
Summary: The largest companies utilizing the most data science resources are moving rapidly toward more integrated advanced analytic platforms. The features they are demanding are evolving to promote speed, simplicity, quality, and manageability. This has some interesting implications for open source R and Python widely taught in schools but significantly less necessary with these more sophisticated platforms.
 We continue to be dazzled, and perhaps rightly so, by the advances in deep learning and question answering machines like Watson. And while these are fun to read about and some of the apps that incorporate them can be both handy and addictive, they cause us to take our eye off the bigger ball. The bigger ball in this case is what are the largest non-tech companies using for data science? What are their processes? What are their best practices?
We continue to be dazzled, and perhaps rightly so, by the advances in deep learning and question answering machines like Watson. And while these are fun to read about and some of the apps that incorporate them can be both handy and addictive, they cause us to take our eye off the bigger ball. The bigger ball in this case is what are the largest non-tech companies using for data science? What are their processes? What are their best practices?
This foundational practice of data science may seem pretty common place, filled with scoring models, numerical forecasts, geospatial analytics, and clustering and association analysis of products, customers and click streams. The reality is though that these largest data-science-using companies (Gartner says you need to have 10 to 50 or more data scientists of varying skills to be in this category) are the ones paying to keep our profession alive.
There are at least 15 or 20 major advanced analytic platforms, another 20 or so in the tier right below that, and probably another 20 specialty platforms (exclusively blending, prepping, MDM, and the like) all of which are reasonably financially viable. Count on the fact that it’s the Fortune 500 or the International 1000 that’s paying the lion’s share of these annual fees from which we all benefit.
With a little back-of-envelope calculation I figure it’s about $1 million for each three or four data scientists, counting fringes, support, and yes analytic platform subscription and support fees. That would put the cost of maintaining 50 data scientists up around $13 to $16 million per year. You can be sure at those prices they are returning more than that in financial benefit.
Who are these ‘whales’ that all our vendors would like to capture. They’re the largest banks, mortgage lenders, insurance companies, retailers, brokerages, telecoms, utilities, manufacturers, transportation, and services companies with the largest B2C relationships.
Interestingly, these are the same companies that have the largest concentrations of Citizen Data Scientists. These are the cadres of analysts and managers who lack specific data science training but increasingly want access to the data and the tools so they can figure out at least some of these answers for themselves.
So while we’ve been reading about the eye-candy in AI, the successful advanced analytic platforms and their major enabling competitors have been keeping an eye on what these key customers want. As it turns out, what they want and need has been changing.
What’s Changed in the Requirements for Advanced Analytic Platforms?
The period that we’re entering, when the majority of large firms are maturing in their use of advanced analytics is a little like the mid 90’s and the migration from MRPs to ERPs. In larger organizations there are undeniable benefits to centralizing on one or a few platform providers (single vendor shop or best of breed) provided those platforms have reached a level of maturity themselves to warrant that.
- TCO is lower.
- Support for and from IT and the analytic staff is simplified.
- Hiring for data scientists is more focused.
- Collaboration is easier.
And in this period as in MRP/ERP transition, the selection of a particular vendor on which to standardize conveys a long term benefit for buyer as well as seller. As with ERP switching, the pain and cost of abandoning a current vendor will be high so getting in first is strategically important. Indeed, Gartner confirms this is the fastest growing segment of the analytics market.
The Rankings
Gartner has for several years maintained a Magic Quadrant for Advanced Analytic Platforms that offers one perspective. Another entrant is Forrester’s relatively new category of “Enterprise Insight Platform Suites”. These two well regarded industry observers see this similarly but in this article we’ll focus on some of the key differences that can be enlightening as well as how buyer requirements are changing.
Seeing which vendors are ranked where by each of these reviewers will help us focus on the differences.
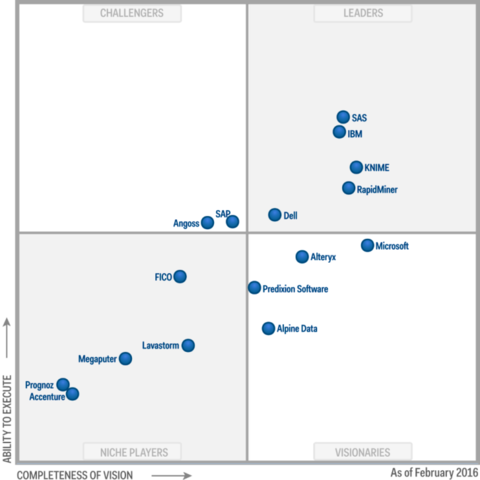
Gartner Magic Quadrant for Advanced Analytics Platforms
Forrester Wave Enterprise Insight Platform Suites (Dec. 2016)
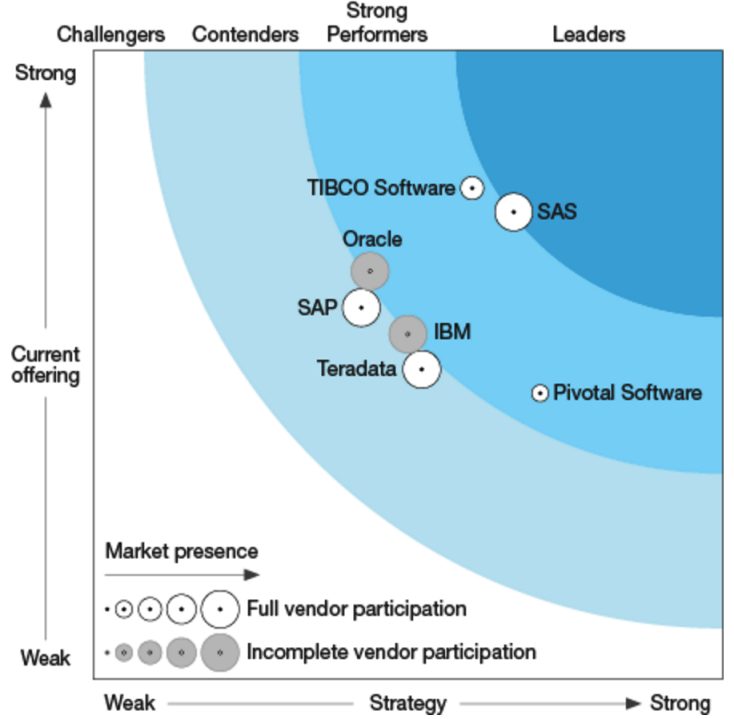
Both Gartner and Forrester take a holistic approach to these platforms. Gartner focuses on these critical capabilities (see the report for more detail). Forrester’s schema is a little less granular but fundamentally the same with a few exceptions.
