

Today, one of the most popular tasks in Data Science is processing information presented in the text form. Exactly this is text representation in the form of mathematical equations, formulas, paradigms, patterns in order to understand the text semantics (content) for its further processing: classification, fragmentation, etc. The general area which solves the described problems is called Natural Language Processing (NLP).
Among the tasks that Natural Language Processing solves the most important ones are:
- machine translation is the first classic task assigned to the developers of NLP-technologies (it is necessary to note that it is not yet solved at the necessary level of quality for today);
- grammar and spell checking – as a conclusion of the first task;
- text classification – definitions of text semantics for further processing (one of the most popular tasks to date);
- named-entity recognition (NER) – definition and selection of entities with a predefined meaning (used to filter text information and understand general semantics);
- summarization – the text generalization to a simplified version form (re-interpretation the content of the texts);
- text generation – one of the tasks that are used to build AI-systems;
- topic modeling – technique for extracting hidden topics from large text volumes.
It is important to note that all these tasks in the modern and actual Natural Language Processing are often integrated into one, in creating interactive AI-systems: chat-bots. It is an environment (system) that helps to combine human requests with the software.
In general, the operation of systems using NLP can be described as the next pipeline:
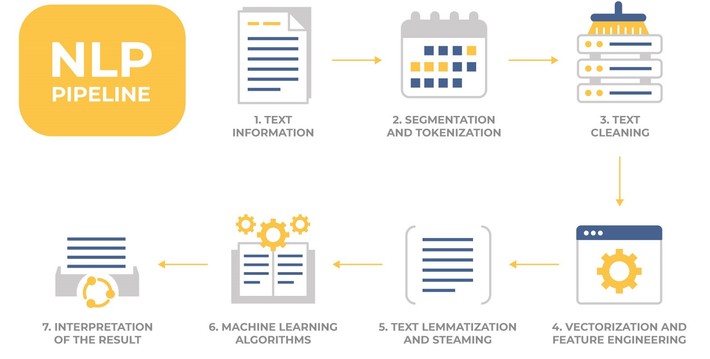
- Enter the text (or sound converted to text)
- Segmentation of text into components (segmentation and tokenization).
- Text Cleaning (filtering from “garbage”) – removal of unnecessary elements.
- Text Vectorization and Feature engineering.
- Lemmatization and Steaming – reducing inflections for words.
- Using Machine Learning algorithms and methods for training models.
- Interpretation of the result.
In this article, we will describe the TOP of the most popular techniques, methods, and algorithms used in modern Natural Language Processing.
Simplest metrics
Edit distance
Natural Language Processing usually signifies the processing of text or text-based information (audio, video). An important step in this process is to transform different words and word forms into one speech form. Also, we often need to measure how similar or different the strings are. Usually, in this case, we use various metrics showing the difference between words.
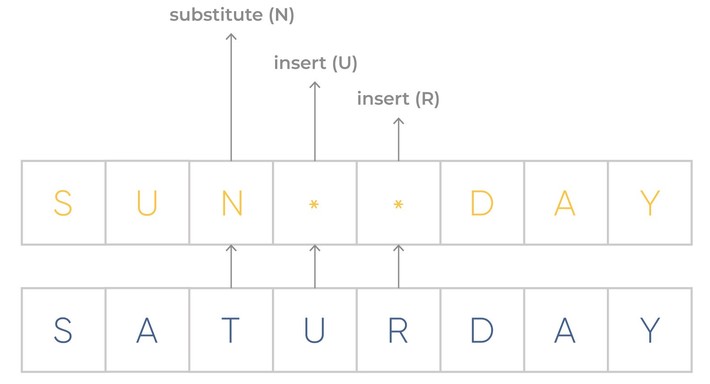
One of the simple and at the same time popularly usable metrics is Edit distance (sometimes is known as Levenshtein distance) – an algorithm for estimating the similarity of two string values (word, words form, words composition), by comparing the minimum number of operations to convert one value into another.
An example of Edit distance execution is shown below.

So this algorithm includes the following text operations:
- inserting a character into a string;
- delete (or replace) a character from a string by another character;
- characters substitutions.
Popular NLP applications for Edit distance:
- automatic spell-checking (correction) systems;
- in bioinformatics – for quantifying the similarity of DNA sequences (letters view);
- text processing – define all the proximity of words that are near to some text objects.
