
Retrieval Augmented Generation (RAG) is becoming a platform in its own right. In this and the following post, we explore the foundations and more importantly, the evolution of RAG.
What is RAG?
The original objective of RAG was to provide information beyond the cutoff date for the LLM training. RAG then evolved to focus on reducing hallucinations.
The overall flow is as below
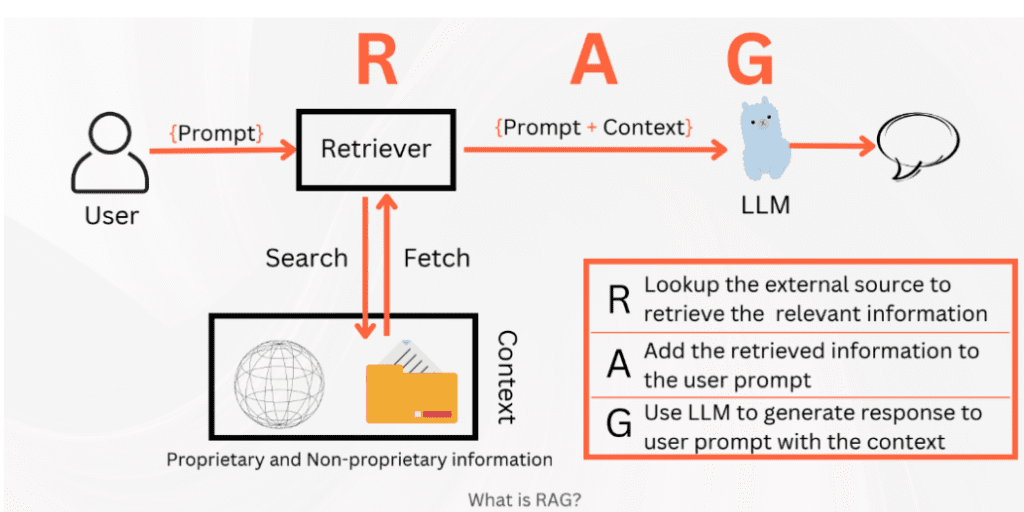
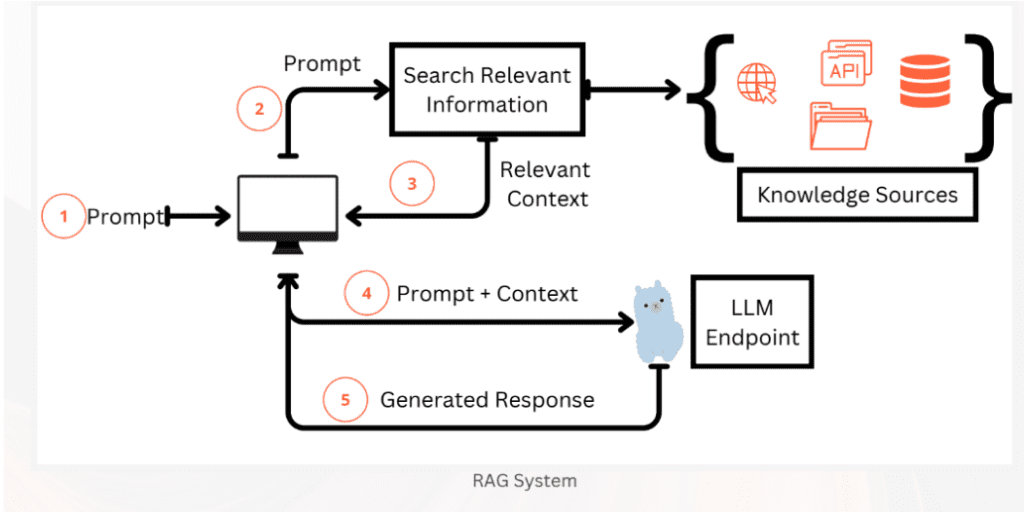
Image source and references: Book A Simple Guide to Retrieval Augmented Generation – Abhinav Kimothi
The basic five-step RAG process is
- The user writes a prompt or a query that is passed to an orchestrator.
- The orchestrator sends a search query to the retriever.
