

What is Data Science and Machine Learning?
Data Science
- Data Science is a broader concept and multidisciplinary.
- Data science is a general process and method that analyze and manipulate data.
- Data science enables to find the insight and appropriate information from given data.
- Data Science creating an opportunity to use data for making key decisions in different business domains and technology.
- Data science provides a vast and robust way of visualization techniques to under the data insights.
Machine Learning
- Machine learning fits within data science.
- Machine learning uses various techniques and algorithms.
- Machine learning is a highly iterative process.
- Machine Learning algorithms are trained over instances.
- Machine Models are learned from past experiences and also analyze the historical data.
- Machine Model able to identify patterns in order to make predictions about the future of the given data.
“The main difference between the two is that data science as a broader term not only focuses on algorithms and statistics but also takes care of the entire data processing methodology”
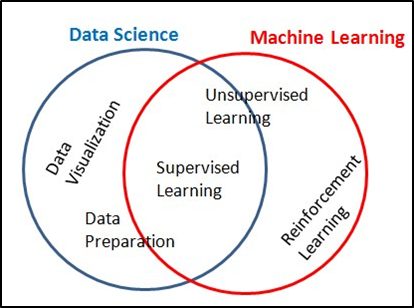
Let’s see quickly the Machine Learning Process – Overview and jump into Train and Test.

Understand the scenario
Certainly, you can assume how the students are getting trained before their board exams by the great teachers in School/College.
At School/College level we use to undergo many more Unit-test/Term exams/Revision exams/Surprise tests and etc., Here we have been trained on various combinations of questions, mix and match patterns.
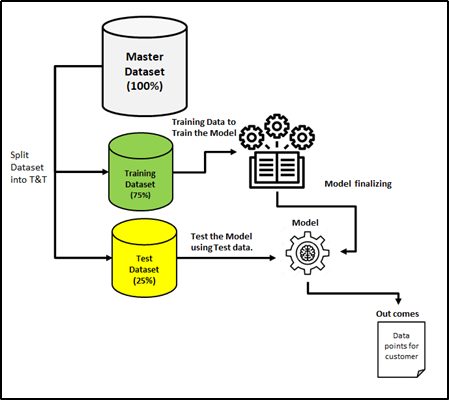
Hope you all come across these situations many times in your studies. No exceptional data set that we’re going to use in Data Science. All because we need to build a very strong model before we go into deploy the model in a production environment.
Similarly, in the Data Science domain, the Model has been trained by the sample data and makes them predicts the values with the available data set after data wrangling, cleansing, and EDA process, before deploying into the production environment, before the model meets the real-time/streaming data.
This process is always helping us to understand the insight of the data and what/which model we could use for our data set to address the business problems.
Here we must take care of the data set and it should match with real-time/streaming data feed (To align with all combinations), while the model performing in a production environment. So, the choice of data set (data preparation) is really key before the T&T process. Otherwise, the model situation becomes pathetic¦ as below in the picture. There might be huge effort loss, impact on the project cost and end up with unhappy customer service.

Here you should ask me the below questions.
- Why do you split data into Training and Test Sets?
- What is a good train test split?
- How do you split data into training and testing?
- What are training and testing accuracy?
- How do you split data into train and test in Python?
- What are X_train and Y_train X_test and Y_test?
- Is the train test split random?
- What is the difference between the training set and the test set?
Let me answer one-by-one here for your benefit to understand better way!
How do you split data into training and testing?
80/20 is a good starting point, giving a balance between comprehensiveness and utility, though this can be adjusted upwards or downwards based upon your model performance and volume of the data.
- Training data is the data set on which, you train the model.
- Train data from which the model has learned the experiences.
- Training sets are used to fit and tune your models.
- Test data is the data that is used to check if the model has learned well enough from the experiences it got in the train data set.
- Test sets are unseen data to evaluate your models.
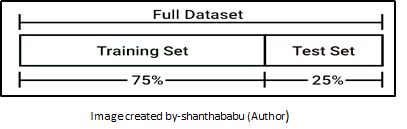
Architecture view of Test & Train process
CODE to split give dataset
# split our data into training and testing data
X_train,X_test,y_train,y_test = train_test_split(X_scaled,y,test_size=.25,random_state=0)
What are training and testing accuracy?
- Training accuracy is usually the accuracy we get if we apply the model to the training data
- Testing accuracy is the accuracy of the testing data.
It is useful to compare these to identify how Training and Test set doing during the Machine Learning process.
Code
model = LinearRegression() # initialize the LinearRegression model
model.fit(X_train,y_train) # we fit the model with the training data
linear_pred = model.predict(X_test) # make prediction with the fitted model
# score the model on the train set
print(‘Train score: {}\n’.format(model.score(X_train,y_train)))
# score the model on the test set
print(‘Test score: {}\n’.format(model.score(X_test,y_test)))
# calculate the overall accuracy of the model
print(‘Overall model accuracy: {}\n’.format(r2_score(y_test,linear_pred)))
# compute the mean squared error of the model
print(‘Mean Squared Error: {}’.format(mean_squared_error(y_test,linear_pred)))
Output
Train score: 0.7553135661809438
Test score: 0.7271939488775568
Overall model accuracy: 0.7271939488775568
Mean Squared Error: 17.432820262005084
What are X_train and Y_train X_test and Y_test?
- X_train This includes your all independent variables, (Will share detailed notes on independent and dependent variables) these will be used to train the model.
- X_test This is the remaining portion of the independent variables from the data which will not be used in the training set. Mainly used to make predictions to test the accuracy of the model.
- y_train This is your dependent variable that needs to be predicted by the model, this includes category labels against your independent variables X.
- y_test This is the remaining portion of the dependent variable. these labels will be used to test the accuracy between actual and predicted categories.
NOTE: We need to specify our dependent and Independent variables, before training/fitting the model. Identifying those variables is a big challenge and it should come out from the business problem statement, what we are going to address.
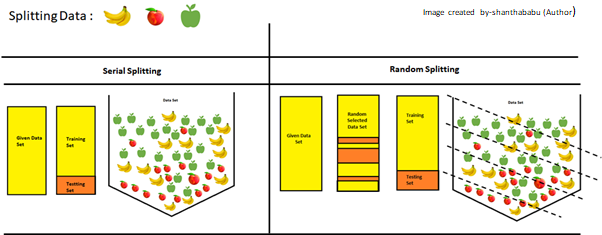
Is the train test split random?
The importance of the random split has been explained in the below picture clearly in a simple way! You could understand from pictorial representation!
In simple text, the model could understand what all data combination are is exists in the give data set.
The random_state parameter is used for initializing the internal random number generator, which will decide the splitting of data into train and test.
Let say! random_state=40, then you will always get the same output the first time you make the split. This would be very useful if you want reproducible results to finalize the model. from the below picture you could understand better why we prefer “RAMDOM Sampling”
Thanks for your time in reading this article! Hope! You all got an idea of Train and Test Split in the ML process.
Will get back to you with a nice topic shortly! Until then bye! See you all soon – Shanthababu
{kind=link}