
Summary: We are swept up by the rapid advances in AI and deep learning, and tend to laugh off AI’s failures as good fodder for YouTube videos. But those failures are starting to add up. It’s time to take a hard look at the weaknesses in AI and where that’s leading us.

2015 and 2016 have been really huge years for AI and deep learning.
- In image processing deep learning finally passed the human accuracy threshold (95% in the annual Image Net competition).
- Voice processing hit 99% accuracy unleashing a torrent of commercial chatbots.
- Reinforcement learning brought us self-driving delivery trucks in Nevada (Otto delivers beer) and Google’s Alpha Go beats the best human player at Go.
- Eight or more of the most prominent deep learning platforms including TensorFlow and Torch are released as open source.
- Elon Musk, Peter Thiel, and other big names join together to start OpenAI, a non-profit devoted to further open sourcing AI.
So everything’s coming up roses! Or is it? Trying to spot new themes and directions I was trolling through some data and I found this.
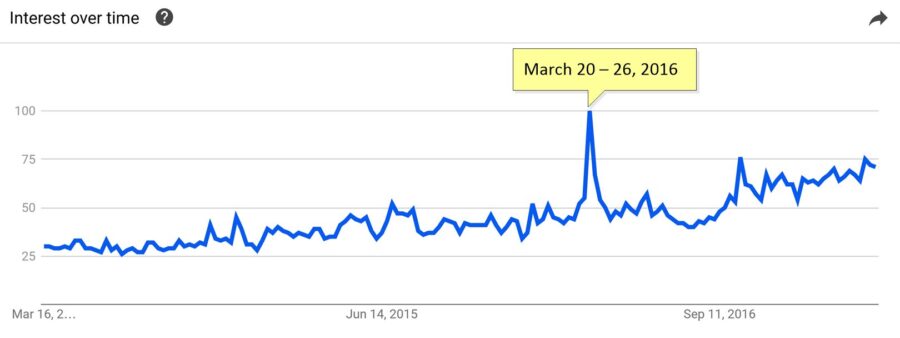
This is the Google Trends chart of searches for ‘Artificial Intelligence’ for the last four years. For clarification this is for AI ‘as a field of study’ not just raw search hits so presumably this audience is a little bit more like us, not just kids trolling for Terminator memes.
The overall curve is about what I expected, about doubling from 2014. But what’s with that unexpected outlier spike in late March 2016? Like any good data scientist I couldn’t just let that go. What would cause an almost two-fold increase in interest and fall back to the baseline pattern literally overnight?
All the World Loves a Good Train Wreck
With a little analytic diligence I found this.
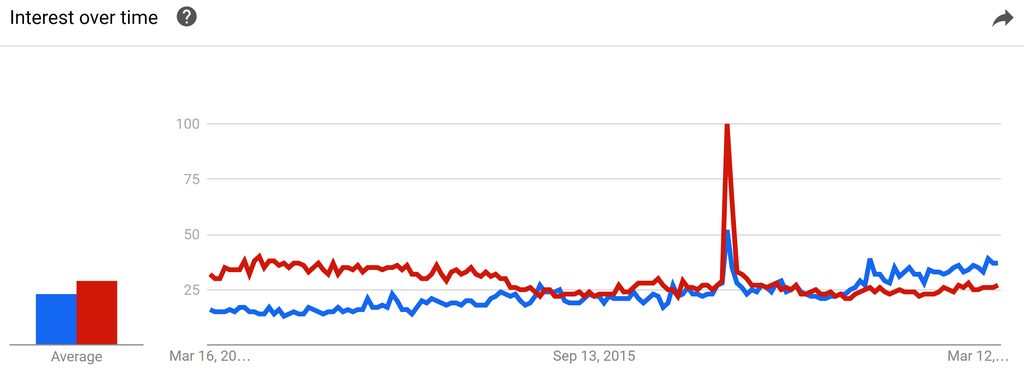
The blue line is the AI (as a field of study) line. The red line are searches for “Tay”. How could we forget 2016’s biggest AI fail. You should recall that Microsoft introduced identical AI twitter chatbots in Japan and the US.
 In Japan, Tay, under a different name, was a huge success. There were multiple reports of young men so smitten with her sensitive replies that they felt she could really understand them (Alan Turing should finally be satisfied).
