
Summary: In the first part of this series we described the basics of Reinforcement Learning (RL). In this article we describe how deep learning is augmenting RL and a variety of challenges and considerations that need to be addressed in each implementation.
 In the first part of this series, Understanding Basic RL Models we described the basics of how reinforcement learning (RL) models are constructed and interpreted.
In the first part of this series, Understanding Basic RL Models we described the basics of how reinforcement learning (RL) models are constructed and interpreted.
RL systems can be constructed using policy gradient techniques which attempt to learn by directly mapping an observation to an action (the automated house look up table). Or they can be constructed using Q-Learning in which we train a neural net to calculate the estimated Q factor on the fly which is used when the state space gets large and complex.
The Q factor is the maximum discounted future reward when we perform action a in state s. The Q-function Q(s,a) is interpreted as the ‘policy’ for what action to take next given state a.
RL systems do not require neural nets but increasingly the most interesting problems like game play and self-driving cars represent such large and complex state spaces that the direct observation policy gradient approach is not practical.
These Q-Learning situations are also frequently defined by their use of images (pixel fields) as unlabeled inputs which are classified using a convolutional neural net (CNN) with some differences from standard image classification.
In this article we’ll describe Q-Learning at a basic level and devote more time to exploring other practical complexities and challenges to implementing RL systems.
Four Examples We’ll Use
To illustrate our points we’ll use these four hypothetical applications.
The Automated House: Actuators would include at least heating and cooling systems, light switches, and blinds. Sensors would include a thermometer, fire and smoke detectors, motion detectors and cameras, and of course a clock and calendar. In our example we’ll limit ourselves to the goal of just trying to get the temperature right.
Self-Driving Cars: This could be any physical robot but self-driving cars are the most talked about. They typically have three systems that work together: 1.) an internal map allowing the car to place itself in space (on a road), 2.) a method of using that map to determine the best route to your destination, and most relevant to us 3.) a system of obstacle avoidance where RL is of most importance. Actuators are brakes, throttle, and steering angle inputs. Sensors are typically GPS, inertial navigation, video, LIDAR/radar, and rangefinders. The goal, get from A to B safely.
Chess: A lot can be learned about RL from dissecting the automation of game play. Actuators are simply the legal rules-based moves made in allowed sequence. Sensor is simply the location of each piece on the board following each move – the current state of the ‘world’. The goal, win the game.
Pong: Yes good ol’ Atari Pong in which you compete with an AI to bounce the ball past the other player. The actuator is moving the paddle up or down to connect with the ball. The sensor is whether the ball passes by your opponent or by you to score. The goal is to reach 21 before your opponent.
Q-Learning Basics
Of our sample problems, Pong and self-driving cars clearly have image based pixel inputs and very large and complex state spaces. Chess could be approached as a table-based problem or an image based problem, either would work. The automated house is simple enough that Q-Learning is probably not necessary.
The breakthrough that the Q-Learning approach represents should not be under estimated. DeepMind, now part of Google was the primary innovator in this area training RL systems to play Atari games better than humans. That is not to say that there is a single approach. At this developmental point in RL application the literature is full of various tips and tricks that actually make this work. In very simplified form however, here are the basics.
The actual implementation of a CNN to estimate the Q factor for each state/action pair is fairly straightforward except: It might seem most logical to create a CNN that accepts state and action pair inputs and outputs a single Q factor for that (s,a) pair (called the ‘on-policy’ approach). However, one of the clever work arounds that DeepMind discovered is to build a CNN that just accepts a state, and outputs separate Q-values for each possible action (called ‘off policy’ approach).
This is very efficient since we don’t need to run the network forward for every action to get all the possible Q-values, just once to get the spread of Q-values from which we can select a maxQ(s,a). Still, we start with a random seed, and several thousand epochs later, if we’re good, we’re approaching a trained CNN.
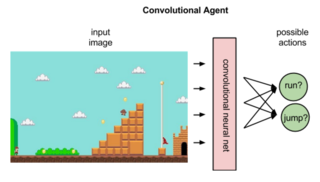 Also, although we’re using a CNN as an image classifier, this is not image classification in the sense you may be used to. We are training the CNN to output an action, not whether the image is a cat or a dog.
Also, although we’re using a CNN as an image classifier, this is not image classification in the sense you may be used to. We are training the CNN to output an action, not whether the image is a cat or a dog.
As with normal image classification, by the time the image is processed through several convolutional and pooling steps it will not be recognizable to a human interpreter. That may very well be a child darting out from between cars that caused the Q-value driven action, but neither the RL system nor a human observer would be able to tell that was true.
