

Earlier in the fall, Charles Hoffman joined our non-profit Dataworthy Collective (DC) that focuses on best practices in trusted knowledge graph development. Hoffman is a CPA, consultant and former PwC auditor who works with clients who use the Extensible Business Reporting Language (XBRL).
For those who don’t know the history of standard digital business reporting, the Securities and Exchange Commission (SEC) in the US, the European Single Market Regulator (ESMA) in the European Union and other regulatory bodies in India, Singapore, the UK and even Ukraine, to name a few, require publicly held companies to issue their financials using the XBRL standard.
XBRL for these reasons can be considered a success. Hoffman, however, does point out that standard business reporting needs to go well beyond XBRL, which provides a standard syntax and some high-level taxonomic semantics, but lacks other essential logic. XBRL, first released in 2003, hasn’t been gone enough for businesspeople who aren’t technologists to take full advantage of it.
To make XBRL-compliant systems user friendly, it’s important for there to be logical consistency all the way down to the fully networked document object level, where the users are.
For this reason, Hoffman is working with DC co-founder Pete Rivett at the Object Management Group on an adjacent, document-level standard called the Standard Business Report Model (SBRM). The goal of SBRM is to logically contextualize business documents so that they’re interoperable. When they’re logically consistent and governed, spreadsheets could “talk to each other”, Hoffman says.
Graph-based data centricity: The path to zero-copy integration, interoperability and trust
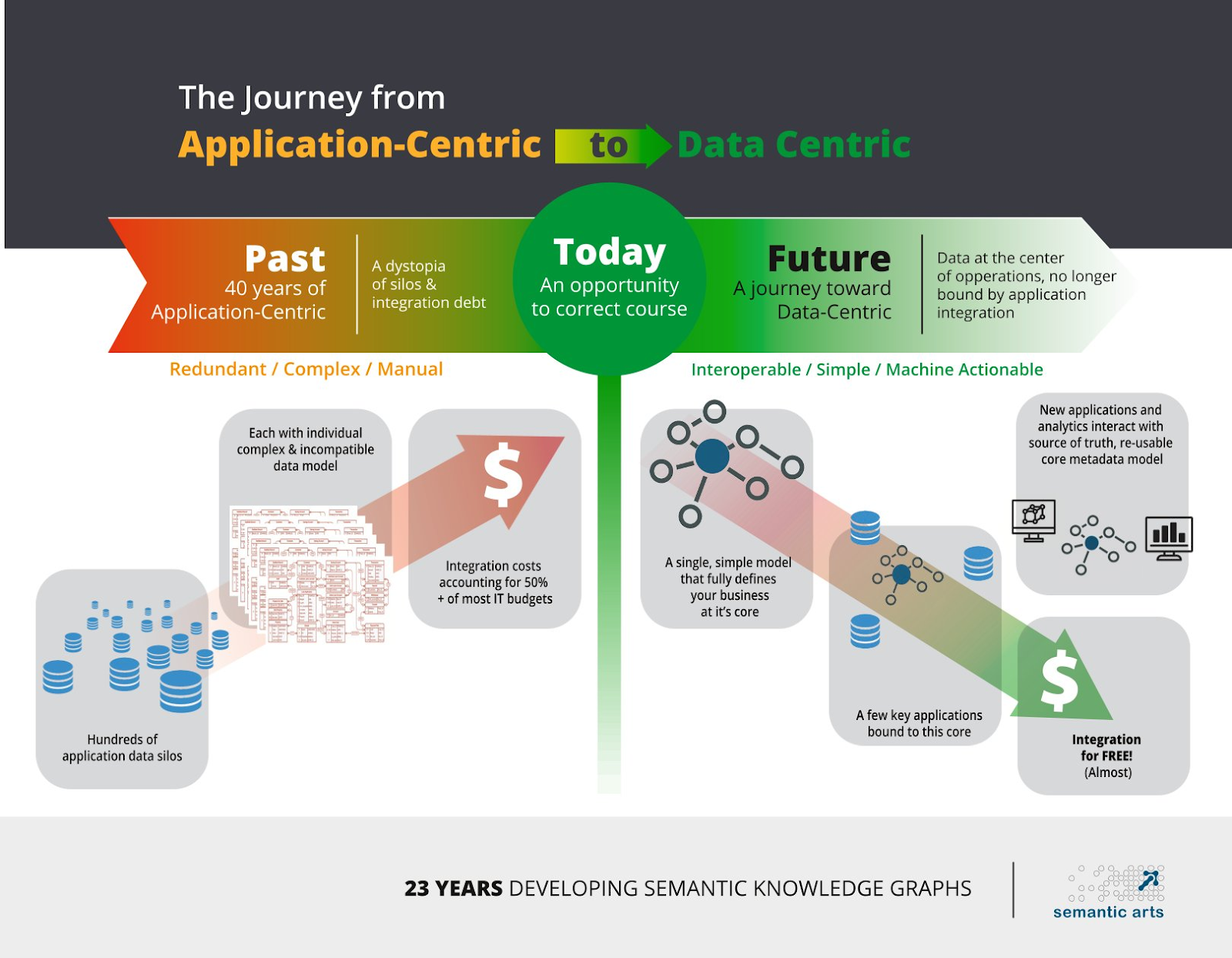
The SBRM effort is aligned with the concept of data centricity articulated by Dave McComb, president of enterprise knowledge graph consultancy Semantic Arts. McComb points out in his books Software Wasteland and The Data-Centric Revolution that each application in a typical, technical debt generating application-centric architecture has its own data model.
Each of those data models lacks alignment with the other models it needs to co-exist with. That lack of alignment constitutes more technical debt. Hoffman reminds us of Total Quality Management’s 1-10-100 Rule: Preventing each error will only set you back $1, by comparison with $10 per error for remediation and $100 of inaction per year.
Much better if you can design up front to avoid technical debt later. Data-centric graph architecture enables this kind of prevention.
In order to share data across systems in a trusted way, the model must be logically consistent from upper ontology, to domain ontology, to domain object,, exposed in a knowledge graph and expressed as contextualizing data so that it can be reused. Once that happens, the lines of code in each application that’s now using the knowledge graph’s declaration and rule logic can be reduced by 85 percent.