- Data Access. The focus is on broad access, connectivity, blending, and automation. In this category they also put binning, smoothing, feature generation, and geospatial.
- Data Preparation and Exploration: Includes basic statistics, autocharting, geo-mapping, OLAP, clustering and affinity analysis.
- Advanced Modelling: Predictive analytics, optimization, and simulation.
- Visual Composition Framework (VCF): Drag-and-drop code modules allowing for fast visual construction of inputs, models, and outputs.
- Automation: Large companies are now literal “Model Factories” and need automated routines to iteratively search for the best model from a set of candidate models.
- Delivery, Integration & Deployment: Easily move analytics from this development platform to the production environment.
- Platform and Project Management: Provide data science oversight and management capability so that DS Managers can monitor work in process for quality and efficiency, and monitor existing models for refresh and compliance issues.
- Performance and Scalability: In response to increasing volumes of data and the competitive requirement to respond quickly the full cycle must deliver quickly with the level of accuracy appropriate for the opportunity.
- User Experience: For both data scientists and the growing cadre of Citizen Data Scientists. On the one hand the systems must provide for sophisticated data science and for the lesser trained, be easy to learn and use. In the latter case this includes on-screen instruction, wizards, and contextual guidance.
- Collaboration: As data science and the management of the data science process increasingly becomes a team effort.
- Leverage and Productivity: Accelerators, templates, predefined solution roadmaps for repetitive tasks like market basket analysis, churn, and failure prediction.
Managing for Data Science Efficiency and Quality Now Comes First
Just a few years ago, data scientists would not have much cared about many of the characteristics above that are now labeled critical. In smaller organizations (Gartner’s definition is 3 to 9 data scientists) you may be able to forgo some of these. But technology adoption follows a well-worn path, and what is important to the biggest users will rapidly become important to smaller users.
The key is to understand that many of these characteristics now enable seeing data science and predictive analytics as a process to be managed for efficiency and quality.
Open Source R and Python Begin to Fall Back in Importance
In the list above pay particular attention to Gartner’s call out of the Visual Composition Framework (drag-and-drop elements of code) as a critical requirement. Forrester does not have this requirement. As a result Tibco, which ranks second in the Forrester chart was not even considered by Gartner because it lacks this particular feature. Tibco users must work directly in code. Salford Systems was also rejected by Gartner for the same reason.
Gartner is very explicit that working in code is incompatible with the large organization need for quality, consistency, collaboration, speed, and ease of use. Large groups of data scientists freelancing in R and Python are very difficult to manage for these characteristics and that’s no longer acceptable.
Yes essentially all of these platforms do allow highly skilled data scientists to insert their own R or Python model code into the modeling process without violating the collaborative and transparency requirements. The fact is however that the need for algorithms not already embedded in the platform is rapidly declining. If you absolutely need something as exotic as XGboost you can import it. But only if that level of effort is warranted by a need for an unusually high level of accuracy. It’s now about efficiency and productivity.
On Premise Becomes More Important
Interestingly, both studies require that the platform be able to run on prem. Accessed data may be in the cloud but the implication is that the capabilities of cloud-based analytic offerings like Azure don’t make the cut when compared to these requirements.
Citizen Data Scientist Appear to Create Contradictory Goals
Both studies acknowledge that Citizen Data Scientists are a fact of life and that they need to be able to use at least some of these substantial capabilities. Note the emphasis on ease of use, user experience, and the presence of on screen instruction, wizards, and contextual guidance.
Interestingly, there are several platforms like PurePredictive, Data Robot, and BigML that are wizard based (as opposed to drag-and-drop VCF). Gartner calls out that these wizard-based approaches are considered inferior in their study. While they make it easy for the Citizen Data Scientist they lack the flexibility and transparency needed by trained data scientists.
The result is that these advanced analytic platforms are required to respond to two different user groups with different needs and capabilities. It seems that many have actually managed to do this.
As the use of predictive analytics matures and is more widely adopted some of these trends may seem to commoditize it use. In some respects this may be true. However using these capabilities as efficiently and productively as possible to create the greatest and fastest competitive advantage was always the point. As data science organizations in large companies become larger, these elements are both inevitable and appropriate.
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist and commercial predictive modeler since 2001. He can be reached at:
{kind=link}