
Hadoop and Spark are software frameworks from Apache Software Foundation that are used to manage ‘Big Data’. There is no particular threshold size which classifies data as “big data”, but in simple terms, it is a data set that is too high in volume, velocity or variety such that it cannot be stored and processed by a single computing system.
Big Data market is predicted to rise from $27 billion (in 2014) to $60 billion in 2020 which will give you an idea of why there is a growing demand for big data professionals. The increasing need for big data processing lies in the fact that 90% of the data was generated in the past 2 years and is expected to increase from 4.4 zb (in 2018) to 44 zb in 2020. Let’s see what Hadoop is and how it manages such astronomical volumes of data.
A. What is Hadoop?
Hadoop is a software framework which is used to store and process Big Data. It breaks down large datasets into smaller pieces and processes them parallelly which saves time. It is a disk-based storage and processing system.
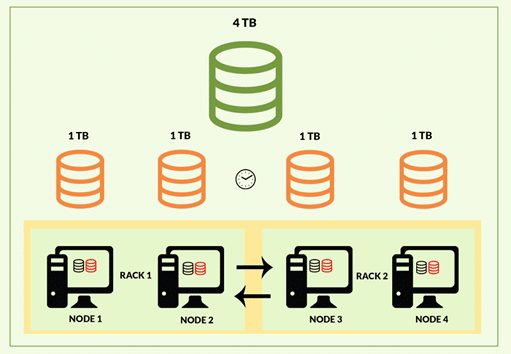
It can scale from a single server to thousands of machines which increase its storage capacity and makes computation of data faster.
For eg: A single machine might not be able to handle 100 gb of data. But if we split this data into 10 gb partitions, then 10 machines can parallelly process them.
In Hadoop, multiple machines connected to each other work collectively as a single system.
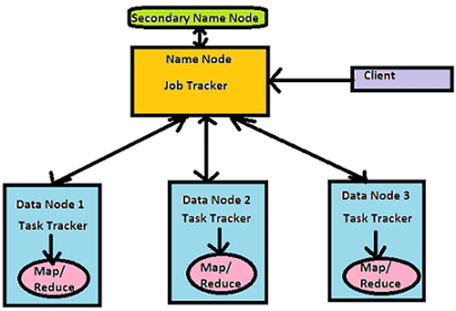
There are two core components of Hadoop: HDFS and MapReduce
1.Hadoop Distributed File System (HDFS) –
It is the storage system of Hadoop.
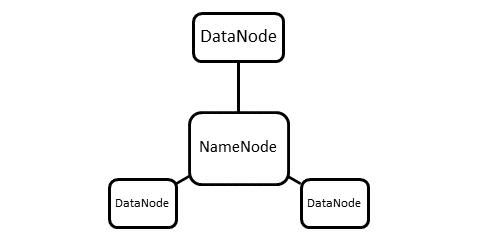
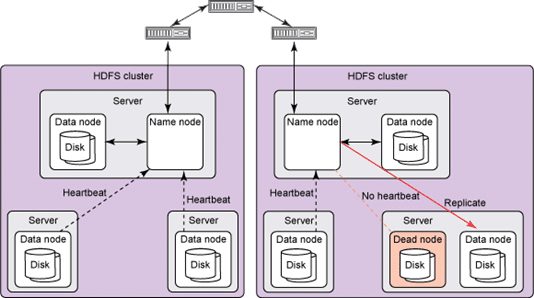
It has a master-slave architecture, which consists of a single master server called ‘NameNode’ and multiple slaves called ‘DataNodes’. A NameNode and its DataNodes form a cluster. There can be multiple clusters in HDFS.
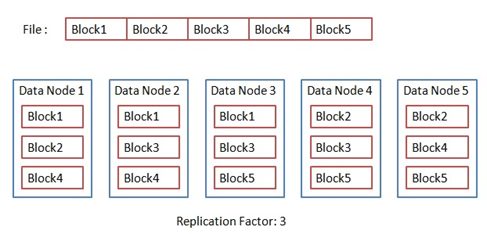
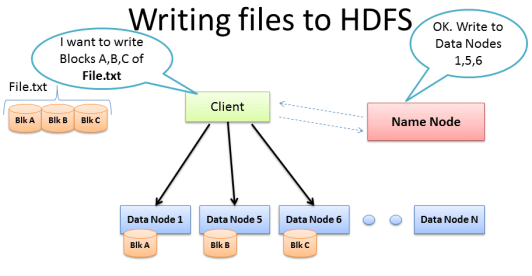
- A file is split into one or more blocks and these blocks are stored in a set of DataNodes.
- NameNode maintains the data that provides information about DataNodes like which block is mapped to which DataNode (this information is called metadata) and also executes operations like the renaming of files.
- DataNodes store the actual data and also perform tasks like replication and deletion of data as instructed by NameNode. DataNodes also communicate with each other.
