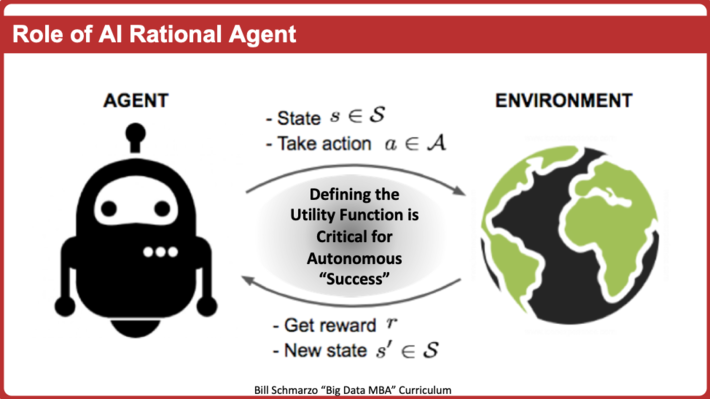
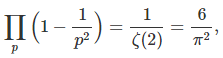Will Artificial Intelligence (AI) create an environment where design thinking skills are more valuable than data science skills? Will AI alter how we define human intelli...
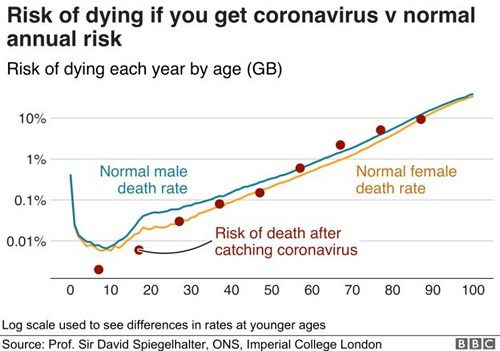
Misleading graphs are abound on the internet. Sometimes they are deliberately misleading, other times the people creating the graphs don’t fully understand the data...
The messiest job of the 21st century The interview process is likely the most daunting task a data scientist will face in their career. The pressure and competition to ...
Data gathering to keep a competitive advantage over other businesses will drive additional profit growth, especially in the e-commerce industry. Unfortunately, sending to...
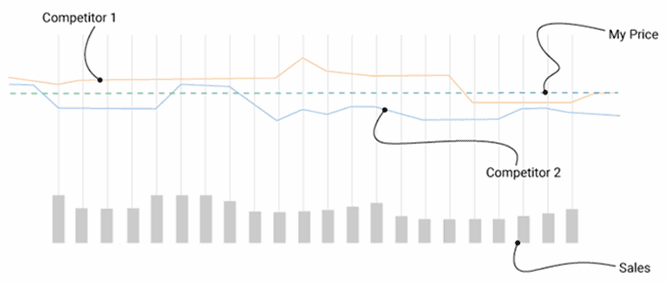
Because launching an online business has little to no initial cost, aspiring entrepreneurs will likely face a number of rivals who may try to undercut their pricing. Ther...
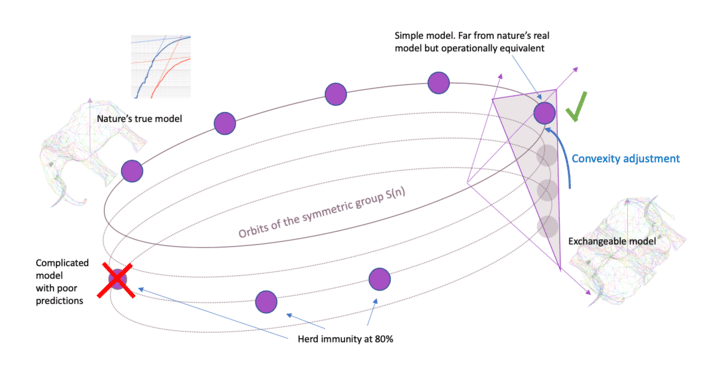
The work of an Italian mathematician in the 1930s may hold the key to epidemic modeling. That’s because models that try to replicate reality in all its detail have ...
Product of two large primes are at the core of many encryption algorithms, as factoring the product is very hard for numbers with a few hundred digits. The two prime fact...
Product of two large primes are at the core of many encryption algorithms, as factoring the product is very hard for numbers with a few hundred digits. The two prime fact...
Industry 4.0 or the fourth industrial revolution is predicted to revolve around data. Organizations that will thrive this revolution will be the ones that will realize th...
Mergers & acquisitions happen when companies believe they are more valuable together than when operating separately. The companies join workforces, systems, infrastru...