Experiments In his book, The Master Algorithm, Pedro Domingos imagines the following experiments: Take a building, extremely well–built for two purposes: Noth...
In many business scenarios it is no longer desirable to wait hours, days or weeks for the results of analytic processes. Psychologically, people expect real-time or near ...
Where will blockchain go in the coming new year 2020? We’re on the edge of 2019. Isn’t this a great time to make predictions about blockchain – a revolutionary tech...
After going through Nano official forums, if you are planning to buy expensive wifi modules, just because of reported issues of connectivity loss, then you need to check ...
Despite the consuming controversy surrounding his presidency, POTUS 45 has been able to secure solid ratings on the performance of the economy over his so-far 30-month ad...
In Ontario, there has been a push for education to become more “monetizeable.” The education that people receive should better reflect the needs of the market. Th...
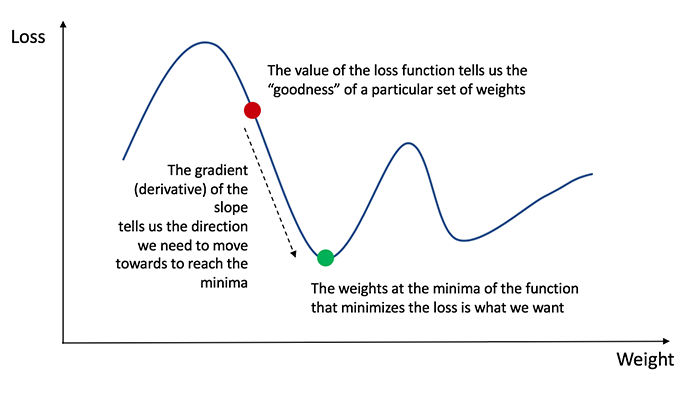
This article was written by James Loy. Update: When I wrote this article a year ago, I did not expect it to be thispopular. Since then, this article has been viewed m...
We propose simple solutions to important problems that all data scientists face almost every day. In short, a toolbox for the handyman, useful to busy professionals in an...
This is part 3 of a 3 part series: “How to make your mark on the world as a talented, socially conscious data scientist.” In the first post in this series, we explor...
This is the fourth article in a DeepTech Series by Margaretta Colangelo and Dmitry Kaminskiy. Dmitry Kaminskiy, General Partner at Deep Knowledge Ventures, is based i...