
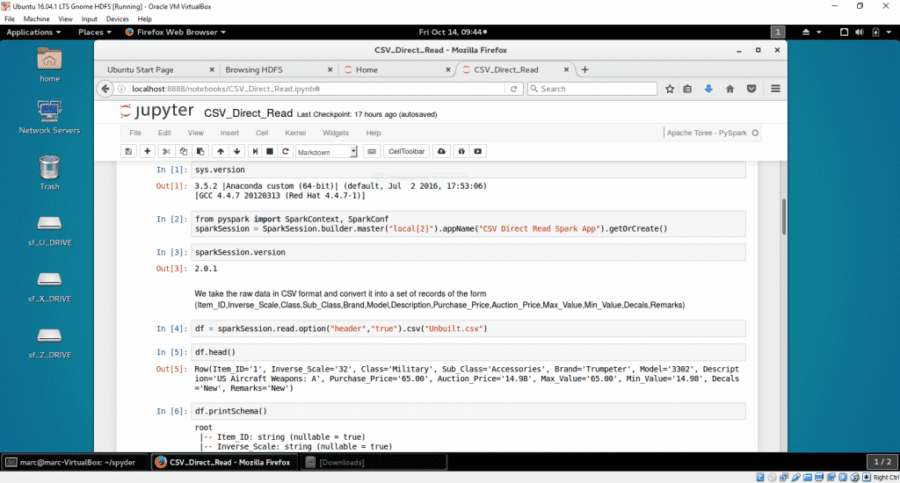
Recently, in a previous post, we reviewed a path to leverage legacy Excel data and import CSV files thru MySQL into Spark 2.0.1. This may apply frequently in businesses where data retention did not always take the database route… However, we demonstrate here that the same result can be achieved in a more direct fashion. We’ll illustrate this on the same platform that we used last time (Ubuntu 16.04.1 LTS running in a windows VirtualBox Hadoop 2.7.2 and Spark 2.0.1) and on the same dataset (my legacy model collection Unbuilt.CSV). Our objective is to show how to migrate data to Hadoop HDFS and analyze it directly and interactively using the latest ML tools with PySpark 2.0.1 in a Jupyter Notebook.
A number of interesting facts can be deduced thru the combination of sub-setting, filtering and aggregating this data, and are documented in the notebook. For example, with one-liner, we can rank the most popular scale, the most numerous model, and the most valued items, tally models by categories,… and process this legacy data with modern ML tools. Clustering is obtained just as easily, on scaled data, as illustrated here.
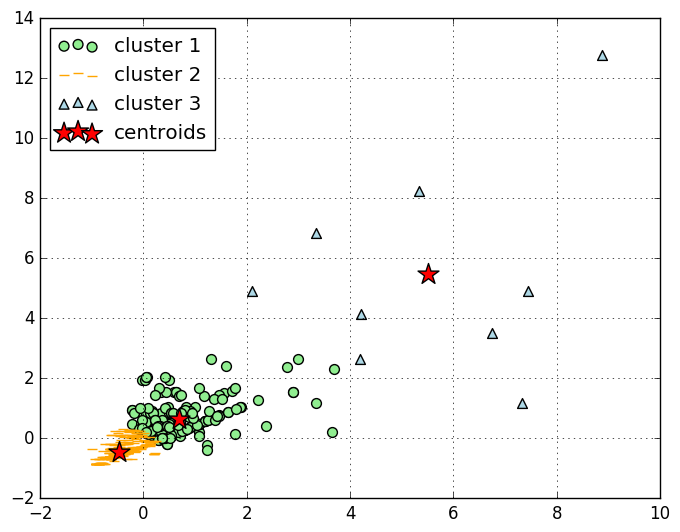
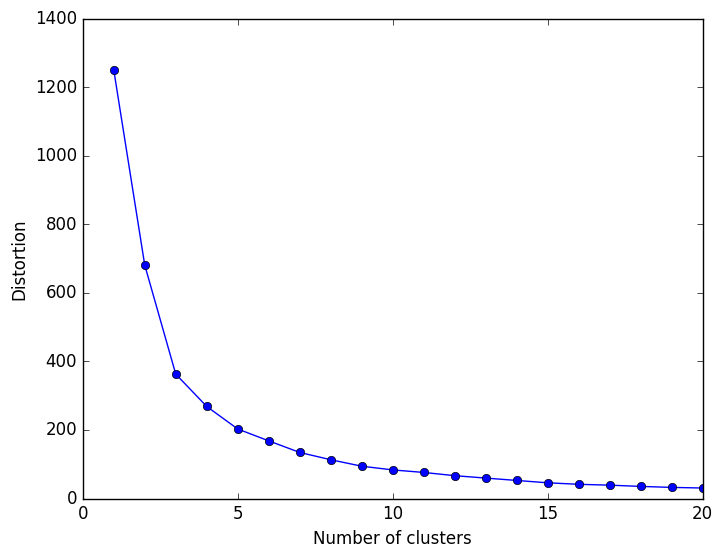
This, again, should serve the purpose of demonstrating direct migration of legacy data. We reviewed how to access using PySpark from Jupyter notebook and leverage the interactive interface provided by Toree / Spark 2.0.1.
A Jupyter notebook is also provided to help along your migration…
We can restate that there’s really no need to abandon legacy data: Migrating directly or indirectly data to new platform will enable businesses to extract and analyze that data on a broader time scale, and open new ways to leverage ML techniques, analyze results and act on findings.
){kind=link}