

Today, data empowers individuals and organizations in many different ways. But in many other ways, we’ve barely scratched the surface of its potential. To dig deeper and find rich new resources, it’s good to consider where the underexplored, latent demand is for data-enabled services.
In this post, I’ll share ideas on where to start when it comes to identifying, mapping out, opening or expanding new data markets. This post is a continuation of “Prospecting for hidden data wealth opportunities (1 of 2)” https://www.datasciencecentral.com/prospecting-for-hidden-data-wealth-opportunities-i-of-2/ That earlier post provided background on existing data markets and ways to think about them.
What is data demand?
Data demand from a market forecasting standpoint is a measure or prediction of the need individuals or organizations have for some kind of data for some purpose. Most market forecasters have an overly narrow view of what constitutes data. Data machines can benefit from includes much more heterogeneous data types and sources.
Additional, reusable logic such as description logic (e.g., set theory), predicate logic and related logic can be declared within and enrich a knowledge graph. Such logic described as data in terms of foundational interoperability and reusability can live with the other data in the graph. From the graph, low-code apps can call the same core logic (when rationalized, 85 percent of what’s needed) repeatedly. The graph becomes a distribution point for many more resources than most are aware of.
Market research firms often organize focus groups or conduct surveys to assess demand for a new product, product feature, or service. But focus groups and surveys have only limited utility because both customers and market researchers don’t always understand or can’t articulate wants and needs.
As mentioned in Part 1 of this series. Apple is the leading company in the world in market capitalization (~$2.5T) for a reason. Keep in mind what the late Steve Jobs said when it comes to what customers really want:
“Some people say give the customers what they want, but that’s not my approach. Our job is to figure out what they’re going to want before they do. I think Henry Ford once said, ‘If I’d ask customers what they wanted, they would’ve told me a faster horse.’ People don’t know what they want until you show it to them. That’s why I never rely on market research. Our task is to read things that are not yet on the page.”
A larger model of unmet user demand
Demand for data that meets real user needs in a much better way is many times the current supply. Think of demand as potential. A user has an unmet need. That unmet need constitutes demand potential. Once providers begin to meet that need, then some degree of that potential is realized.
Take the example of securities trading. Top trading firms spend lavishly, even in one case blowing the tops off of mountains, to clear new fiber optics paths to value, for instance. By doing so, they save the fractional seconds that allow them to act on the leading indicators quickly enough. But even then, they don’t have a fraction of the other, also important indicators they could have other kinds of competitive advantage–for example, hidden opportunities or other factors that would change the balance of buy/sell/when decision entirely.
Data demand potential amounts to the right info at the right time in the right form. A substantial amount of this potential goes unrealized. Why? Because solutions almost always assume and work according to the constraints of existing information architecture.
Consider what the right info is. Ideally, it’s plug and play, which it certainly is not today. Data currently takes a highly convoluted and wasteful journey to some form of utility. The vast majority today is not useful twice if it is truly useful at all.
And even then, when it is useful, it’s only somewhat useful–useful when the right kind of human effort is applied to make it useful. Take ChatGPT, for example. AECOM’s operations director Lance Stephenson pointed out recently on LinkedIn, “ChatGPT only researches known knowns. Also, if there are any contentious issues, it defaults to popular opinion (which could be wrong).”
What Steve Jobs was alluding to when quoted earlier is known unknowns or even unknown unknowns. In a data market context, that’s currently where machines fall short and ad hoc, human-to-human knowledge sharing–or simply guesswork–tries to carry the ball across the finish line to successful decision-making.
The 12-step program to FAIR data and staking out unclaimed market territory
You know where most vendors and consultancies have staked claims. That territory ends where the myopia stops and the farsighted visions begin. Inside that fully staked-out territory boundary, the big market research firms keep slicing up the market they know best into smaller and smaller segments, after they do a buzzword survey, that is.
The unclaimed data market territory remains unclaimed because solving the most serious data problems is hard. That’s not to say there haven’t been many attempts to solve those problems. Those attempts, even the worthy ones, have been seriously underfunded. More than 90 percent of investor funding goes to incremental, rather than systemic improvements. And much of the incremental investment is in systems that complicate more problems than they solve.
Big consultancies think annual AI market potential by the 2030s could be in the trillions of dollars. The point they don’t highlight enough is that investors will have to spend a trillion dollars or more on the right things at well-managed concerns to make serious market penetration of the type they’re referring to feasible. And even then, benefits will come more slowly than economists expect because of adaptation slowness.
The other point not made is that much of the investment has to be in newly developed data collection, filtering, enhancement, and special plumbing specifically for semantic data layer enrichment at scale. Disambiguation, deduplication, and deep, reliable integration for sharing at scale matters. Tools such as ChatGPT that extract and frequently mishandle or misuse often biased common wisdom from websites prove this point.
As mentioned before, the challenge is getting the right insight to the right people at the right time in the right form. Below is a 12-step program outline for embracing the unclaimed data market.
The claimed, established market has long focused on perception or identification, simple classification, and (mere) connection (as opposed to semantic integration, contextualization, or interoperation). The other nine steps are territory that hasn’t really been fully even mapped yet.
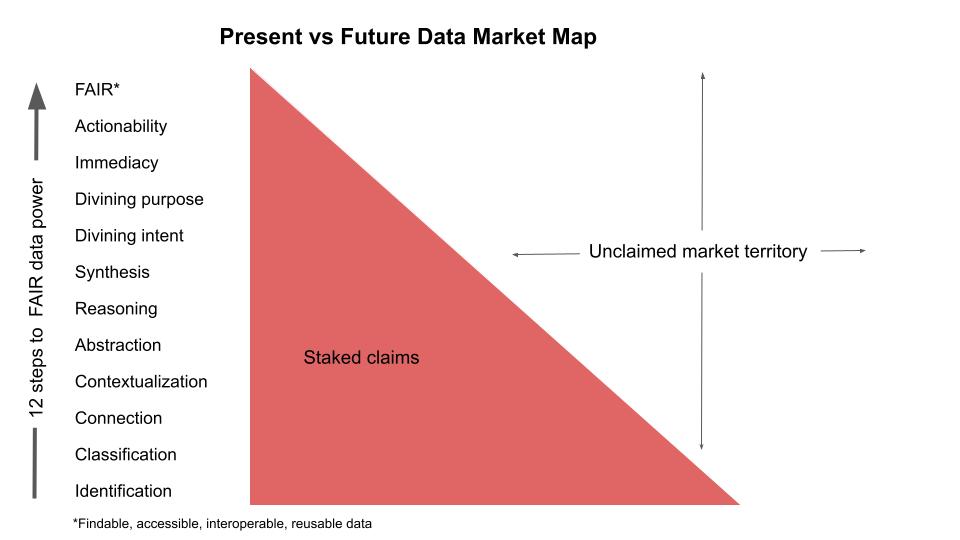
The twelfth step is FAIR data. If your company can deliver the right FAIR (findable, accessible, interoperable, and reusable) data to the users who need it when they need it in a way they can immediately use it, at scale, you might be able to select and stake out some unexplored market territory to yourselves–at least initially. A few companies have already staked a few big claims, mostly beneath the radar.
Data-centric architecture (DCA) designed to create and manage FAIR (findable, accessible, interoperable, and reusable) data helps users to break free of many of the constraints of the existing architecture. This type of DCA provides a map of the unclaimed territory and how to claim it.
Semantic knowledge graphs provide the foundational, proven technological means to Steps 4-12.
){kind=link}