

Accuracy, F1, or TPR (a.k.a recall or sensitivity) are well-known and widely used metrics for evaluating and comparing the performance of machine learning based classification.
But, are we sure we evaluate classifiers’ performance correctly? Are they or others such as BACC (Balanced Accuracy), CK (Cohen’s Kappa), and MCC (Matthews Correlation Coefficient) robust?
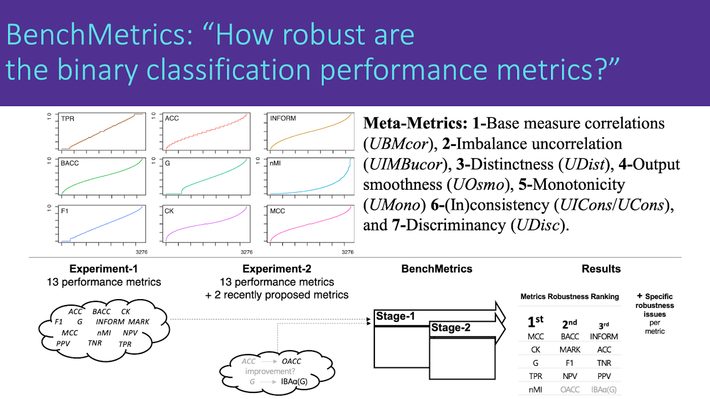
My latest research on benchmarking classification performance metrics (BenchMetrics) has just been published with SpringerNature in Neural Computing and Applications (SCI, Q1) journal.
Read here: https://rdcu.be/cvT7d
Highlights
- A benchmarking method is proposed for binary-classification performance metrics.
- Meta-metrics (metric about metric) and metric-space concepts are introduced.
- The method (BenchMetrics) tested 13 available and two recently proposed metrics.
- Critical issues are revealed in common metrics while MCC is the most robust one.
- Researchers should use MCC for performance evaluation, comparison, and reporting.
Abstract
This paper proposes a systematic benchmarking method called BenchMetrics to analyze and compare the robustness of binary-classification performance metrics based on the confusion matrix for a crisp classifier. BenchMetrics, introducing new concepts such as meta-metrics (metrics about metrics) and metric-space, has been tested on fifteen well-known metrics including Balanced Accuracy, Normalized Mutual Information, Cohen’s Kappa, and Matthews Correlation Coefficient (MCC), along with two recently proposed metrics, Optimized Precision and Index of Balanced Accuracy in the literature. The method formally presents a pseudo universal metric-space where all the permutations of confusion matrix elements yielding the same sample size are calculated. It evaluates the metrics and metric-spaces in a two-staged benchmark based on our proposed eighteen new criteria and finally ranks the metrics by aggregating the criteria results. The mathematical evaluation stage analyzes metrics’ equations, specific confusion matrix variations, and corresponding metric-spaces. The second stage, including seven novel meta-metrics, evaluates the robustness aspects of metric-spaces. We interpreted each benchmarking result and comparatively assessed the effectiveness of BenchMetrics with the limited comparison studies in the literature. The results of BenchMetrics have demonstrated that widely used metrics have significant robustness issues, and MCC is the most robust and recommended metric for binary-classification performance evaluation.
A critical question for the research community who wish to derive objective research outcomes
The chosen performance metric is the only instrument to determine which machine learning algorithm is the best.
So, for any specific classification problem domain in the literature:
Question: If we evaluate the performances of algorithms based on MCC will the comparisons and ranks change?
Answer: I think so. At least, we should try and see.
Question: But how?
Answer:
- First, try and see the BenchMetrics in action without any coding in the Code Ocean online platform.
- Second, use BenchMetrics open-source performance metrics benchmarking software … (API) for your custom experiments
- Third, refer to online data and materials for more information
Please, share the results with me.
Citation for the article:
Canbek, G., Taskaya Temizel, T. & Sagiroglu, S. BenchMetrics: a systematic benchmarking method for binary classification performance metrics. Neural Comput & Applic (2021). https://doi.org/10.1007/s00521-021-06103-6
{kind=link}