- Client is an interface that communicates with NameNode for metadata and DataNodes for read and writes operations.
There is a Secondary NameNode as well which manages the metadata for NameNode.
2. MapReduce
It is a programming framework that is used to process Big Data.
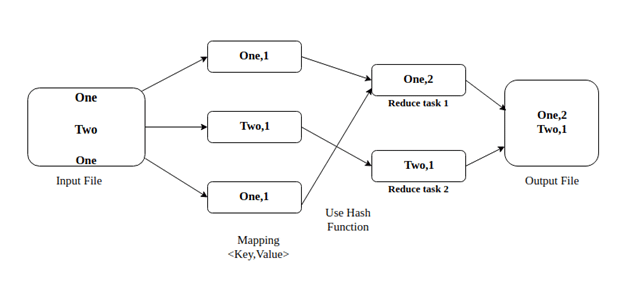
It splits the large data set into smaller chunks which the ‘map’ task processes parallelly and produces key-value pairs as output. The output of Mapper is input for ‘reduce’ task in such a way that all key-value pairs with the same key goes to same Reducer. The Reducer then aggregates the set of key-value pairs into a smaller set of key-value pairs which is the final output.
MapReduce Architecture
It has a master-slave architecture which consists of a single master server called ‘Job Tracker’ and a ‘Task Tracker’ per slave node that runs along DataNode.
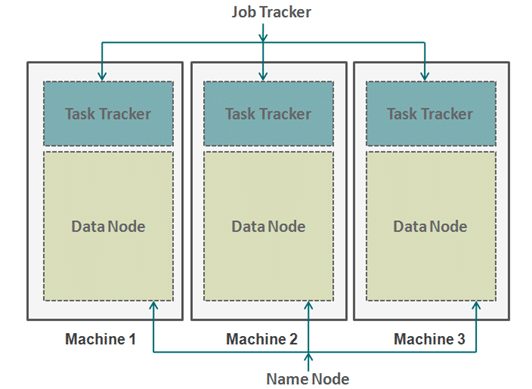
- Job Tracker is responsible for scheduling the tasks on slaves, monitoring them and re-executing the failed tasks.
- Task Tracker executes the tasks as directed by master.
- Task Tracker returns the status of the tasks to job tracker.
The DataNodes in HDFS and Task Tracker in MapReduce periodically send heartbeat messages to their masters indicating that it is alive.
B. What is Spark?
Spark is a software framework for processing Big Data. It uses in-memory processing for processing Big Data which makes it highly faster. It is also a distributed data processing engine. It does not have its own storage system like Hadoop has, so it requires a storage platform like HDFS. It can be run on local mode (Windows or UNIX based system) or cluster mode. It supports programming languages like Java, Scala, Python, and R.
Spark Architecture
Spark also follows master-slave architecture. Apart from the master node and slave node, it has a cluster manager that acquires and allocates resources required to run a task.
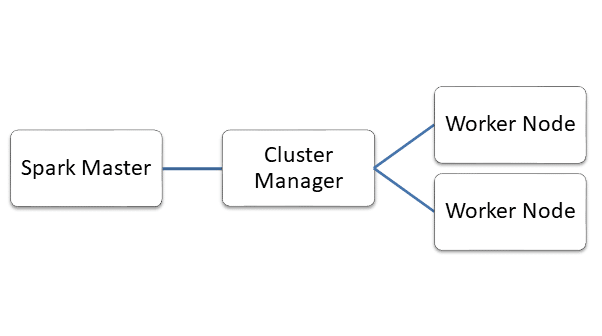
- In master node, there is a ‘driver program’ which is responsible for creating ‘Spark Context’.
Spark Context acts as a gateway for the execution of Spark application.
- The Spark Context breaks a job into multiple tasks and distributes them to slave nodes called ‘Worker Nodes’.
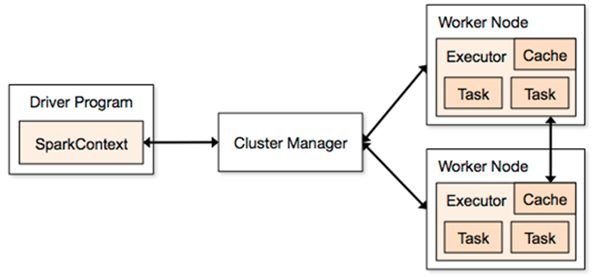
- Inside the worker nodes, there are executors who execute the tasks.
- The driver program and cluster manager communicate with each other for the allocation of resources. The cluster manager launches the executors. Then the driver sends the tasks to executors and monitors their end to end execution.
- If we increase the number of worker nodes, the job will be divided into more partitions and hence execution will be faster.
Data Representations in Spark : RDD / Dataframe / Dataset
Data can be represented in three ways in Spark which are RDD, Dataframe, and Dataset. For each of them, there is a different API.