- Retriever fetches the relevant information from the knowledge sources and sends back.
- The orchestrator augments the prompt with the context and sends it to the LLM.
- LLM responds with the generated text which is displayed to the user via the orchestrator.
This process offers several benefits:
- Provides specific content to complement the LLM.
- Reduces hallucinations.
- Hides content from the LLM.
- Is cheaper than fine-tuning the model
RAG has two pipelines
The RAG pipeline itself which takes the user query at run time and retrieves the relevant data from the index then passes that to the model
and also the indexing pipeline where data for the knowledge is ingested from the source and indexed. This involves steps like splitting, creation of embeddings, and storage of data.
The loading stage involves extracting information from different knowledge sources and loading them into documents. The splitting stage involves splitting documents into smaller manageable chunks. Smaller chunks are easier to search and to use in LLM context windows. The embedding stage involves converting text documents into numerical vectors. The storing step involves storing the embeddings vectors (typically in a vector database).
There are two main frameworks for RAG: LangChain and LlamaIndex.
LangChain is a framework designed to simplify the development of applications leveraging large language models (LLMs) with external data sources. It provides tools and abstractions for integrating LLMs with a variety of data sources, processing workflows, and external APIs.
LlamaIndex is a tool designed to facilitate the integration of large language models (LLMs) with various data sources. It provides a flexible and efficient way to build, query, and manage data indexes, making it easier to retrieve and utilize relevant information in LLM applications.
It is also more interesting to see how RAG is evolving
The overall RAG ecosystem is as below
- Essentially, RAG needs embedders and VectorDBs for supplying additional contexts to LLMs, to achieve customization and alleviate hallucinations.
- MLOps for LLMs, i.e. LLMOps brings in an extra set of tools and best practices to manage the lifecycle of LLM-powered applications.
- Orchestration tools such as LlamaIndex, Langchain..
- Validations, Guardrails, LLMCache … and more about combining LLMs with auxiliary tools and resources for different use cases…
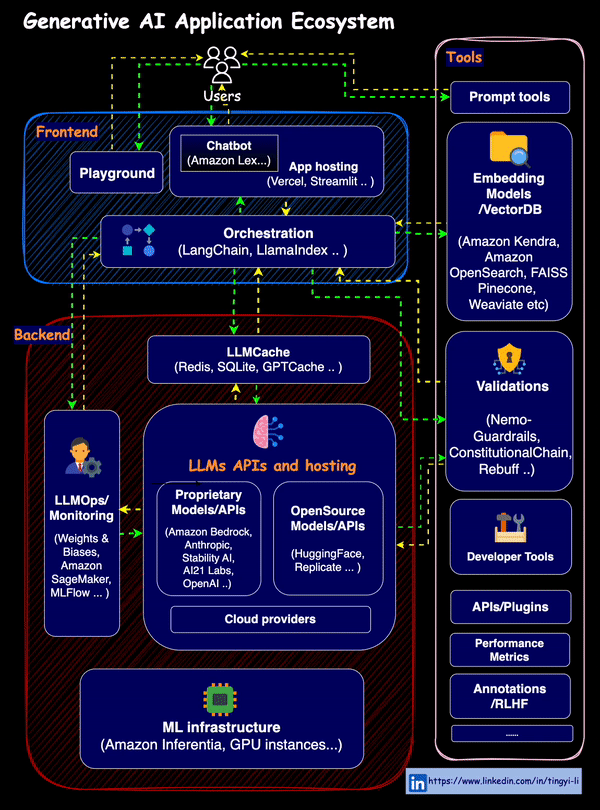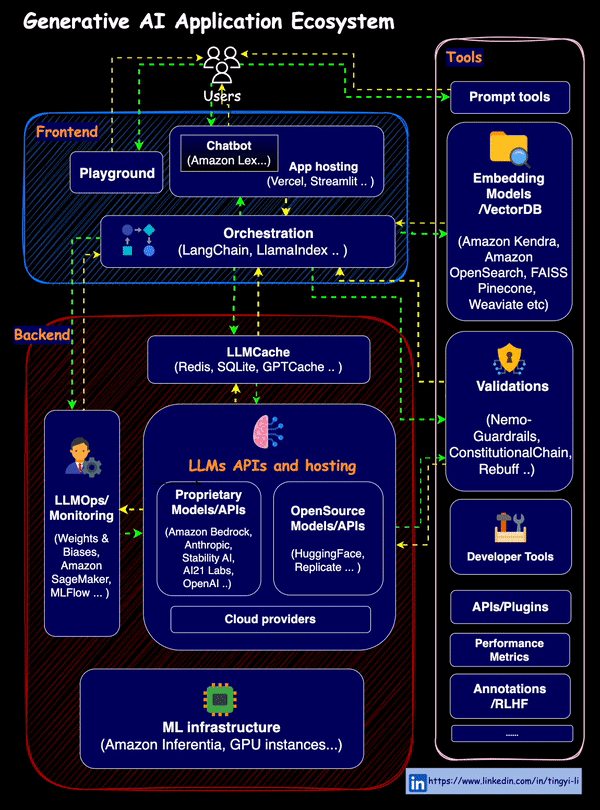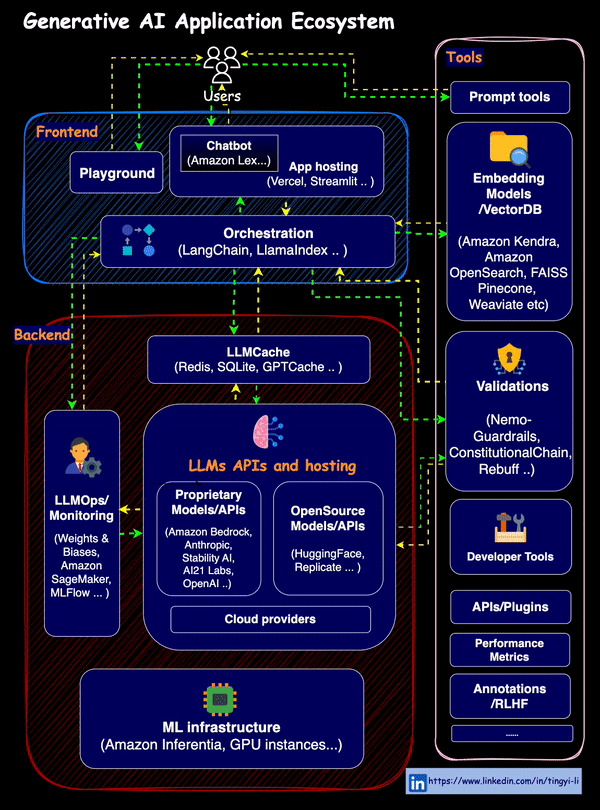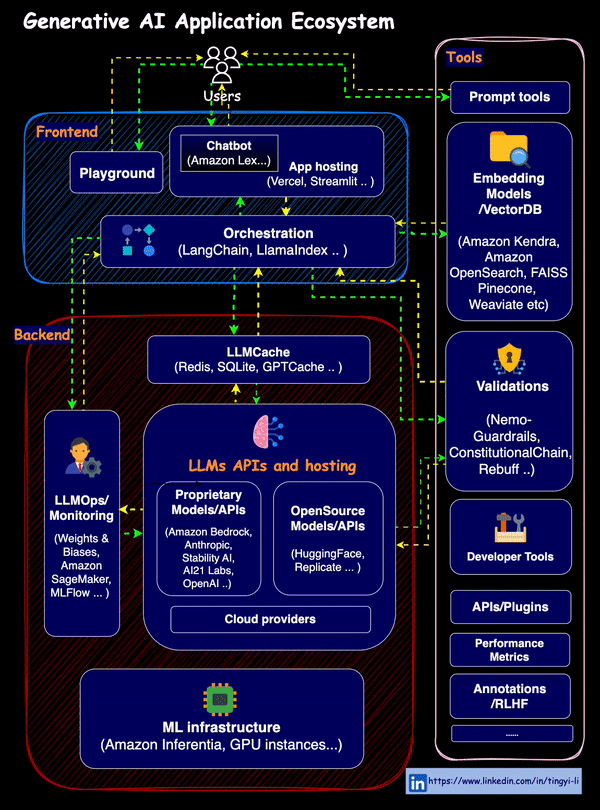
Image source: GenAI application ecosystem (Tingy Li)
There are three main paradigms for RAG
- Naive RAG
- Advanced RAG and
- Modular RAG
RAG itself is evolving with architectures like long context lengths, RAG evaluation methods and newer techniques for retrieval. We will look at the evolution of RAG in the next section.
