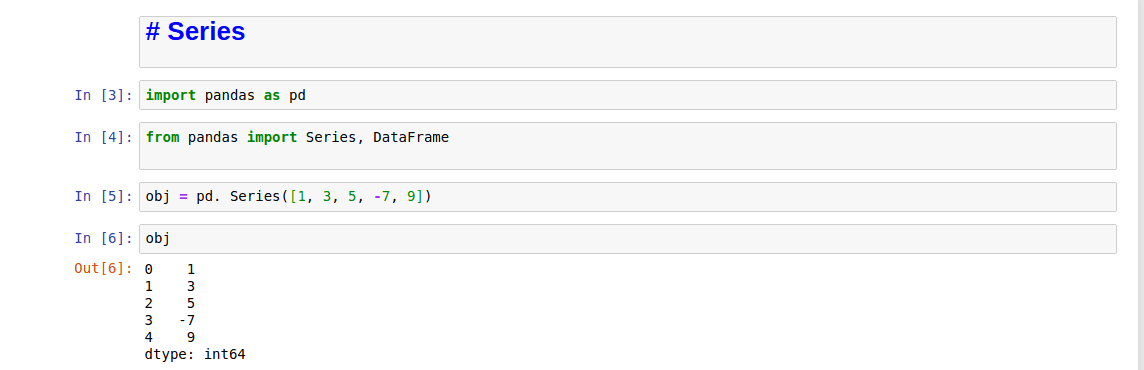
1. Introduction Pandas First, Pandas is an open source Python library for data analysis. It contains data manipulation and data structures tools designed to make spreadsh...
Shiny is the most popular framework among R users for developing dashboards and web applications. It is commonly used by statisticians and data scientists to present and ...
We are very happy to announce that DSC has found a new home: Tech Target (Nasdaq: TTGT), the global leader in purchase intent-driven marketing and sales services, has a 2...
Chatbots, voice-activated assistants and other AI-powered devices have been in use for over a decade. Over this time, human-to-machine interactions improved due to sophis...
A few years ago, in a Q&A session following a presentation I gave on data analysis (DA) to a group of college recruits for my then consulting company, I was asked to ...
An unpublished experimental report may have an interesting new way to understand the unexpected result of the Michelson-Morley Experiment of 1887. The new understanding...
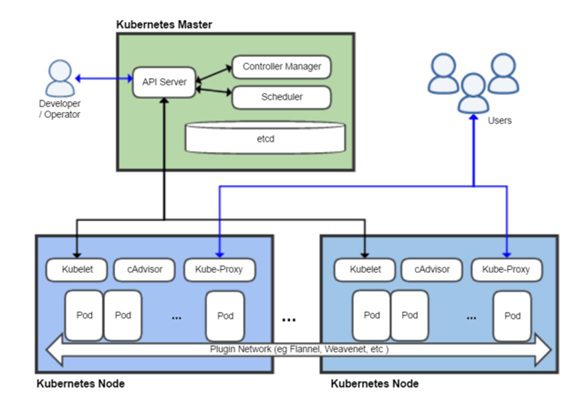
Introduction Kubernetes is being described as the next ‘Java’ i.e. it is fast becoming an endemic/ underlying platform for the whole industry just like the Java progr...
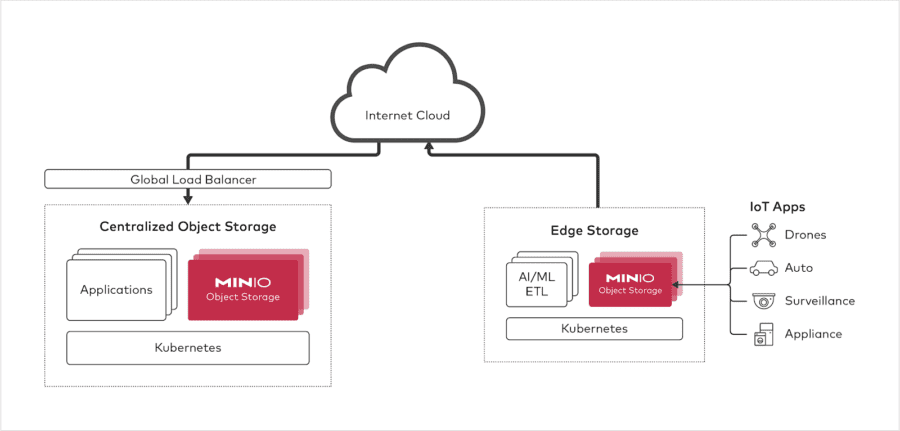
Edge computing is a hot topic and carries with it some confusion, particularly around storage. Handling data properly at the edge can ensure a scalable, cost-effective an...