Cosine similarity
Cosine similarity is a metric used for text similarity measuring in various documents. Calculations for this metric are based on the measures of the vector’s similarity by cosine vectors formula:
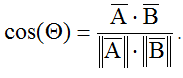
You can use various text features or characteristics as vectors describing this text, for example, by using text vectorization methods. For example, the cosine similarity calculates the differences between such vectors that are shown below on the vector space model for three terms.
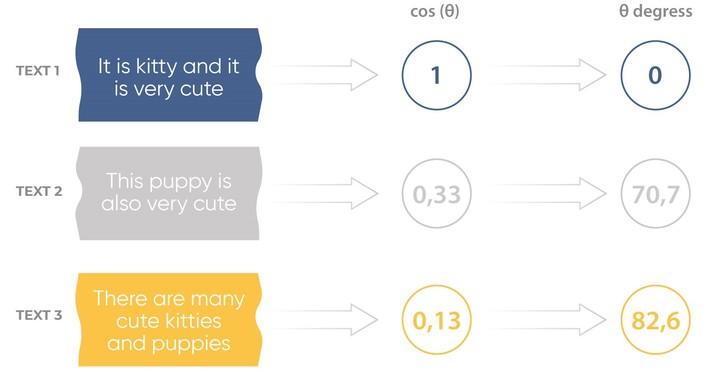
The calculation result of cosine similarity describes the similarity of the text and can be presented as cosine or angle values.
The results of calculation of cosine distance for three texts in comparison with the first text (see the image above) show that the cosine value tends to reach one and angle to zero when the texts match.
So received cosine similarity values can be used for simple semantic text preprocessing
Vectorization
Vectorization is a procedure for converting words (text information) into digits to extract text attributes (features) and further use of machine learning (NLP) algorithms.
In other words, text vectorization method is transformation of the text to numerical vectors. The most popular vectorization method is “Bag of words” and “TF-IDF”.
Bag of words
The most intuitive and simple way to vectorize text information involves the following:
- assign to each word a unique integer index to build a dictionary of words with integer indexes;
- count the number of appearances of each word and save it (number) with the relevant index.
As a result, we get a vector with a unique index value and the repeat frequencies for each of the words in the text.
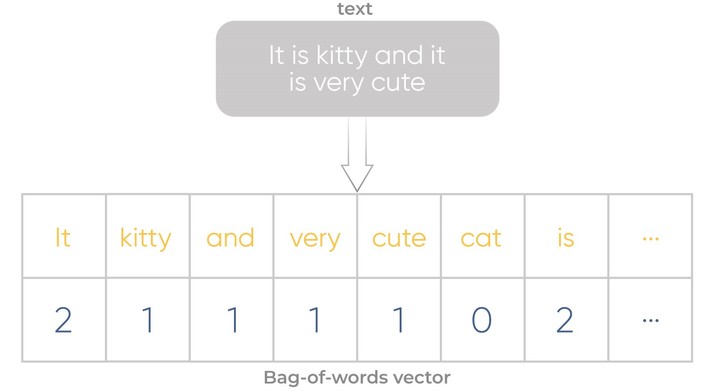
Representing the text in the form of vector – “bag of words”, means that we have some unique words (n_features) in the set of words (corpus).
TF-IDF
TF-IDF stands for Term frequency and inverse document frequency and is one of the most popular and effective Natural Language Processing techniques. This technique allows you to estimate the importance of the term for the term (words) relative to all other terms in a text.
Main idea: if a term appears in some text frequently, and rarely in any other text – this term has more importance for this text.
This technique uses TF and IDF algorithms:
- TF – shows the frequency of the term in the text, as compared with the total number of the words in the text.
- IDF – is the inverse frequency of terms in the text. It simply displays the importance of each term. It is calculated as a logarithm of the number of texts divided by the number of texts containing this term.
TF-IDF algorithm:
- Evaluate the TF-values for each term (word).
- Extract the IDF-values for these terms.
- Get TF-IDF values for each term: by multiplying TF by IDF.
- We get a dictionary with calculated TF-IDF for each term.
The algorithm for TF-IDF calculation for one word is shown on the diagram.
