
So here are my three principle experiences you won’t effectively discover in books.
1. Evaluation Is Key
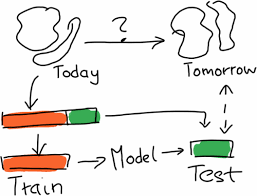
The main goal in data analysis/machine learning/data science,is to build a system which will perform
well on future data. The distinction between supervised and unsupervised learning makes it hard to talk
about what this means in general, but in any case you will usually have some data set collected on
which you build and design your method. But eventually you want to apply the method to future data, and
you want to be sure that the method works well and produces the same kind of results you have seen on
your original data set.
A mistake often done by beginners is to just look at the performance on the available data and then
assume that it will work just as well on future data. Unfortunately that is seldom the case. How about
we simply discuss administered learning for the time being, the place the undertaking is to foresee a
few yields in view of your contributions, for instance, group messages into spam and non-spam.
If you only consider the training data, then it’s very easy for a machine to return perfect predictions
just by memorizing everything.Actually, this isn’t that uncommon even for humans. Remember when you
were memorizing words in a foreign language and you had to made sure that you were testing the words
out of order.
Still, a lot can go wrong, especially when the data is non-stationary, that is, the underlying
distribution of the data is changing over time. Which often happens when you are looking at data
measured in the real world. Sales figures will look quite different in January than in June.
There is a lot of correlation between the data points, meaning that if you know one data point you
already know a lot about another data point. For instance, in the event that you take stock costs, they
as a rule don’t bounce around a great deal from one day to the next, so that doing the preparation/test
split haphazardly by day prompts preparing and test informational indexes which are very associated.
2. It’s All In The Feature Extraction
Learning about a new method is exciting and all, but the truth is that most complex method essentially
perform the same, and that the real difference is made by the way in which raw data is turned into
features used in learning.
They are okay at distinguishing the useful components sufficiently given information, yet in the event
that the data isn’t in there, or not representable by a linear combination of input features, there is
little they can do. The are also not able to do this kind of data reduction themselves by having
“insights” about the data.
Put in an unexpected way, you can enormously decrease the measure of information you require by finding
the correct elements. Speculatively, if you reduced all the features to the function you want to
predict, there is nothing left to learn, right? That is how powerful feature extraction is…
3. Show Selection Burns Most Cycles, Not Data Set Sizes
Presently this is something you would prefer not to state too boisterously in the period of Big Data,
however most informational indexes will splendidly fit into your primary memory. What’s more, your
strategies will likely likewise not take too long to keep running on the information. Be that as it
may, you will invest a ton of energy separating highlights from the crude information and running
cross-approval to analyze distinctive component extraction pipelines and parameters for your learning
strategy.
For model determination, you experience an extensive number of parameter mixes, assessing the execution
on indistinguishable duplicates of the information.
The issue is all in the combinatorial blast. Suppose you have only two parameters,and it takes about a
moment to prepare your model and get an execution evaluate on the hold out informational index. On the
off chance that you have five applicant esteems for each of the parameters, and you perform 5-overlap
cross-approval , this implies you will as of now do 125 rushes to discover which technique functions
admirably, and rather than one moment you hold up around two hours.
{kind=link}