
Summary: There is a great hue and cry about the danger of bias in our predictive models when applied to high significance events like who gets a loan, insurance, a good school assignment, or bail. It’s not as simple as it seems and here we try to take a more nuanced look. The result is not as threatening as many headlines make it seem.
 Is social bias in our models a threat to equal and fair treatment? Here’s a sample of recent headlines:
Is social bias in our models a threat to equal and fair treatment? Here’s a sample of recent headlines:
- Biased Algorithms Are Everywhere, and No One Seems to Care
- Researchers Combat Gender and Racial Bias in Artificial Intelligence
- Bias in Machine Learning and How to Stop It
- AI and Machine Learning Bias Has Dangerous Implications
- AI Professor Details Real-World Dangers of Algorithm Bias
- When Algorithms Discriminate
Holy smokes! The sky is falling. There’s even an entire conference dedicated to the topic: the conference on Fairness, Accountability, and Transparency (FAT* – it’s their acronym, I didn’t make this up) now in its fifth year.
But as you dig into this topic it’s a lot more nuanced. As H.L. Mencken said, “For every complex problem there is a simple solution. And it’s always wrong.”
Exactly What Type of Bias are We Talking About?
There are actually many different types of bias. Microsoft identifies five types: association bias, automation bias, interaction bias, confirmation bias, and dataset bias. Others use different taxonomies.
However, we shouldn’t mix up socially harmful bias that can have a concrete and negative impact on our lives (who gets a loan, insurance, a job, a house, or bail) for types of bias based on our self-selection, like what we choose to read or who we elect to friend. It’s the important stuff we want to focus on.
How Many Sources of Bias in Modeling Are There?
First, we’re not talking about the academic and well understood tradeoff between bias and variance. We’re talking about what causes models to be wrong, but with a high degree of confidence for some subsets of the population.
It’s Not the Type of Model That’s Used
Black box models, which mean ANNs of all stripes and particularly deep neural nets (DNNs) are constantly being fingered as a culprit. I’ll grant you that ANNs in general and particularly those used in AI for image, text, and facial recognition generally lack sufficient transparency to describe exactly why a specific person was scored as accepted or rejected by the model.
But the same is true of boosted, deep forest, ensembles, or many other techniques. Right now, only CNNs and RNN/LSTMs are being used in AI applications but there are no examples I could find of systems using these models which have actually been widely adopted and are causing harm.
Yes, some DNNs did categorize people of color as gorillas but no one is being denied a valuable human or social service based on that type of system. We recognized the problem before it impacted anyone. It’s the good old ‘customer preference’ scoring models that pick winners and losers where we need to look.
The important thing to understand is that even using the most transparent of GLM and simple decision tree models as our regulated industries are required to do, bias can still sneak in.
Costs and Benefits
Remember that the value of using more complex if less transparent techniques is increased accuracy. That means lower cost, greater efficiency, and even the elimination of some types of hidden human bias.
We’ve decided as a society that we want our regulated industries, primarily insurance and lending to use simple and completely explainable models. We intentionally gave up some of this efficiency.
While transparency has been agreed to be of value here, don’t lose sight of the fact that this explicitly means that some individuals are paying more than they have to, or less than they should if the risks and rewards were more accurately modeled.
Since we mentioned how models can eliminate some types of hidden human bias, here’s a short note on a 2003 study that showed that when recruiters were given identical resumes to review, they selected more applicants with white-sounding names. When reviewing resumes with the names redacted but selected by the algorithm as potential good hires, the bias was eliminated. So perhaps as often as algorithms can introduce bias, they can also protect against it.
The Problem Is Always in the Data
 If there were enough data that equally represented outcomes for each social characteristic we want to protect (typically race, gender, sex, age, and religion in regulated industries) then modeling could always be fair.
If there were enough data that equally represented outcomes for each social characteristic we want to protect (typically race, gender, sex, age, and religion in regulated industries) then modeling could always be fair.
Sounds simple but it’s actually more nuanced than that. It requires that you first define exactly what type of fairness you want. Is it by representation? Should each protected group be represented in equal numbers (equal parity) or proportionate to their percentage in the population (proportional parity/disparate impact)?
Or are you more concerned about the impact of the false positives and false negatives that can be minimized but never eliminated in modeling?
This is particularly important if your model impacts a very small percentage of the population (e.g. criminals or people with uncommon diseases). In which case you have to further decide if you want to protect from false positives or false negatives, or at least have parity in these occurrences for each protected group.