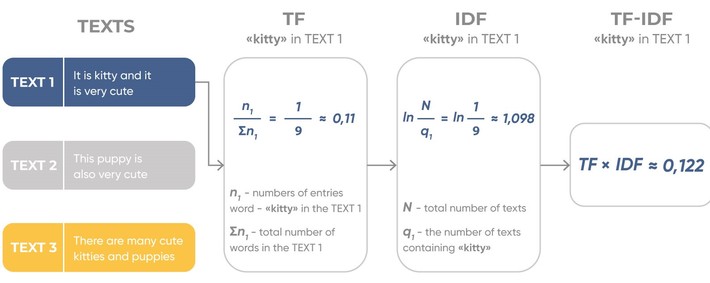
The results of the same algorithm for three simple sentences with the TF-IDF technique are shown below.
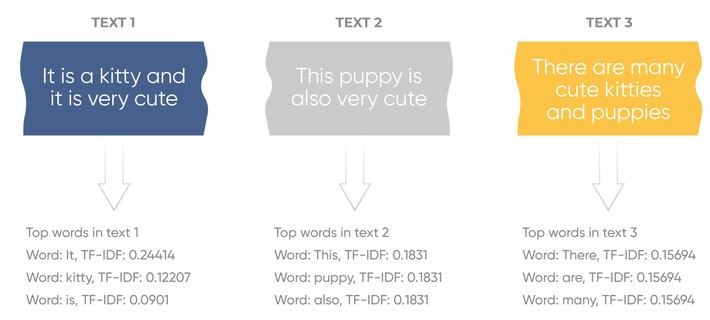
The advantages of this vectorization technique:
- Unimportant terms will receive low TF-IDF weight (because they are frequently found in all texts) and important – high.
- It is simple to evaluate important terms and stop-words in text.
Text Normalization
Text normalization (or word normalization) methods in Natural Language Processing are used for preprocessing texts, words, and documents. Such procedures usually used for the correct text (words, or speech) interpretation to acquire more accurate NLP models. Among them, we can highlight:
- Context-independent normalization: removing non-alphanumeric text symbols.
- Canonicalization: convert data to “standard”, “normal”, or canonical form.
- Stemming: extracts the word’s root.
- Lemmatization: transforms word to its lemma.
Let’s describe the Stemming and Lemmatization.
Stemming and Lemmatization
Usually, text documents use different word forms, for example:

Also, there are words with similar definitions:
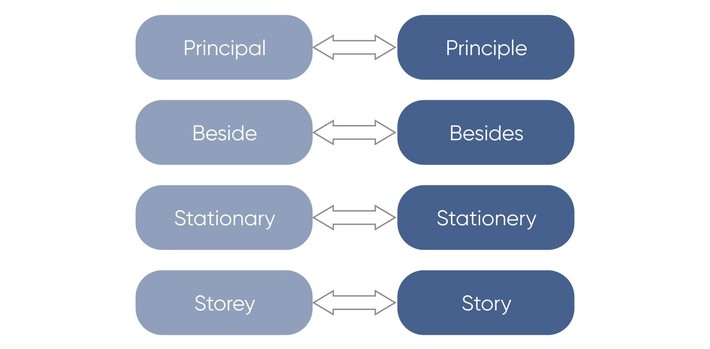
The stemming and lemmatization object is to convert different word forms, and sometimes derived words, into a common basic form.
Stemming is the technique to reduce words to their root form (a canonical form of the original word). Stemming usually uses a heuristic procedure that chops off the ends of the words.
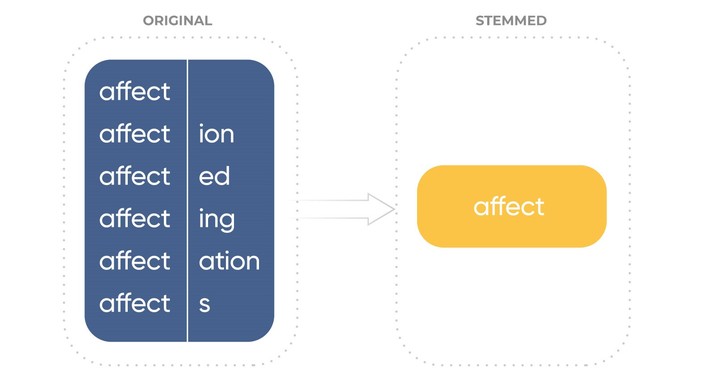
Stemming is useful for standardizing vocabulary processes. At the same time, it is worth to note that this is a pretty crude procedure and it should be used with other text processing methods.
