
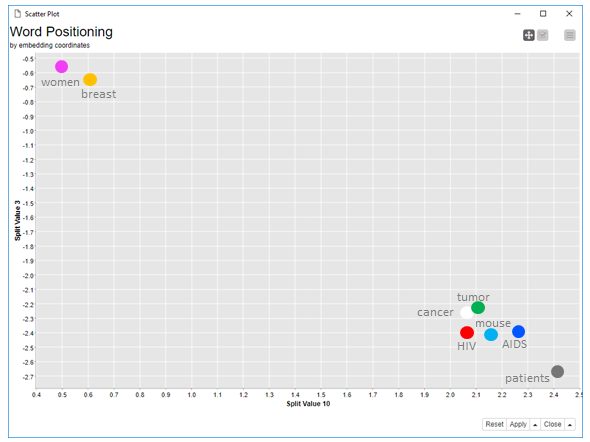
Figure 1. Scatter plot of word embedding coordinates (coordinate #3 vs. coordinate #10). You can see that semantically related words are close to each other.
This blog post is an extract from chapter 6 of the book “From Words to Wisdom. An Introduction to Text Mining with KNIME” by V. Tursi and R. Silipo, published by the KNIME Press. A more detailed version of this post is also available on the KNIME blog: “Word Embedding: Word2Vec Explained”.
Word2Vec Embedding
Word embedding, like document embedding, belongs to the text preprocessing phase. Specifically, to the part that transforms a text into a row of numbers.
In the KNIME Text Processing extension, the Document Vector node transforms a sequence of words into a sequence of 0/1 – or frequency numbers – based on the presence/absence of a certain word in the original text. This is also called “one-hot encoding”. One-hot encoding though has two big problems:
- it produces a very large data table with the possibility of a large number of columns;
- it produces a very sparse data table with a very high number of 0s, which might be a problem for training certain machine learning algorithms.
The Word2Vec technique was therefore conceived with two goals in mind:
- reduce the size of the word encoding space (embedding space);
- compress in the word representation the most informative description for each word.
Given a context and a word related to that context, we face two possible problems:
- from that context, predict the target word (Continuous Bag of Words or CBOW approach)
- from the target word, predict the context it came from (Skip-gram approach)
The Word2Vec technique is based on a feed-forward, fully connected architecture [1] [2] [3], where the context or the target word is presented at the input layer and the target word or the context is predicted at the output layer, depending on the selected approach. The output of the hidden layer is taken as a representation of the input word/context instead of the one-hot encoding representation. See KNIME blog post “Word Embedding: Word2Vec Explained” for more details.
Representing Words and Concepts with Word2Vec
In KNIME Analytics Platform, there are a few nodes which deal with word embedding.
- The Word2Vec Learner node encapsulates the Word2Vec Java library from the DL4J It trains a neural network for either CBOW or Skip-gram. The neural network model is made available at the node output port.
- The Vocabulary Extractor node runs the network on all vocabulary words learned during training and outputs their embedding vectors.
- Finally, the Word Vector Apply node tokenizes all words in a document and provides their embedding vectors as generated by the Word2Vec neural network at its input port. The output is a data table where words are represented as sequences of numbers and documents are represented as sequences of words.
The whole intuition behind the Word2Vec approach consists of representing a word based on its context. This means that words appearing in similar contexts will be similarly embedded. This includes synonyms, opposites, and semantically equivalent concepts. In order to verify this intuition, we built a workflow in KNIME Analytics Platform. The workflow is available for free download from the KNIME EXAMPLES server under:
08_Other_Analytics_Types/01_Text_Processing/21_Word_Embedding_Distance.
In this workflow we train a Word2Vec model on 300 scientific articles from PubMed. One set of articles has been extracted using the query “mouse cancer” and one set of articles using the query “human AIDS”.
After reading the articles, transforming them into documents, and cleaning up the texts in the “Pre-processing” wrapped metanode, we train a Word2Vec model with the Word2Vec Learner node. Then we extract all words from the model dictionary and we expose their embedding vectors, with a Vocabulary Extractor node. Finally, we calculate the Euclidean distances among vector pairs in the embedding space.
The figure at the top of this post shows some results of this workflow, i.e. the positioning of some of the dictionary words in the embedding space using an interactive scatter plot. For the screenshot above, we chose embedding coordinates #3 and #10.
In the embedding coordinate plot, “cancer” and “tumor” are very close, showing that they are often used as synonyms. Similarly “AIDS” and “HIV” are also very close, as it was to be expected. Notice that “mouse” is in between “AIDS”, “cancer”, “tumor”, and “HIV”. This is probably because most of the articles in the data set describe mice related findings for cancer and AIDS. The word “patients”, while still close to the diseases, is further away than the word “mouse”. Finally, “women” are on the opposite side of the plot, close to the word “breast”, which is also plausible. From this small plot and small dataset, the adoption of word embedding seems promising.
Note. All disease related words are very close to each other, like for example “HIV” and “cancer”. Even if the words refer to different diseases and different concepts, like “HIV” and “cancer”, they are still the topic of most articles in the dataset. That is, from the point of view of semantic role, they could be considered equivalent and therefore end up close to each other in the embedding space.
Continuing to inspect the word pairs with smallest distance, we find that “condition” and “transition” as well as “approximately” and “determined” are the closest words. Similarly, unrelated words such as “sciences” and “populations”, “benefit” and “wide”, “repertoire” and “enrolled”, “rejection” and “reported”, “Cryptococcus” and “academy”, are located very closely in the embedding space.
References
[1] Le Q., Mikolov T. (2014) Distributed Representations of Sentences and Documents, Proceedings of the 31st International Conference on Machine Learning, Beijing, China, 2014. JMLR: W&CP volume 32.
[2] Analytics Vidhya (2017), An Intuitive Understanding of Word Embeddings: From Count Vectors t…
[3] McCormick, C. (2016, April 19). Word2Vec Tutorial – The Skip-Gram Model. Retrieved from http://www.mccormickml.com http://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-m…
{kind=link}