1. Resilient Distributed Dataset (RDD)
RDD is a collection of partitioned data.
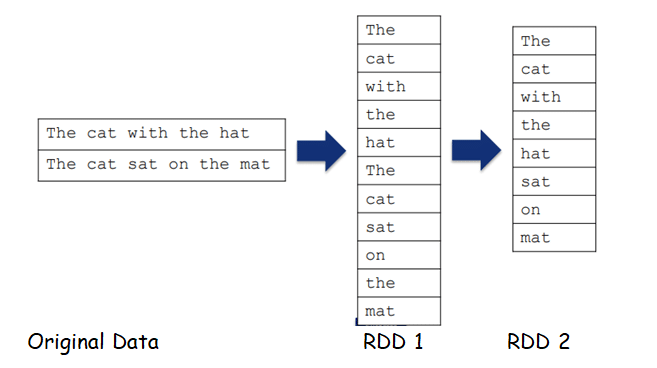
The data in an RDD is split into chunks that may be computed among multiple nodes in a cluster.
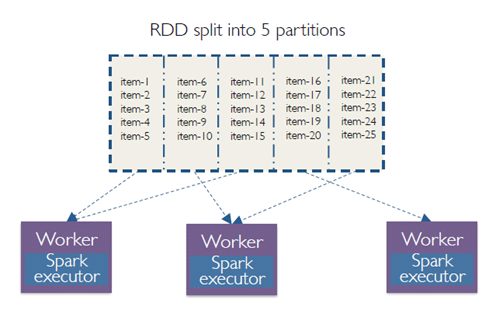
If a node fails, the cluster manager will assign that task to another node, thus, making RDD’s fault tolerant. Once an RDD is created, its state cannot be modified, thus it is immutable. But we can apply various transformations on an RDD to create another RDD. Also, we can apply actions that perform computations and send the result back to the driver.
2. Dataframe
It can be termed as dataset organized in named columns. It is similar to a table in a relational database.
It is also immutable like RDD. Its rows have a particular schema. We can perform SQL like queries on a data frame. It can be used only for structured or semi-structured data.
3. Dataset
It is a combination of RDD and dataframe. It is an extension of data frame API, a major difference is that datasets are strongly typed. It can be created from JVM objects and can be manipulated using transformations. It can be used on both structured and unstructured data.
Spark Ecosystem
Apache Spark has some components which make it more powerful. They are explained further.
1. Spark Core
It contains the basic functionality of Spark. All other libraries in Spark are built on top of it. It supports RDD as its data representation. Its responsibilities include task scheduling, fault recovery, memory management, and distribution of jobs across worker nodes, etc.
2. Spark Streaming
It is used to process data which streams in real time. Eg: You search for a product and immediately start getting advertisements about it on social media platforms.
3. Spark SQL
It supports using SQL queries. It supports data to be represented in the form of data frames and dataset.
4. Spark MLlib
It is used to perform machine learning algorithms on the data.
5. Spark GraphX
It allows data visualization in the form of the graph. It also provides various operators for manipulating graphs, combine graphs with RDDs and a library for common graph algorithms.
.
C. Hadoop vs Spark: A Comparison
1. Speed
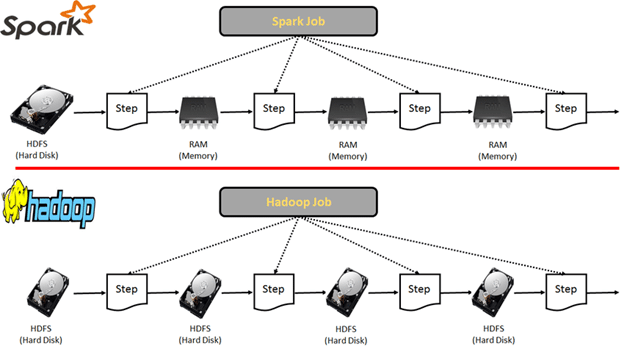
In Hadoop, all the data is stored in Hard disks of DataNodes. Whenever the data is required for processing, it is read from hard disk and saved into the hard disk. Moreover, the data is read sequentially from the beginning, so the entire dataset would be read from the disk, not just the portion that is required.
While in Spark, the data is stored in RAM which makes reading and writing data highly faster. Spark is 100 times faster than Hadoop.
Suppose there is a task that requires a chain of jobs, where the output of first is input for second and so on. In MapReduce, the data is fetched from disk and output is stored to disk. Then for the second job, the output of first is fetched from disk and then saved into the disk and so on. Reading and writing data from the disk repeatedly for a task will take a lot of time.
But in Spark, it will initially read from disk and save the output in RAM, so in the second job, the input is read from RAM and output stored in RAM and so on. This reduces the time taken by Spark as compared to MapReduce.