In Japan, Tay, under a different name, was a huge success. There were multiple reports of young men so smitten with her sensitive replies that they felt she could really understand them (Alan Turing should finally be satisfied).
In the US however it was a different story. A group of smart but obviously mis-directed young people understood that Tay learned from her interactions with humans and set out to intentionally bias the results. Bias is huge understatement. This headline in ‘The Telegraph’ in the UK from March 24, 2016 says it all.
Microsoft deletes ‘teen girl’ AI after it became a Hitler-loving sex robot within 24 hours
16 hours is all it took. So all the world loves a good train wreck, but within a day or two the news cycle moved on and this was mostly forgotten if memorialized with millions of Youtube hits.
More Fun but Embarrasing Results from AI
At least once a month recently social media comes alive with some new report about an AI fail or hack.
Burger King: Last week it was the very clever ad agency for Burger King that produced an ad with the embedded line “Hey Google, what’s a Whopper”. If you had a Google chatbot within earshot of the television it would answer with the Wikipedia definition of the Burger King offering.
Alexa: There are numerous reports of the difficulty some households are experiencing if someone in the home is actually named ‘Alexa’.
Volvo: See the great YouTube post where a potential customer at a Volvo dealership is invited to test Volvo’s new pedestrian avoidance sensor. Predictably it didn’t work and the salesman goes flying over the hood of the car, mostly uninjured we think.
These are largely kinks in the social or UI aspects of the AI and we’re inclined to believe that these shortcoming are simply startup problems that will rapidly be worked out. However, as the developers of AI devices are aware, some of these problems are much deeper and more endemic.
Many Flaws of AI are Not Easily Over Come
There’s a greater lesson here and an issue we need to continuously surface. There are flaws in our approach to deep learning and AI that are not likely to go away any time soon. These aren’t small issues and can result in the outright failure of applications depending on image processing, speech and text processing, and reinforcement learning.
Technical
There is a well recognized flaw in Convolutional Neural Nets that makes even the best trained image classifiers fail in the face of very small amounts of random or intentional noise. We wrote about this at length in ‘Deep Learning Epic Fail – Right Answer – Wrong Reason’. The ‘noise’ can be an accidental artifact or an intentionally introduced defect and can be all but undetectable to the human eye, representing only say 1% of the image data.
In the world of unintended consequences, placing a small sticker or say a flyer for a garage sale on a stop sign has been shown to make the sign unrecognizable to an AV even though it has responded correctly to that particular sign dozens of times before.
In a more hostile scenario, our reliance on iris scans as the ultimate test of user authentication can be beaten by injecting a small random amount of noise into the image.
In our earlier article a procedure called LIME (Local Interpretable Model-Agnostic Explanations) has been shown to overcome some of this problem but it has not been shown to overcome all problems, nor to be able to be deployed quickly.
Social
Unfortunately we need to acknowledge that any weakness in a system will be exploited by bad actors. You may not think much about it but when spam finds its way into your inbox it’s because it has defeated the text processing deep learning algorithm implemented to protect you. Some of the more popular techniques are to insert spaces between letters or to use numerals like ‘0’ in place of ‘o’.
As our systems get smarter so will those with a desire to defeat them.
Regulatory
In our profession we are mostly hard wired to resist any regulatory intrusion that would slow us down. However, we’re rapidly coming up to the point where the absense of key regulation is what’s going to hold us back.
Nowhere is this more apparent than in self driving cars where two technical issues actually require agreement beyond the ability of any single OEM to implement.
The first is the need for car-to-car communication and cooperation. Technically this falls in the discipline of simultaneous localization and mapping (SLAM). OEMs will naturally want to keep their telematics proprietary but in the absense of a layer of shared data, AVs will be involved in unnecessary accidents.
The second is even more obvious and it’s known as ‘the trolley problem’. If the AV is to avoid harming humans does it prioritize the passengers within the AV, or the pedestrians and passengers in other cars? Depending on the decision that we as a society make, how will that effect your desire to own or even ride in an AV?
We haven’t yet experienced an AI failure with wide ranging financial or social consequences. Not to be pessimistic but the odds of this happening are pretty much 100%.
So while the commercialization of AI is launching a thousand new businesses and as we accept these conveniences into our lives, we need to remain cognizant that our deep learning is not perfect, and that the impact of bad actors or insufficient social input can derail much of what’s good about AI.
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist and commercial predictive modeler since 2001. He can be reached at:
{kind=link}