

Image Source: Author
Logistic Regression is not Regression but a Classification Algorithm.
You might have seen this in latest popular machine learning books, blogs or you might have heard *Data Science Gurus* utter the same in their highly subscribed YouTube channels.
Machine learning has usurped and renamed many statistical techniques. Often to the extent that they now disbelieve and reject its statistical origins. Case in point is Logistic regression is not Regression
However, nothing can be further from the truth than this assertion. We live in a meme culture, memes even become cryptocurrency.
So why not use a meme to drive home the point that Logistic Regression is indeed Regression.
 Image Source: Author
Image Source: Author
This meme would have made things clearer for most of you. However, let me unpack it for more clarity.
Logistic Regression models a continuous outcome (the probabilities). The probabilities range between 0 and 1.
Binary Logistic Regression is used as a Classification algorithm when we want the response variable to be dichotomous (Churn/Not Churned, Pass/Fail, Spam/No spam etc.)
Usually, we make Logistic Regression into a classification algorithm by setting an appropriate probability cut-off or threshold (0.4, 0.5, 0.6 etc.).
The problem of classifying using a threshold value
Fixing the probability threshold is purely a business call and not a statistical one. The threshold could vary from one domain/industry to another.
Frank Harrell in his blog¹ aptly makes the point classification is a forced choice.
Now consider this example, you choose a threshold value of 0.5. Now the ML algorithm outputs the probability of default or no default (1- default, 0 no default) for 4 customers as 0.51, 0.49, 0.23 and 0.92. Based on the threshold, 2 are classified as default and 2 are classified as no default. However, ask yourself this, isnt it too close to call for the customers with probability 0.51 and 0.49? 0.51 is surely closer to 0.49 (which is classified as no default) than it is to 0.92 (which is classified as default).
Some popular machine learning packages and low code tools do not depict the predicted probabilities to the user explicitly. The user is hence oblivious to what predicted probabilities are gotten. He /she simply gets the decision default or no default (1 or 0). In the case of 0.49 and 0.51, the user happily made the decision that the person will not default and will default respectively. But a peek inside the predicted probabilities reveals that it was too close to call!
The other problem with thresholds is that, when we use an improper scoring rule like classification accuracy, it can be easily gamed. For e.g., if out of 100 people, 95 of them default on loan, and 5 dont. If the classifier classifies everyone to default on loan, then it would have an accuracy of 95% !!
So, is there a better way to use Logistic Regression?
The answer is Yes.
Industries such as Finance and Marketing use Logistic Regression in a more appropriate way for Credit risk modelling and marketing campaign targeting respectively.
A real use case
Let us say, you are a CMO in charge for sales and marketing of a product in your organization. You plan to launch a marketing campaign to increase sales of that product. You have been given a fixed budget for this. Now you would like to get the best ROI possible i.e., spend the exact fixed budget or even lesser and get the maximum sales possible. Here is what you have.
You have the data for 10,000 customers who had either purchased or not purchased a similar product in the past.
You would like to understand which customers should be targeted to increase the likelihood of purchase this time.
You would obviously like to target those people who are more likely to buy the product since you have a fixed budget for the campaign. How to go about it?
Decile Analysis and Gain Chart come to rescue here.
What is a Decile Analysis?
Decile analysis was once a popularly used technique, however the convention of teaching and bucketing machine learning problems into either classification or Regression types, lead people to forget Decile analysis type analyses. I am pretty sure, most freshly minted data scientists would not have even heard of Decile analysis. So, coming back to what is Decile Analysis.
Decile Analysis is used to categorize dataset from highest to lowest values or vice versa. (Based on predicted probabilities)
As obvious from the name, the analysis involves dividing the dataset into ten equal groups. Each group should have the same no. of observations/customers.
It ranks customers in the order from most likely to respond to least likely to respond.
How is Decile Analysis done?
Step 1: Build a Logistic Regression model. In this case the dependent variable was probability of buying the product. With 1 denoting purchased, 0 denoting not purchased. Also, the relevant independent variables were selected.
Step 2: Get the predicted probabilities from Logistic Regression algorithm. Arrange the probabilities in descending order.
Step 3: Divide the whole dataset into 10 groups, each group should contain equal no. of observations. So, if there 10,000 records, each group would have 1000 records/customers.
Step 4: Compute % of responders for each decile
Step 5: Compute response rate for each decile
Step 6: Compute lift for each decile
The top decile would have customers who are most likely to respond followed by the decile 2 which would have customers who are next most likely to respond and so on.
One major advantage of the decile analysis is that the probabilities and probability range are their own error measures. That is, if the top decile has the probability range 0.750.81, then then the probability of this person not buying the product i.e., the error would be (1- [0.750.81], here [] denotes the interval of values between 0.750.81 including 0.75 and 0.81)
What does a Decile Analysis output look like?
The below table depicts a typical decile analysis output.
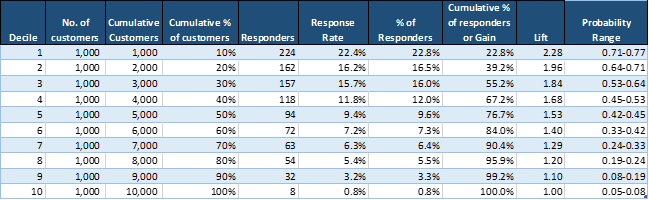 Table 1 – Source: Author
Table 1 – Source: Author
Lets unpack the output table.
As stated earlier, each decile has equal number of customers (1000 in each decile).
