform, engineer features, select features, and run 10 or more model types simultaneously in less than 60 minutes (sometimes a lot less) and get back a nice display of the most accurate and robust model along with exportable code in my selection of languages.
The reason I can do that is because these advanced platforms now all have drag-and-drop visual workspaces into which I deploy and rapidly adjust each major element of the modeling process without ever touching a line of code.
Some Perspective
Through the 90’s (and actually well before) up through the early-2000’s if you studied data science in school you learned it on SAS or SPSS and in the base code for those packages that actually looks a lot like R. R wasn’t around then and for decades, SAS and SPSS recognized that the way to earn market share was to basically give away your product to colleges which used it to train. Those graduates would gravitate back to what they knew when they got out into the paying world.
In the mid-2000s these two platforms probably had at least an 80% market share and even today they have 36% and 17% respectively. This doesn’t even begin to reflect how dominant they are among the largest companies which is probably double these numbers.
By 2000 both these providers were offering advanced drag-and-drop platforms deemphasizing code. The major benefit, and it was huge, is that it let learners focus on the major elements of the process and understand what went on within each module or modeling technique without having to code it.
At the time, and still today, you will find SAS and SPSS purists who grew up coding who still maintain hand coding shops. It’s what you learned on that you carry forward into commercial life.
Then Why Is R Now So Popular
It’s about the money. R is open source and free. Although SAS and SPSS provided very deep discounts to colleges and universities each instructor had to pay several thousand dollars for the teaching version and each student had to pay a few hundred dollars (eventually there were student web based versions that were free but the instructor still had to pay).
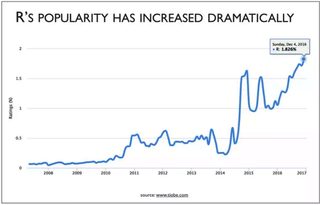 The first stable beta version of R was released in 2000. If you look at the TIOBE index of software popularity you’ll see that R adoption had its first uptick when Hadoop became open source (2007) and the interest in data science began to blossom. In 2014 it started a strong upward adoption curve along with the now exploding popularity of data science as a career and its wide ranging adoption as the teaching tool of choice.
The first stable beta version of R was released in 2000. If you look at the TIOBE index of software popularity you’ll see that R adoption had its first uptick when Hadoop became open source (2007) and the interest in data science began to blossom. In 2014 it started a strong upward adoption curve along with the now exploding popularity of data science as a career and its wide ranging adoption as the teaching tool of choice.
This was an economic boon for colleges but a step back for learners who now had to drop back into code mode. The argument is common that R’s syntax is at least easier than others but that begs the question that drag-and-drop is not only orders of magnitude easier but makes the modeling process much more logical and understandable.
Do Employers Care
Here you have to watch out for what appears to be a logical contradiction. Among those who do the hiring, the requirement that you know R (or Python) is strong and almost a go/no go factor. Why? Because those doing the hiring were very likely to have been taught in R and their going-in assumption is if I had to know it then so do you.
Here’s the catch. The largest employers, those with the most data scientists are rapidly reconsolidating on packages like SAS and SPSS with drag-and-drop. Gartner says this trend is particularly strong in the mid-size and large companies. You need to have at least 10 data scientists to break into this club and the average large company has more like 50.
We’re talking about the largest banks, mortgage lenders, insurance companies, retailers, brokerages, telecoms, utilities, manufacturers, transportation, and largest B2C services companies. Probably where you’d like to work unless you’re in Silicon Valley.
Once you have this many data scientists to manage you rapidly become concerned about efficiency and effectiveness. That’s a huge investment in high priced talent that needs to show a good ROI. Also, in this environment it’s likely that you have from several hundred to thousands of models that direct core business functions to develop and maintain.
It’s easy to see that if everyone is freelancing in R (or Python) that managing for consistency of approach and quality of outcome, not to mention the ability for collaboration around a single project is almost impossible. This is what’s driving the largest companies to literally force their data science staffs (I’m sure in a nice way) onto common platforms with drag-and-drop consistency and efficiency.
Gartner Won’t Even Rate You Unless You Have Drag-and-Drop
Gartner’s ‘Magic Quadrant for Advanced Analytic Platforms’ and Forrester’s report on ‘Enterprise Insight Platform Suites’ are both well regarded ratings of comprehensive data science platforms. The difference is that Gartner won’t even include you in their ranking unless you have a Visual Composition Framework (drag-and-drop).
As a result Tibco, which ranks second in the 2016 Forrester chart was not even considered by Gartner because it lacks this particular feature. Tibco users must work directly in code. Salford Systems was also rejected by Gartner for the same reason.
Gartner is very explicit that working in code is incompatible with the large organization need for quality, consistency, collaboration, speed, and ease of use. Large groups of data scientists freelancing in R and Python are very difficult to manage for these characteristics and that’s no longer acceptable.
Yes essentially all of these platforms do allow highly skilled data scientists to insert their own R or Python code into the modeling process. The fact is however that the need for algorithms not already embedded in the platform is rapidly declining. If you absolutely need something as exotic as XGboost you can import it. But only if that level of effort is warranted by a need for an unusually high level of accuracy. It’s now about efficiency and productivity.
Should You Be Giving Up R
If you are an established data scientist who learned in R then my hat’s off to you, don’t change a thing. If you’re in a smaller company with only a few colleagues you may be able to continue that way. If you move up into a larger company that wants you to use a standardized platform you shouldn’t have any trouble picking it up.
If you’re an early learner you are probably destined to use whatever tools your instructor demands. Increasingly that’s R. It’s not likely that you have a choice. It’s just that in the commercial world the need to actually code models in R is diminishing and your road map to a deep understanding of predictive modeling is probably more complex than it needs to be.
A Quick Note About Deep Learning
A quick note about deep learning. Most programming in Tensorflow is occuring in Python and if you know R you shouldn’t have a problem picking it up. Right now, to the best of my knowledge, there are no drag-and-drops for deep learning. For one thing, deep learning is still expensive to execute in terms of manpower, computing resource, and data acquisition. The need for those skills here in 2017 are still pretty limited, albeit likely to grow rapidly. Like core predictive modeling, when things are difficult I’m sure there’s someone out there focusing on making it easier and I bet that drag-and-drop is not far behind.
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist and commercial predictive modeler since 2001. He can be reached at:
{kind=link}