

Microsoft publicly endorsed Open AI, with ‘Copilot’ embedded in every single bit of the Microsoft stack. Behind the scenes, with everything closed source, nobody knew if these AI assistants were driven by Cortana, Bing, or Open AI. The assistant technology is not new, and other than code generation and assisted writing, some wonder what value Open AI brings to Microsoft Office or Microsoft Windows.
Non-serious writers would buy Microsoft Office not just for its utility for email composition but also for other purposes. And in contrast, dedicated writers already recognize Microsoft Office’s power and utilize its comprehensive features for their writing activities.
How does Copilot balance producing too much and too little code?
Copilot development is still not mainstream because developers must be able to debug the generated code, so how do we balance the tradeoff between generating too much and too little code? It is too early to tell whether ‘Copilot with Visual Studio’ will be a huge payoff. While there will be many new apps, they are far from something that can be used for mass monetization. While Github’s $1 billion annual recurring revenue (ARR) is impressive, it is only considered a small business unit by revenue at Microsoft, as anything below $1 billion is not considered material in the company. The investment into Open AI is meant to disrupt competitors like Google, allowing them to spend fewer resources on GCP and preventing them from impacting Azure.
It’s a data war, not just an AI war
While much of the focus is on generative AI, people tend to forget that we also need to store the data. The world certainly does not lack data. Since the beginning of the Internet, we have blogs, emails, and social media. The world is not lacking text data to train models. The only question is how and where to store the increasingly growing data. Coupled with generative AI, there will be more unstructured data than structured, which is where Data Lake thrives.
While Databricks users have long enjoyed the ability to process unstructured data (e.g., video and audio) at scale using Spark/Databricks since the beginning of time, Snowflake is a data warehouse that only added Snowpark support in Jan 2022.
Databricks is better positioned in the era of generative AI beyond text data.
But why choose a side?
First of all, is it about choosing a side?
Absolutely.
The war on analytics started with Spark and then Snowflake. Big cloud vendors like Azure and AWS slowly developed solutions to attract these users to their environment. For Azure, there is Synapse Analytics; for AWS, there is Athena. If we look at it closely, Azure has decided to choose the Delta format as storage, which is developed by Databricks, whereas AWS chooses the Iceberg format, which is endorsed by Snowflake, despite being developed by Netflix and Apple.
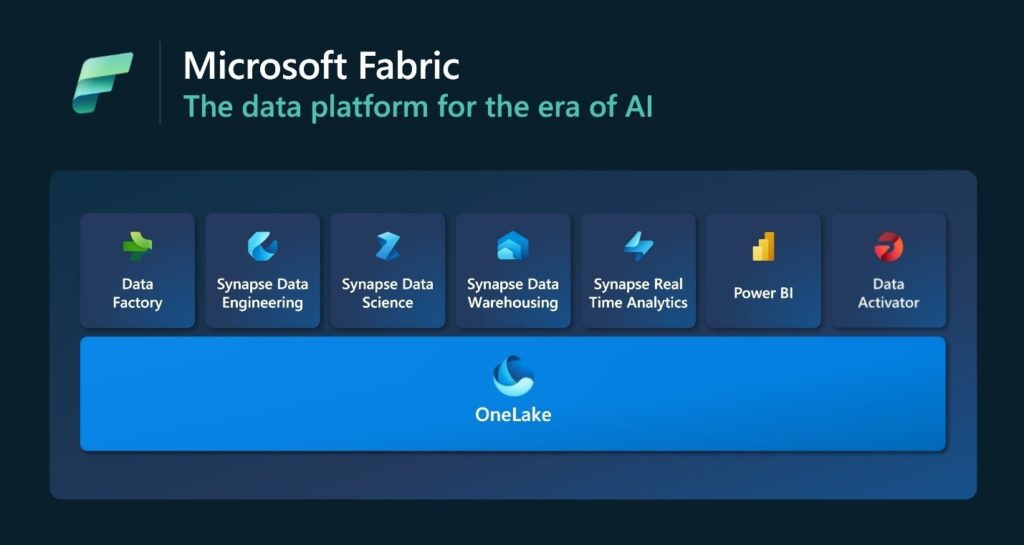
With the announcement of Fabric at Microsoft Build, Microsoft is not only betting more on Spark, but their OneLake vision is also built on top of Databricks’ lakehouse paradigm, and Microsoft is naming Fabric after Databricks’ Lakehouse: Microsoft Fabric Lakehouse.