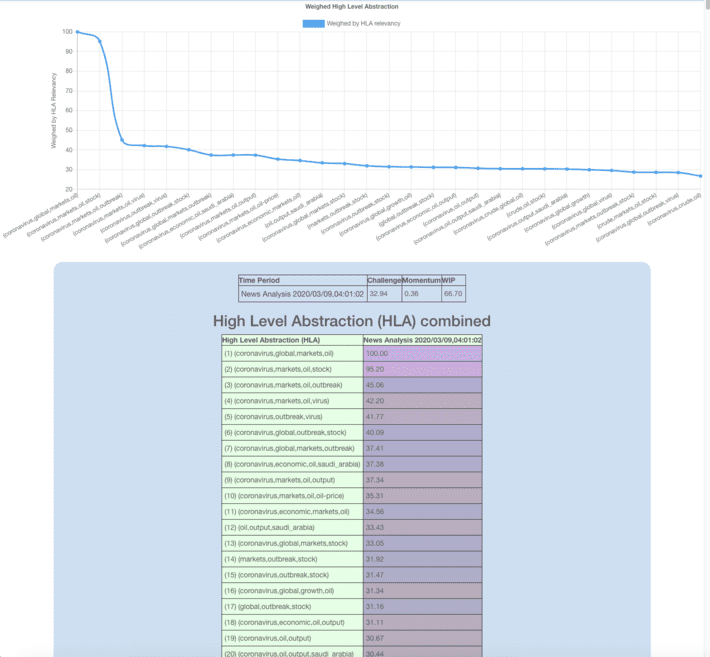
In my previous post, I introduced the ELAINE Community Tool that can be used to discover variables from textual communications. Statistical predictors work well for chart...
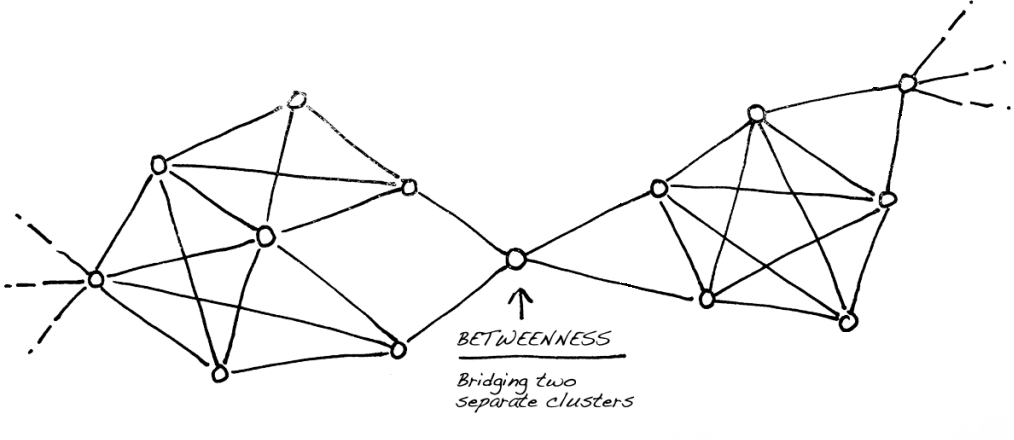
This article was written by Graph Commons. A common task for a data scientist is to identify clusters in a given data set. The idea is to simply find groups of objects th...