2. Data Processing
Hadoop cannot be used for providing immediate results but is highly suitable for data collected over a period of time. Since it is more suitable for batch processing, it can be used for output forecasting, supply planning, predicting the consumer tastes, research, identify patterns in data, calculating aggregates over a period of time etc.
Spark can be used both for both batch processing and real-time processing of data. Even if data is stored in a disk, Spark performs faster. It is suitable for real-time analysis like trending hashtags on Twitter, digital marketing, stock market analysis, fraud detection, etc.
3. Cost
Both Hadoop and Spark are open source Apache products, so they are free software. But they have hardware costs associated with them. They are designed to run on low cost, easy to use hardware. Since Hadoop is disk-based, it requires faster disks while Spark can work with standard disks but requires a large amount of RAM, thus it costs more.
4. Simplicity
Spark programming framework is much simpler than MapReduce. It’s APIs in Java, Python, Scala, and R are user-friendly. But Hadoop also has various components which don’t require complex MapReduce programming like Hive, Pig, Sqoop, HBase which are very easy to use.
5. Fault Tolerance
In Hadoop, the data is divided into blocks which are stored in DataNodes. Those blocks have duplicate copies stored in other nodes with the default replication factor as 3. So, if a node goes down, the data can be retrieved from other nodes. This way, Hadoop achieves fault tolerance.
Spark follows a Directed Acyclic Graph (DAG) which is a set of vertices and edges where vertices represent RDDs and edges represents the operations to be applied on RDDs. In this way, a graph of consecutive computation stages is formed.
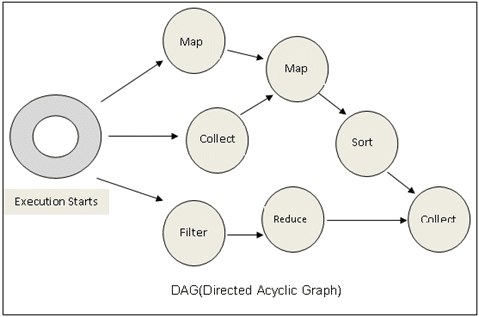
Spark builds a lineage which remembers the RDDs involved in computation and its dependent RDDs.
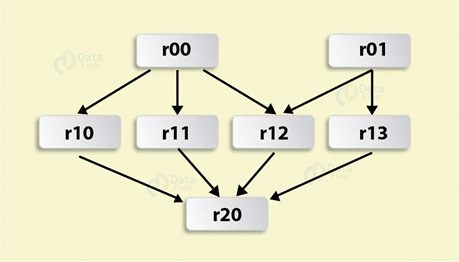
So if a node fails, the task will be assigned to another node based on DAG. Since RDDs are immutable, so if any RDD partition is lost, it can be recomputed from the original dataset using lineage graph. This way Spark achieves fault tolerance.
But for processes that are streaming in real time, a more efficient way to achieve fault tolerance is by saving the state of spark application in reliable storage. This is called checkpointing. Spark can recover the data from the checkpoint directory when a node crashes and continue the process.
6. Scalability
Hadoop has its own storage system HDFS while Spark requires a storage system like HDFS which can be easily grown by adding more nodes. They both are highly scalable as HDFS storage can go more than hundreds of thousands of nodes. Spark can also integrate with other storage systems like S3 bucket.
It is predicted that 75% of Fortune 2000 companies will have a 1000 node Hadoop cluster.
Facebook has 2 major Hadoop clusters with one of them being an 1100 machine cluster with 8800 cores and 12 PB raw storage.
Yahoo has one of the biggest Hadoop clusters with 4500 nodes. It has more than 100,000 CPUs in greater than 40,000 computers running Hadoop.
Source: https://wiki.apache.org/hadoop/PoweredBy
7. Security
Spark only supports authentication via shared secret password authentication.
While Hadoop supports Kerberos network authentication protocol and HDFS also supports Access Control Lists (ACLs) permissions. It provides service level authorization which is the initial authorization mechanism to ensure the client has the right permissions before connecting to Hadoop service.
So Spark is little less secure than Hadoop. But if it is integrated with Hadoop, then it can use its security features.
8. Programming Languages
Hadoop MapReduce supports only Java while Spark programs can be written in Java, Scala, Python and R. With the increasing popularity of simple programming language like Python, Spark is more coder-friendly.
Conclusion
Hadoop and Spark make an umbrella of components which are complementary to each other. Spark brings speed and Hadoop brings one of the most scalable and cheap storage systems which makes them work together. They have a lot of components under their umbrella which has no well-known counterpart. Spark has a popular machine learning library while Hadoop has ETL oriented tools. However, Hadoop MapReduce can be replaced in the future by Spark but since it is less costly, it might not get obsolete.
Learn Big Data Analytics using Spark from here
{kind=link}