It is a huge deal for Databricks to have a $2 trillion company’s full support while its valuation is *only* around $30 to $40 billion. Everything in Fabric will default to Delta format, including Microsoft’s data products. It is an example of incredible deal-making behind the scenes.
Behind the scene, what I believe is that Microsoft is encouraging users to generate more using Copilot, but they are enabling them to store in Delta format so users can analyze the data with AI.
Is the Delta format perfect?
This article, as recent as March 2023, talks about the Delta format’s limitations. And true to its words, any big data format is never meant to be good for transactional use like reporting. That’s why in the past, we’d push the processed data into SQL Server for reporting purposes.
However, the landscape is shifting. Power BI is now part of Microsoft Fabric. If Microsoft, a $2 trillion company, doesn’t believe in the future of Delta format, they have virtually unlimited resources to create a brand new format and even influence the industry to adopt it.
Yet, they have opted to use the Delta format.
Since the Delta format is now open source and Databricks is highly dependent on it, they can collaborate with Microsoft to enhance it to be more reliable and suitable for all use cases. It is worth noting that Microsoft has a much larger client base than Databricks, and if Microsoft starts committing resources to the Delta format because they have customer needs for extremely large-scale analytics, they are going to deploy more resources to enhance the Delta format as well as the Spark processing engine. This will only serve to benefit Databricks.
The OneLake vision is also big for Microsoft
When we look at OneLake, it is not just a simple rebranding. It is a very bold vision for Microsoft to democratize data and AI from the pricing, usability, and data lake standpoint.
- Pricing: While it is still tricky to navigate license migration, Fabric simplified licensing for all toolsets – capacity and storage. Imagine there is an all-you-can-eat pricing for all Microsoft’s Enterprise Data + AI toolsets; this is the most transformative change that makes Microsoft a leader in the cloud’s increasingly complicated and confusing licensing world.


- Usability: The cloud has never offered a unified option for data processing. Worse yet, there are a lot of open source and proprietary (e.g., Snowflake, Azure SQL) formats that require users to duplicate the same data over and over again from one storage to another. Having a standardized format (in this case, Delta format) is a great deal – today, you can open photos and videos from any device without installing anything. Is that a coincidence or a coordinated effort?
- Data Lake or Data Swamp? Organizations are now facing the promise and challenge of more and more data. With generative AI, the data in the coming years will be unimaginably huge. Workers today can no longer keep track of where the data is coming from or going to or even which copy of the data is the latest. OneLake’s promise is to be able to virtualize all your data, from your desktop to Azure DataLake and even Amazon S3. This is the ultimate vision: Uniting data in the cloud and processing it with Azure Compute. Fabric automatically takes care of data virtualization without having to generate duplicate copies. This is also a huge win for customers who want to spend more time to analyze their data instead of making copies of the same data.
Delta format will become the standard of data format
The Delta format is poised to become the standard data format across various industries. Its robust features and capabilities have garnered widespread recognition and adoption. With its efficient storage mechanism and built-in version control, Delta format ensures data integrity and simplifies data management. Along with the adoption of Detla in OneLake, it is steadily revolutionizing how data is stored, processed, and shared, making it the go-to standard for data format in the foreseeable future.
Reference- https://learn.microsoft.com/en-us/fabric/get-started/microsoft-fabric-overview
{kind=link}