Short Term Goals versus Long Term Goals
In the case of the automated house the short and long term goals are the same. In this example from our last article the temperature sensor was evaluated every 10 minutes against the goal temperature and this cycle simply iterates over and over. However in the case of game play like Chess or Pong, the strength of a single immediate move must be weighed against its overall effect on winning the game.
This means that the ‘score’ for the current learning cycle (the move in chess or the ball strike in pong) has to be evaluated twice and the second time may be many moves removed into the future.
It also means that although your current move may be scored as a win, if you lose the game then all the related scores for the moves in that game may be scored as a loss causing all those moves, strong and weak, to be ignored in future learning. If there are a great many moves between a scored win or loss then a great deal of experience may be lost as well.
The effect is to stretch out the required time to train to thousands or even millions of iterations. However, in the long run this long term view is effective so that only strong moves made in the context of a winning game are used for learning. Solutions to this problem are in the realm of temporal difference learning.
On the topic of goals, it’s also possible to add complexity and thereby require more training by having multiple goals. For example, Mobileye is trying to adjust its RL self-driving systems so that not only is the accident avoided but also so that the action isn’t likely to create a separate accident for the cars around it.
Improving Learning Speeds With Penalties as Well as Rewards
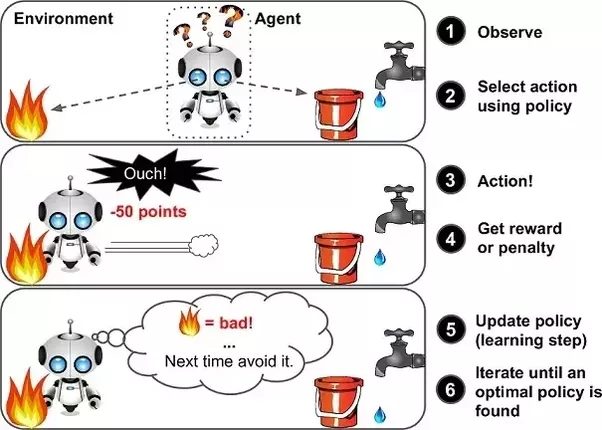 In our automated house example, whenever the desired behavior was achieved we scored it a ‘1’, a win, in our table. However, it’s easy to see how we could speed up the process and improve the probability table if we also penalized the RL system for making the wrong choice.
In our automated house example, whenever the desired behavior was achieved we scored it a ‘1’, a win, in our table. However, it’s easy to see how we could speed up the process and improve the probability table if we also penalized the RL system for making the wrong choice.
For example, in Pong a score is generated every time the ball moves toward us and strikes or fails to strike the paddle but the strength of that play is only important if we succeed in getting the ball past our opponent. If we do, that move gets a ‘1’. If the AI opponent counters our move and returns the ball, we award our move a ‘0’. However, if the AI opponent countered our move and scored against us, we could award a penalty ‘-1’ to better differentiate the value of our move.
Similarly in self-driving cars, if the object avoidance RL keeps the car centered in the roadway that would be a ‘1’, a win. However we could award several degrees of penalty (e.g. -1, -2, -3) depending on how far from the intended goal we judged that steering input.
Does It Generalize
The game of Checkers has 500 Billion Billion potential moves. The number of potential moves in Chess has been calculated to be 10^120. That might just be within our computational capability to evaluate every single move possible but the reality is that when learning by experience we’re not going to examine every potential move, only those that are most common.
When you extend this logic to self-driving cars and the goal of object avoidance using multiple sensor inputs, then clearly, only those that the system has experienced will be in the memory table.
In RL, similar to the much simpler problem experienced with A/B testing or the slightly more complex multi-arm bandit strategy for ad presentation, it’s tempting to go with what’s working. That is if the system has seen the situation sufficiently often to have a strong probability in its table, then go with it.
However, we always need to ask, does it generalize? Have we really seen everything? And the answer in any system that is ‘sampled’ is inevitably a qualified no. The partial solution to this ‘exploration versus exploitation’ problem is a factor in the RL agent typically called the ‘greedy theta (Ɵ)’. Greedy theta lets us adjust the rate at which the RL continues to explore instead of simply accept the most common already seen result.
As the number of variables to be considered increases, the number of actuators, sensors, and even multiple overlapping goals increases RL systems fall prey to the same sort of combinatorial explosion seen in classical statistical modeling. RL works best where dimensionality can be limited putting a premium on feature extraction and dimensionality reduction.
