
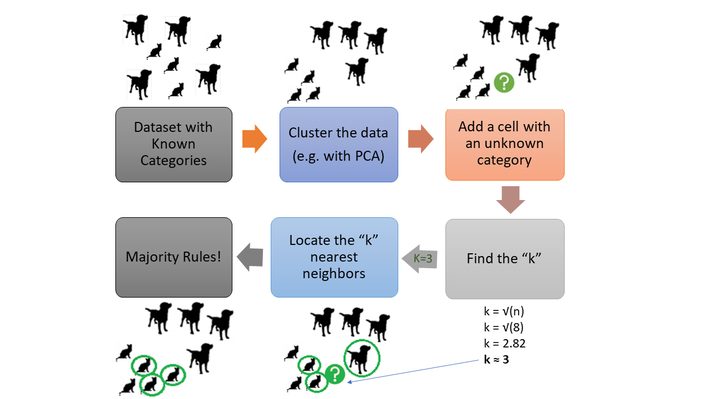
This is a simple overview of the k-NN process. Perhaps the most challenging step is finding a k that’s “just right”. The square root of n can put you in the ballpark, but ideally you should use a training set (i.e. a nicely categorized set) to find a “k” that works for your data. Remove a few categorized data points and make them “unknowns”, testing a few values for k to see what works.
DSC Resources
- Free Book and Resources for DSC Members
- New Perspectives on Statistical Distributions and Deep Learning
- Time series, Growth Modeling and Data Science Wizardy
- Statistical Concepts Explained in Simple English
- Machine Learning Concepts Explained in One Picture
- Comprehensive Repository of Data Science and ML Resources
- Advanced Machine Learning with Basic Excel
- Difference between ML, Data Science, AI, Deep Learning, and Statistics
- Selected Business Analytics, Data Science and ML articles
- How to Automatically Determine the Number of Clusters in your Data
- Fascinating New Results in the Theory of Randomness
- Hire a Data Scientist | Search DSC | Find a Job
- Post a Blog | Forum Questions
{kind=link}