Lemmatization is the text conversion process that converts a word form (or word) into its basic form – lemma. It usually uses vocabulary and morphological analysis and also a definition of the Parts of speech for the words.
The difference between stemming and lemmatization is that the last one takes the context and transforms a word into lemma while stemming simply chops off the last few characters, which often leads to wrong meanings and spelling errors.
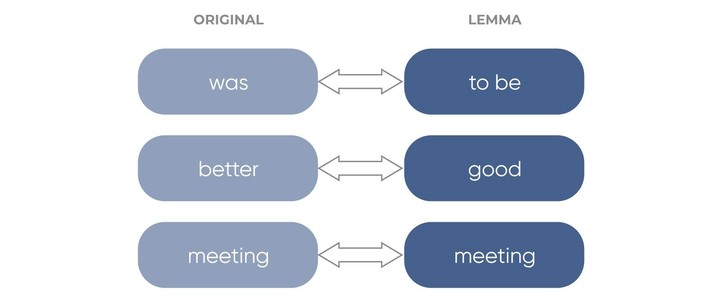
So, lemmatization procedures provides higher context matching compared with basic stemmer.
Naive Bayes algorithm
The Naive Bayesian Analysis (NBA) is a classification algorithm that is based on the Bayesian Theorem, with the hypothesis on the feature’s independence.
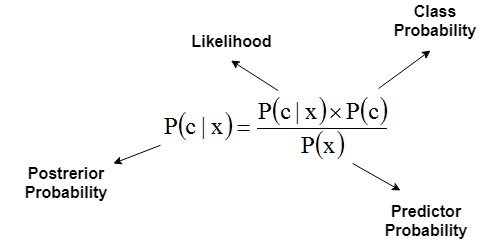
In other words, the NBA assumes the existence of any feature in the class does not correlate with any other feature. That’s why such an approach is called “Naive”. The advantage of this classifier is the small data volume for model training, parameters estimation, and classification.
In most cases, NBA in the Natural Language Processing sphere is used for text classification (clustering). The most known task is a spam detection filter. Most solutions in this sphere use the maximum likelihood method to estimate the parameters of Naive Bayesian models:
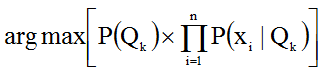
The first multiplier defines the probability of the text class, and the second one determines the conditional probability of a word depending on the class.
Approach advantages:
- Classification and multiclass classification, are quick and simple.
- On the assumption of words independence, this algorithm performs better than other simple ones.
- The NBA works with categorical features better than with continuous ones.
The most popular applications for text analysis are:
- Text classification.
- Spam filtering.
- Text tonality analysis.
Word embedding
Word embedding is a set of various methods, techniques, and approaches for creating Natural Language Processing models that associate words, word forms or phrases with number vectors.
Word embedding principles: words that appear in the same context have similar meanings. In this case, the similarity is broadly understood that only similar words can be located nearby (in context).
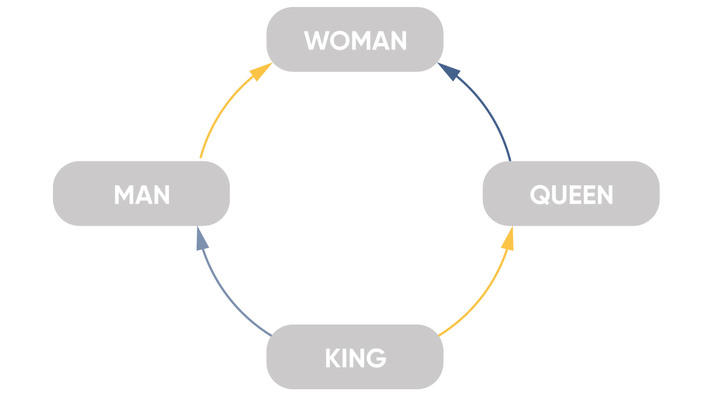
The model predicts the probability of a word by its context. So, NLP-model will train by vectors of words in such a way that the probability assigned by the model to a word will be close to the probability of its matching in a given context (Word2Vec model).