RL Systems Have No Imagination
RL systems may learn to navigate or operate a system with known limits in a manner far superior to humans, whether that’s a car, a spacecraft, or a fusion reactor. But faced with an input they have never seen before with no entry in the table or computable Q-value, they will always fail. This can be a simple under-sampling problem or more likely a situation identified as the problem of non-stationary environments, where discontinuities with the past occur often or at a rate too fast for training to recognize or keep up.
Don’t Change Those Actuators or Sensors
This extends not only to novel environments (ice on the road, the child darting from between cars) but also to any changes in their actuators or sensors.
The actuator and sensor issue is particularly sensitive in self-driving cars which is why developers have been selecting to work with only one or two models of vehicles. In object avoidance for example, the steering angle inputs, as well as brakes and throttle would be particularly sensitive to the characteristics of the particular car, its mass, the distribution of that mass, its center of gravity, etc. So you could not take the object avoidance routine from a sports car and apply it directly to a minivan. In system design, we would say these systems are brittle since, although they learn, they don’t tolerate changes to the actuators, sensors, or even previously unseen cases.
How Much Training is Necessary
We started with the premise the RL systems are magical because you can make them work without training data. In practice that’s not entirely true. You may not have labeled training data but the systems still need time to learn.
In the case of the automated house the external temperatures are repeatably stable on an annual cycle and most temperature adjustments will be limited to within a few degrees of what most people find comfortable. Given that, you could probably deploy with a year’s data especially since the penalty for getting the answer wrong is not particularly high.
In the cases of Chess or Pong however the alternative moves represent a much larger number so much more training will be required. This also illustrates whether training can be conducted on multiple platforms and then combined.
In Chess and Pong, the answer is undoubtedly yes, the games are always uniform. In the case of the Automated House, maybe. The physical characteristics of each house, internal volume, insulation, power of the heater, and external characteristics like geographic location are likely to be quite different. Faced with this problem you might choose to combine the tables or Q-Learning of many different houses to get started but accept that those probabilities will need to be adjusted based on experience with the actual house to be controlled.
This is the problem at work that keeps us from having self-driving cars today. The amount of training and the complexity introduced by multiple sensors is staggeringly large. The major developers have all deployed fleets of test vehicles to build up their experience tables. Recently some developers have also taken to video gaming to train. It turns out that the game Grand Theft Auto is sufficiently realistic to use as a training simulator to build up RL probability tables. Not that they want their self-driving car to respond that way in real life.
Like the house example, some aggregation of experience tables could be used if the vehicles were physically similar. Curiously the one area where sharing would be quite valuable is still a stumbling block for self-driving cars, simultaneous localization and mapping (SLAM to the engineers working on the problem).
Sharing information car to car about immediate changes in road conditions such as the construction caused lane closure or the garbage can sitting in the middle of the residential street would be enormously valuable. It would also allow self-driving cars to do a bit of negotiation when they encounter one another, for example when merging. The reality is that all this data is considered confidential for each manufacturer and it’s one area where a little early regulatory intervention might actually help.
How Often Should the RL System Learn and Update
In the design of an RL system you might think this would be easy. For Chess, it is after each move. For Pong, after each paddle strikes or fails to strike the ball. For the automated house the 10 minute update is probably reasonable. But for the self-driving car the system must update many times per second.
To add to the complexity, at 60 mph the car is moving 88 ft./second and at 20 mph only 29 ft./second (a little over one car length per second). However, the available actuators (brakes, steering angle input, and throttle) can’t be used the same way at 60 as at 20. At freeway speeds there is no practical way within the rules of physics to avoid an obstacle that suddenly appears two car lengths ahead (the chair that fell off the truck ahead). At 20 mph however your inputs can be more radical in terms of close-in obstacle avoidance so the system may actually need to cycle more frequently at lower speed, or at least be constrained not to make any radical actuator changes at 60 mph. So the answer is as often as is necessary to make a good sequence of decisions.
Finally
This article was intentionally more about raising questions than offering definitive solutions. As with any complex technology that is just emerging, the challenges are significant and the amount of creativity being applied by leading edge adopters is very impressive. These two articles taken together along with our introductory article are intended to give you a fairly quick lay of the land. Now you can dive in wherever your interest leads you.
Other Articles in this Series
Under the Hood with Reinforcement Learning – Understanding Basic RL Models
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist since 2001. He can be reached at:
{kind=link}