RAG as a platform
Naive RAG is essentially a Retrieve followed by Read approach which focuses on retrieving information and comprehending it. To this, Advanced RAG adds other steps – both for preprocessing and post-processing. Finally, modular RAG converts RAG as a platform adding modules like Search, Routing, etc.
Below, we list enhancements to the basic RAG approach
- Pre-retrieval/Retrieval Stage
We can divide pre-retrieval strategies into various approaches
Retrieval: Breaking down external documents into right-sized chunks (chunk optimization). The methods of chunk optimization depend on content type, user queries, and application needs. We can integrate metadata into chunks (ex dates, purpose, chapter summaries, etc). This improves both retriever and search efficiency.
Query: Overall, the RAG system employs different types of searches like keyword, semantic, and vector search, depending upon the user query and the type of data available. We can use graph structures to enhance retrieval by leveraging nodes and their relationships. We can understand complex data structures through counterfactual reasoning by creating hypothetical (what-if) scenarios. We can also implement some form of rudimentary reasoning using query rewriting and multi-query approaches. This could include subquery i.e. breaking down a complex query into sub-questions for each relevant data source, then gathering all the intermediate responses and synthesizing a final response. This process could also be conducted in an interactive manner – proactively or recursively identifying the most suitable elements of the content for retrieval.
Specialized domains You could fine-tune embeddings for specialized domains.
2) Post Retrieval Stage
Information Compression: The retrieved information can be compressed to extract the most relevant points before passing it to the LLM.
Reranking: The documents are rearranged to prioritize the most relevant ones at the top,
3) Modular RAG
Modular RAG involves providing flexibility and adding modules like Search, Routing, etc.
Search: The search module performs search performing search on different data sources.
Memory: This module leverages the parametric memory capabilities of the Language Model (LLM) to guide retrieval.
The RAG-Fusion module improves traditional search systems by overcoming their limitations through a multi-query approach.
The overall RAG ecosystem is as below
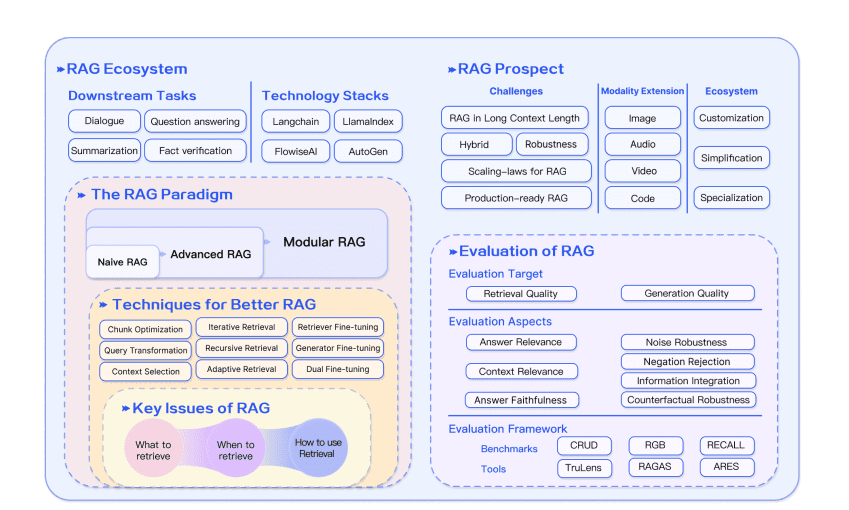
Image sources: Retrieval-Augmented Generation for Large Language Models: A Survey – https://arxiv.org/pdf/2312.10997
{kind=link}