
In this third part of the solution, we discuss how to implement a GraphRAG. This implementation needs an understanding of Langchain which we shall also discuss. As we have discussed, the combination of Knowledge Graphs and vector databases brings the ability to manage both structured and unstructured information. To implement the end to end solution, we use Langchain.
The LangChain framework consists of several components designed to streamline the development of applications using large language models (LLMs).
Model I/O: These components are responsible for formatting and managing inputs and outputs for language models. This includes handling prompts and managing different model interfaces like chat models and text completion models.
Sample Model I/O components include:
- Prompts: They format user input into structured queries that guide the generation process of LLMs.
- Chat Models: Designed for conversation-based interactions, these models handle input as a sequence of chat messages and return responses in a similar format.
- LLMs: Traditional language models that take plain text as input and return text as output, suitable for straightforward query-response setups
Retrieval: This part of the framework handles the interfacing with application-specific data. It includes components like document loaders which fetch data, text splitters to adapt documents for specific uses, embedding models to generate text vector representations for natural language search, and retrievers that find documents based on unstructured queries
Sample Retrieval components include
- Document Loaders: These components load data from various sources to be used by the application, organizing it into usable formats.
- Text Splitters: They split documents into smaller segments, making them more manageable for processing by LLMs.
- Embedding Models: Generate vector representations of text, facilitating the search and retrieval of information based on semantic similarities.
- Retrievers: Fetch relevant documents or data in response to unstructured queries, using the embeddings created by the models
Composition: These are higher-level components that combine different systems or LangChain primitives. This includes tools which allow an LLM to interact with external systems, agents which select tools based on directives, and chains, which are compositions of other components to perform specific tasks
Sample Composition components include
- Tools: Interfaces that allow LLMs to interact with external systems or databases, enhancing their functionality.
- Agents: Decision-making components that select and manage the use of various tools based on the application’s needs.
- Chains: Configurable sequences of operations that link different tools and models to perform complex tasks
Additional Components: LangChain also includes elements for managing application memory to persist state across sessions, and callbacks for logging and streaming the steps in a process.
Each component is designed to be modular, allowing developers to use them in isolation or integrate them into larger systems. This flexibility makes LangChain a versatile tool for building sophisticated applications powered by advanced language models.
To build an end-to-end application using large language models (LLMs) with the LangChain framework, developers typically follow a structured process that leverages various components of LangChain to handle different aspects of the application. Here’s a generalized step-by-step guide:
- Defining the Use Case and Requirements: Identify what you need the LLM application to do, including the types of interactions and the expected outputs.
- Model Selection and Integration: Choose the appropriate LLM (like GPT or a domain-specific model) based on your needs.
- Input/Output Management: Utilize LangChain’s Model I/O components to format and manage the inputs and outputs of your LLM.
- Data Retrieval and Management: Use document loaders to fetch data, embedding models to create searchable text vectors, and retrievers to find relevant information based on queries.
- Composition of Components: Combine different LangChain components like tools, agents, and chains to build more complex interactions. For instance, you might use an agent to decide dynamically which tools to use based on the user’s input or the context provided by previous interactions
By following these steps, developers can leverage the powerful components of LangChain to build robust, scalable, and effective LLM applications tailored to specific needs. This approach allows for flexibility in integrating various data sources, LLM providers, and external systems, ensuring that the final application is well-suited to the intended tasks and user expectations.
With this understanding, lets now explore how the GraphRAG solution can be implemented using neo4j
- In the data ingestion phase, we use the langchain loaders to fetch and split the documents
- The user’s question is directed at RAG retriever. This retriever employs keyword and vector searches to search through unstructured text data and combines it with the information it collects from the knowledge graph.
- The collected data from these sources is fed into an LLM to generate and deliver the final answer.
- You could also implement a Graph only search
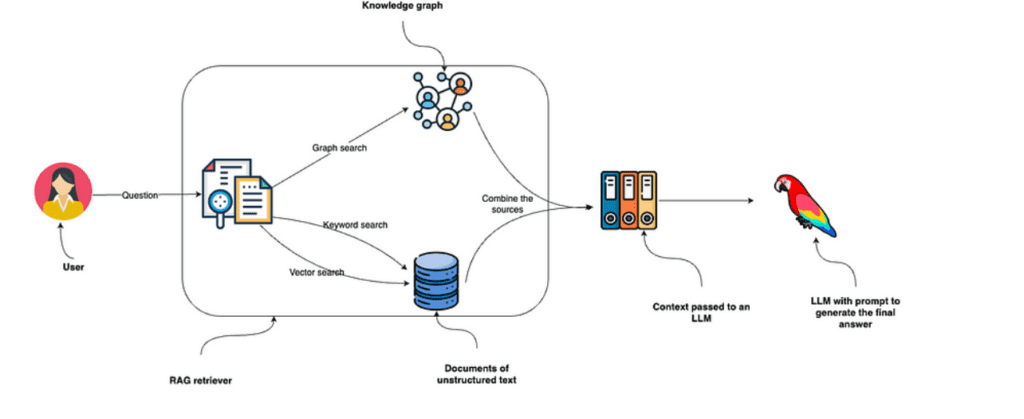
Image source: Enhancing the Accuracy of RAG Applications With Knowledge Graphs
The code is available on GitHub.
References:
Tomaz Bratanic
Enhancing the Accuracy of RAG Applications With Knowledge Graphs
The code is available on GitHub.
Langchain image source: LangChain framework