Generally, the probability of the word’s similarity by the context is calculated with the softmax formula. This is necessary to train NLP-model with the backpropagation technique, i.e. the backward error propagation process.
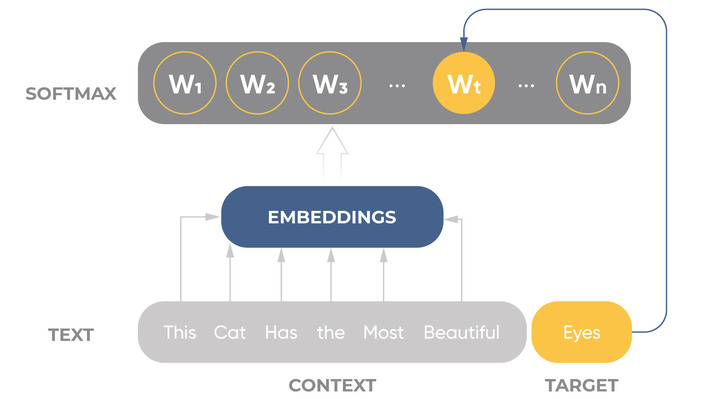
The most popular word embeddings:
- Word2Vec – uses neural networks to calculate word embedding based on words’ context.
- GloVe – uses the combination of word vectors that describes the probability of these words’ co-occurrence in the text.
- FastText – uses a similar principle as Word2Vec, but instead of words it uses their parts and symbols and as a result, the word becomes its context.
For today Word embedding is one of the best NLP-techniques for text analysis.
Long short-term memory
Long short-term memory (LSTM) – a specific type of neural network architecture, capable to train long-term dependencies. Frequently LSTM networks are used for solving Natural Language Processing tasks.
LSTM network include several interacting layers:
- cell state,
- input gate layer,
- cell status update,
- output data.
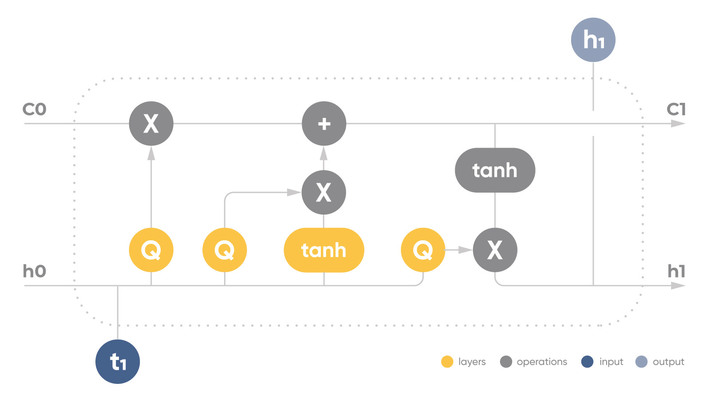
The main component of LSTM is the cell state – a horizontal line (с0-с1). The condition of the cell is similar to a conveyor line. Information passes directly through the entire chain, taking part in only a few linear transforms. The information can flow without any changes.
LSTM can also remove the information from a cell state (h0-h1). This process is controlled by filters (gates – Q-cells). The LSTM has three such filters and allows controlling the cell’s state.
LSTM variations:
- “peephole connections” – filter layers can additionally control the cell state;
- “forgotten” and input filters – adds options to ignore or keep in memory information as a joint decision by networks cells;
- gated recurrent units (GRU) – the “forgetting” and input filters integrate into one “updating” filter (update gate), and the resulting LSTM model is simpler and faster than a standard one.
Natural Language Processing tasks for which LSTM can be useful:
- Question Answering.
- Sentiment Analysis.
- Image to Text Mappings.
- Speech Recognition.
- Part of Speech Tagging.
- Named Entity Recognition.
So, LSTM is one of the most popular types of neural networks that provides advanced solutions for different Natural Language Processing tasks.
Conclusions
In this article we have reviewed a number of different Natural Language Processing concepts that allow to analyze the text and to solve a number of practical tasks. We highlighted such concepts as simple similarity metrics, text normalization, vectorization, word embeddings, popular algorithms for NLP (naive bayes and LSTM). All these things are essential for NLP and you should be aware of them if you start to learn the field or need to have a general idea about the NLP.
{kind=link}