
This is the last – for now – installment of my mini-series on sentiment analysis of the Stanford collection of IMDB reviews (originally published on recurrentnull.wordpress.com).
So far, we’ve had a look at classical bag-of-words models and word vectors (word2vec).
We saw that from the classifiers used, logistic regression performed best, be it in combination with bag-of-words or word2vec.
We also saw that while the word2vec model did in fact model semantic dimensions, it was less successful for classification than bag-of-words, and we explained that by the averaging of word vectors we had to perform to obtain input features on review (not word) level.
So the question now is: How would distributed representations perform if we did not have to throw away information by averaging word vectors?
Document vectors: doc2vec
Shortly after word2vec, Le and Mikolov developed paragraph (document) vector models.
The basic models are
- Distributed Memory Model of Paragraph Vectors (PV-DM) and
- Distributed Bag of Words (PV-DBOW)
In PV-DM, in addition to the word vectors, there is a paragraph vector that keeps track of the whole document:
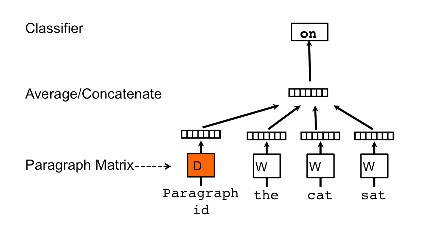
Fig.1: Distributed Memory Model of Paragraph Vectors (PV-DM) (from: Distributed Representations of Sentences and Documents)
With distributed bag-of-words (PV-DBOW), there even aren’t any word vectors, there’s just a paragraph vector trained to predict the context:
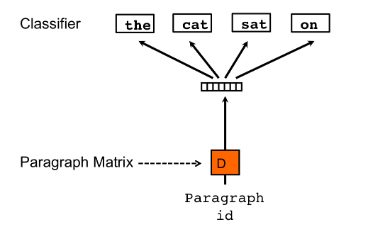
Fig.2: Distributed Bag of Words (PV-DBOW) (from: Distributed Representations of Sentences and Documents)
Like word2vec, doc2vec in Python is provided by the gensim library. Please see the gensim doc2vec tutorial for example usage and configuration.
doc2vec: performance on sentiment analysis task
I’ve trained 3 models, with parameter settings as in the above-mentioned doc2vec tutorial: 2 distributed memory models (with word & paragraph vectors averaged or concatenated, respectively), and one distributed bag-of-words model. Here, without further ado, are the results. I’m just referring results for logistic regression as again, this was the best-performing classifier:
| test vectors inferred | test vectors from model | |
|---|---|---|
| Distributed memory, vectors averaged (dm/m) | 0.81 | 0.87 |
| Distributed memory, vectors concatenated (dm/c) | 0.80 | 0.82 |
| Distributed bag of words (dbow) | 0.90 | 0.90 |
Hoorah! We’ve finally beaten bag-of-words … but only by a tiny little 0.1 percent, and we won’t even ask if that’s significant 😉
What should we conclude from that? In my opinion, there’s no reason to be sarcastic here (even if you might have thought I’d made it sound like that ;-)). With doc2vec, we’ve (at least) reached bag-of-words performance for classification, plus we now have semantic dimensions at our disposal. Speaking of which – let’s check what doc2vec thinks is similar to awesome/awful. Will the results be equivalent to those had with word2vec?
These are the words found most similar to awesome (note: the model we’re asking this question isn’t the one that performed best with Logistic Regression (PV-DBOW), as distributed bag-of-words doesn’t train word vectors, – this is instead obtained from the best-performing PV-DMM model):
model.most_similar('awesome', topn=10) [(u'incredible', 0.9011116027832031), (u'excellent', 0.8860622644424438), (u'outstanding', 0.8797732591629028), (u'exceptional', 0.8539372682571411), (u'awful', 0.8104138970375061), (u'astounding', 0.7750493884086609), (u'alright', 0.7587056159973145), (u'astonishing', 0.7556235790252686), (u'extraordinary', 0.743841290473938)]
So, what we see is very similar to the output of word2vec – including the inclusion of awful. Same for what’s judged similar to awful:
model.most_similar('awful', topn=10) [(u'abysmal', 0.8371909856796265), (u'appalling', 0.8327066898345947), (u'atrocious', 0.8309577703475952), (u'horrible', 0.8192445039749146), (u'terrible', 0.8124841451644897), (u'awesome', 0.8104138970375061), (u'dreadful', 0.8072893023490906), (u'horrendous', 0.7981990575790405), (u'amazing', 0.7926105260848999), (u'incredible', 0.7852109670639038)]
To sum up – for now – we’ve explored how three models: bag-of-words, word2vec, and doc2vec – perform on sentiment analysis of IMDB movie reviews, in combination with different classifiers the most successful of which was logistic regression. Very similar (around 10% error rate) performance was reached by bag-of-words and doc2vec.
From this you may of course conclude that as of today, there’s no reason not to stick with the straightforward bag-of-words approach.But you could also view this differently. While word2vec appeared in 2013, it was succeeded by doc2vec already in 2014. Now it’s 2016, and things have happened in the meantime, are happening at present, right now. It’s a fascinating field, and even if – in sentiment analysis – we don’t see impressive output yet, impressive output is quite likely to appear sooner or later. I’m curious what we’re going to see!
:%20doc2vec){kind=link}