

I help lead a working group focused on personal knowledge graphs (PKGs). Lately, it’s functioned as a discussion and demo evaluation group for new technologies and how they might be used in a knowledge graph context.
Different individuals want to annotate different kinds of data. Some do a lot of research. For them, the need is to annotate the links and associated text (in a simple and ideally machine assisted way from research sources so that machines can help retrieve the right links later on and discover (or rediscover) related links. For others, making images more easily connectable, discoverable and retrievable is key. Margaret Warren’s ImageSnippets is designed for that purpose. Family history research is an example of the type of research that could benefit from image-friendly knowledge graphs.
The members of our working group have different preferences when it comes to their own personal notetaking and annotation. Gyuri Lagos, for example, recommends https://web.hypothes.is/ for taking existing text and adding annotation to it. Others simply want to make it easier for everyday users to create and publish RDF (standard subject-verb-object triplets), ontologies and make more use of linked data.
George Anadiotis and Ivo Velichkov are the editors of a forthcoming book described at https://personalknowledgegraphs.com/. One of the goals of the project is to publish the content as a knowledge graph. Making KG-friendly annotation a regular habit when notetaking and saving relevant links is another goal of the project.
What does a knowledge graph do?
Just to be clear on the key things a knowledge graph does, here’s a definition in contextual intelligence terms:
A knowledge graph facilitates a contextual web through large-scale integration and interoperation, including:
- Abstraction
- Synthesis
- Disambiguation
- Identification
If you don’t have clear context, you can’t really be sure of anything. But with enough machine readable context to empower higher volumes of the instance data, generalizable intelligence becomes possible.
Keep in mind that many people use the term “knowledge graph” in reference to graphs that can’t deliver large-scale integration, comparison or interoperation. In other words, they can’t be easily shared. Truly semantic graphs have this ease of sharability because they are intended for and designed to use standard means of abstraction, synthesis, disambiguation and identification.
Interpersonal versus personal
It’s sometimes helpful to make a distinction between “personal” (designed originally just for individual use) and interpersonal (designed for sharing). That distinction is essential when referring to or designing tools. A first step obviously targets individual use. Then sharing is a next step.
But a semantic standards-based knowledge graph architecture assumes web scalable collaboration by design. It’s an evolution of Web 1.0 designed to encourage sharing, discoverability and reuse out of the gate. In that sense, an “interpersonal knowledge graph” is from the Department of Redundancy Department.
Knowledge graphs are interpersonal by definition. They’re all about what data means in terms of its intent and context with the help of annotations so that better integration and reuse is possible. These dynamic models contexualize, disambiguate, abstract and generalize to build in reusability, discoverability and relevance.
How does this reusability effort work in practice? For reuse to be possible, iterative collaboration has to happen. Sometimes the collaboration is scheduled and more formal, but many other times it’s ad hoc.
For instance, one of the most popular resources to connect a knowledge graph to is Wikidata. How does Wikidata itself become more reusable? One way is through education efforts such as Wikidata Reuse Days, a series of one-hour/day collaboration sessions that take place in late March. Each session focuses on a different reuse topic, such as Wikidata in performing and visual arts, how to retrieve Wikidata’s data, or how to build websites or apps that use Wikidata.
The Wikimedia community records, transcribes and compiles the notes taken for each Reuse Days session and shares those publicly. Here’s an example of some raw notes on the 2022 OpenSanctions session that are publicly shared:
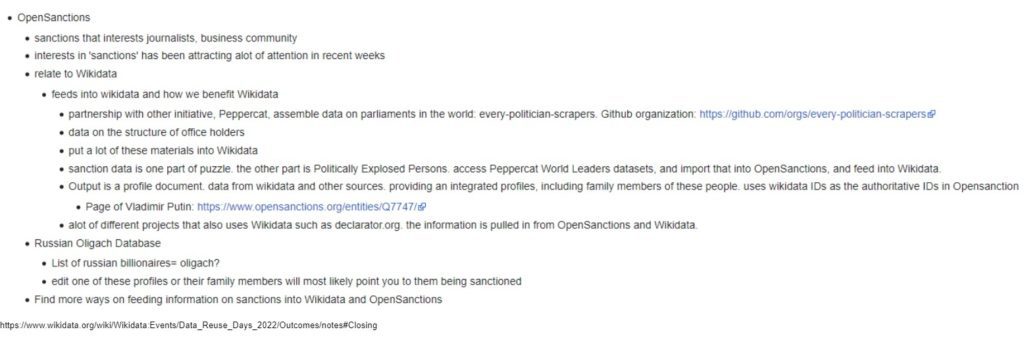
OpenSanctions is focused on sharing and bringing together (virtually or physically) related structured and less-structured data about sanctions including documented impacts, effectiveness, and profiles of leaders and oligarchs such as Putin and his associates who are the targets of sanctions.
How new learners can harness their PKG building habits in a business context
Much of the promise of PKGs is rooted in encouraging change of habits at the level of the individual. The individual then brings their good annotation and other contextualization habits into a collaborative work environment that will harness the power of contextual intelligence.
The complexity of that context varies. Supply networks can be among the most complex environments from a data sharing perspective.
Information supply and distribution can be as complex and problematic as physical goods or materials supply. Take the case of COVID-19 information and the challenge of getting valid information with the right context to the right place and time for whole country populations to gain sufficient and accurate understanding.
As Rabah Kamal of the Kaiser Family Foundation pointed out, the shortage of good, contextualized data that answered pivotal questions about the pandemic was absent or hard to discover. The spread of misinformation was one consequence.
Collecting, handling and managing data in an organic way, with knowledge graphs as the integration, sharing and distribution mechanism, merely extends and scales collaboration. In such a way, larger, more disparate data can be meaningfully brought together to bear on the problems at hand, including not only business challenges, but the most challenging issues society faces.
{kind=link}