To reduce the risk of generating more integration complexity, it’s essential that the graph model be fully abstracted and at the same time articulated in a consistent way. Otherwise, you won’t get the complete benefit of graph technology.
Examples of commercial data-centric graph architecture
Modern graphs can be powerful in systems that are architected in a fully data-centric manner. Dave Duggal, founder of interoperation and automation platform EnterpriseWeb, points out that EWEB’s architecture, for example, has all graphs up and down. But when processing, EWEB just sees all of these as a single, unitary graph.
In essence, EWEB has a hypergraph architecture that’s agent managed for enterprise-wide automation purposes. (See {link to} Dave Duggal interview on DSC for more information.) Many telecom carriers use EWEB for software-defined network creation and configuration changes.
Other modern, end-to-end data-centric graph architectures that come to mind include these:
- Eccenca: Creates a business-wide, knowledge graph-based digital twin, allowing manufacturers, for example, to make siloed data for all product categories findable, accessible, interoperable and reusable (FAIR). Currently in use at Radio Frequency Systems (RFS).
- Graphmetrix: Allows zero-copy PDF sharing, version control and management across supply networks with the help of Solid decentralized storage pods and a hypergraph architecture. Currently designed for use in the construction industry supply chain.
- Iotics: Installs knowledge subgraphs (a.k.a., digital twins) at each sensor node in an IoT network for ESG monitoring and compliance purposes, then uses agents to manage the messaging from nodes to a lightweight central graph, as well as from the central graph to consumers. In use at Portsmouth International Ports.
How to think about the machine-readable logic required for document object-level data sharing
Hoffman has thought long and hard about what’s necessary to bring spreadsheets to life and make their contents sharable in a data centric way. In a draft brief entitled “Special Purpose Logical Spreadsheet for Accountants,” Hoffman ponders the relationship between the key elements of control, rules, quality, repeatable process and automation:
- Without control, there can be no automation, no repeatable processes.
- Rules provide control.
- Control leads to high quality.
- High quality leads to effective automation.
- Machine-readable rules are used to control systems.
- Accountants manage the rules.
This kind of bridge building between businesspeople and technologists is long overdue. I and others at the DC are looking forward to learning more about the SBRM effort and how better business/technology collaboration can achieve this next level of automation.
{kind=link}