% of responders for each decile = No. of responders in that decile/ No. of total responders for all 10 deciles
Refer to Table 1:
Here, % of responders for Decile 1 = 224/984 = 22.8%
984 is the total no. of responders in all 10 deciles
Similarly, % of responders for Decile 2 = 16.5% (162/984)
And cumulative % of responders for top 2 deciles = 39.2%
Gains and Gain Chart
From table 1, Decile 1 contains top 10% of the customers who are most likely to buy. Decile 1 has the highest no. of responders (224 responders).
So out of the total responders in all deciles, 22.8% of the responders are in Decile 1. So, for 10% of the customer base, there are 22.8% responses in Decile 1.
Similarly for 20% of the customer base in decile 1 and decile 2, there are 39.2% responses.
Gain Chart below explains this better.
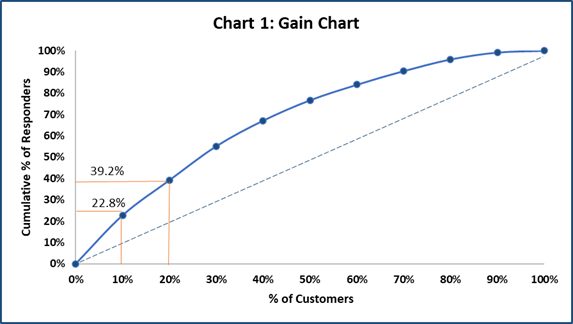
Image Source: Author
Takeaway from Gain Chart: Gain Chart can be used to assess what % of customers respond in each decile. So, rather than targeting customers from lower deciles, customers can be picked up from the top deciles only.
The dashed line is the Baseline. Baseline tells how much % of customers would respond if we target customers randomly without a model.
Response Rate
Response Rate tells what is the percentage of customers who responded in each decile. The response % is highest in Decile 1 followed by Decile 2 and so on.
Response Rate for each decile = No. of respondent in that decile/ No. of customers in that decile
Refer to Table 1:
Here, Response Rate for Decile 1 = 224/ 1000 = 22.4%
Takeaway from Response Rates comparison: Response Rate of each decile is depicted in the chart below. The average response rate of all deciles is 9.8%. So, customers from Decile 1 to Decile 4 lie above the average response rate and should be targeted for the campaign.
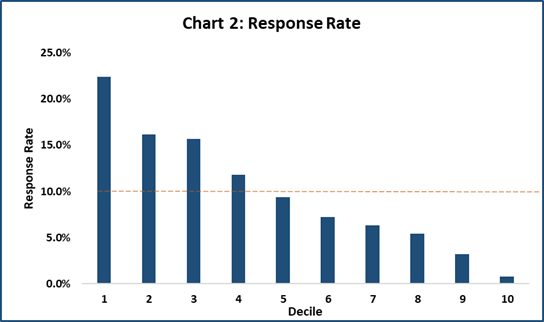
Image Source: Author
Lift and Lift Curve
Lift = cumulative % of responders / customers % at each decile
Refer to Table 1:
Lift for Decile 1 = 22.8%/10% = 2.28
Lift for Decile 2 = 39.2%/20% = 1.96
How to interpret: If we target top two deciles, then we would target 20% of the customers. In the same deciles, the cumulative % of responders are 39.2%. Hence, there is a lift of 1.96.
A lift of 1 means there is no gain compared with the no. of customers targeted at random. Lift greater than 1 means, model approach is better than selecting the customers at random.
Takeaway from Lift Chart: Can be used to identify the deciles which have a higher Lift.
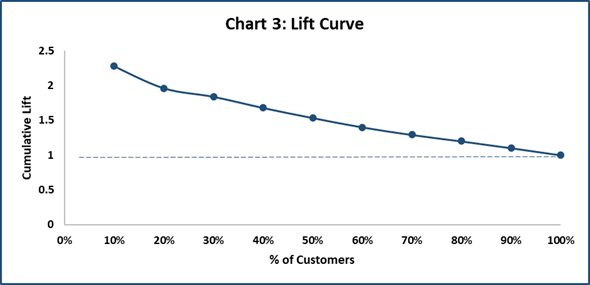
Image Source: Author
How to use Decile Analysis in business decision making:
Now that we have done building Decile Analysis, the next pertinent question is how we use it to make effective business decisions:
Let us revisit our Decile Analysis Table
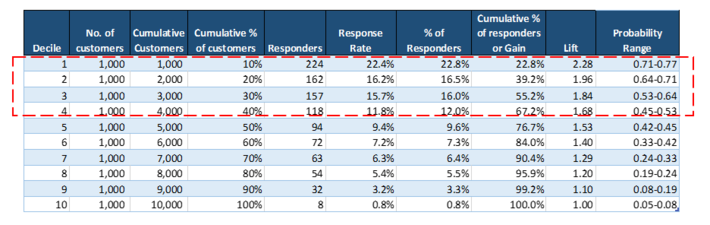
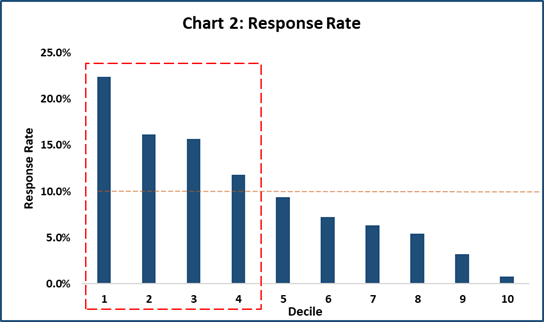
Image Source: Author
Going by the above results, we make a decision that we will target customers in the Top 4 deciles as they have higher probability of buying the product.
From the business point of view, the ROI of targeting the Top 4 deciles is more. As we move down the decile, the ROI rapidly decreases and is not worthwhile pursuing these customers.
So, that wraps up this decile analysis article. Your comments are welcome.
References:
{kind=link}