IBM, Microsoft, and others are in the process of trying to provide tools to detect different types of bias, but the Center for Data Science and Public Policy at University of Chicago has already released an open source toolkit called Aequitas which can evaluate models for bias. They offer this decision tree for deciding which type of bias you want to focus on (it probably is not possible to solve for all four types and six variations at once). 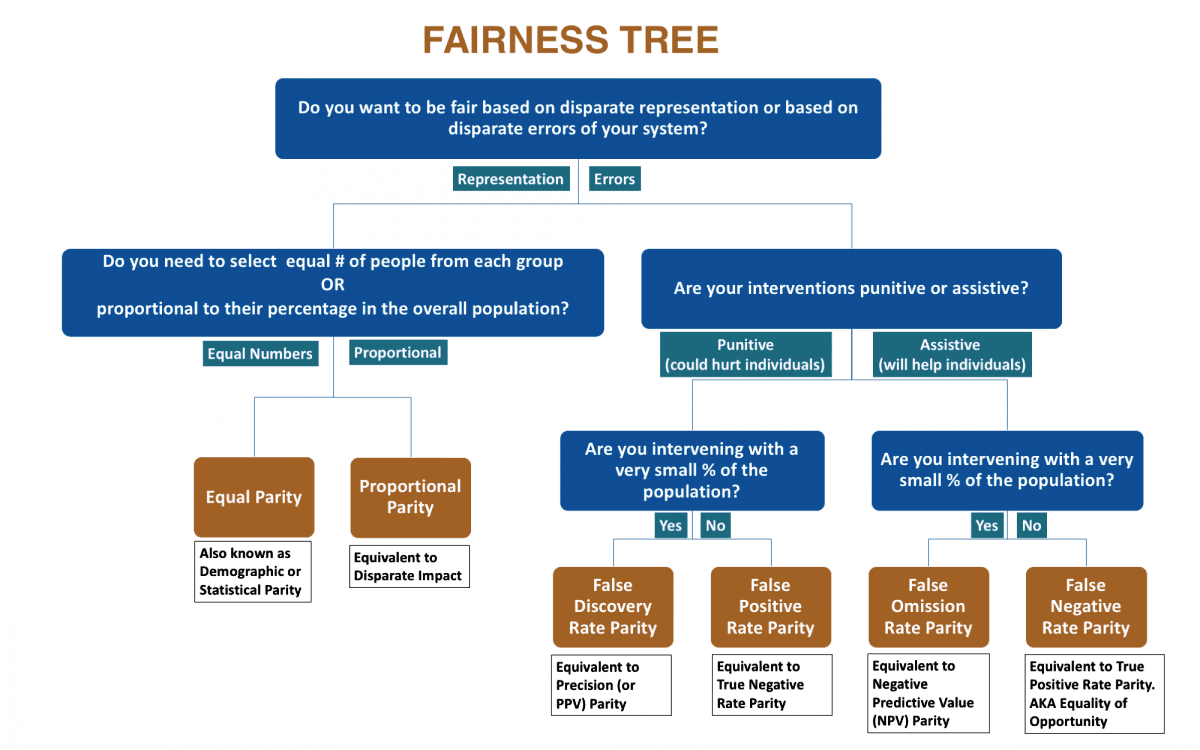
Too often the press and even some well-educated pundits have suggested radical solutions that simply don’t take these facts into consideration. For example, the AI Now Institute published this recommendation as first among its 10 suggestions.
“Core public agencies, such as those responsible for criminal justice, healthcare, welfare, and education (e.g. “high stakes” domains) should no longer use ‘black box’ AI and algorithmic systems.”
Their suggestion: submit any proposed model to field proof testing not unlike that used before drugs are allowed to be prescribed by the FDA. Delay benefit maybe, but for just how long and at what cost to conduct these tests. And what about model drift and refresh?
Before we consider such radical steps, we need to think through the utility these systems are providing, what human biases they are eliminating, and specifically what type of bias we want to protect against.
Having said that, this organization along with others is onto something when they point the finger at public agencies.
Where Are We Most Likely to be Harmed?
In addition to reviewing the literature I also called up some friends responsible for modeling in regulated industries, specifically insurance and lending. I’ll talk more about that a little further down but I came away with the very strong impression that where we’ve defined ‘regulated’ industries for modeling purposes, defined specifically what data they can and cannot use, and then made them accountable to typically state-level agencies who review these issues, that bias is a very small problem.
We Need to Watch Out for Unregulated Industries – The Most Important of Which are Public Agencies
This is not a pitch to extend data regulation to lots of other private sector industries. We’ve already pretty much covered that waterfront. Turns out that the sort of “high stakes” domains referred to above are pretty much all in the public sector.
Since the public sector isn’t known for investing heavily in data science talent this leaves us with the double whammy of high impact and modest insight into the problem.
However, using examples called out by these sources does not necessarily show that the models these agencies use are biased. In many cases they are simply wrong in their assumptions. Two examples called out by the AI Now Institute in fact date back three and four years and don’t clearly show bias.
Teacher Evaluation: This is a controversial model currently being litigated in court in NY that rates teachers based on how much their students have progressed (student growth percent). Long story short, a teacher on Long Island regularly rated highly effective was suddenly demoted to ineffective based on the improvement rate of her cohort of students but outside of her control. It’s a little complicated but it smacks of bad modeling and bad assumptions, not bias in the model.
Student School Matching Algorithms: Good schools have become a scarce resource sought after by parents. The nonprofit IIPSC created an allocation model used to assign students to schools in New York, Boston, Denver, and New Orleans. The core is an algorithm that generates one best school offer for every student.
The model combines data from three sources: The schools families actually want their children to attend, listed in order of preference; the number of available seats in each grade at every school in the system; and the set of rules that governs admission to each school.
From the write-up this sounds more like an expert system than a predictive model. Further, evidence is that it does not improve the lot of the most disadvantaged students. At best the system fails transparency. At worst the underlying model may be completely flawed.
It also illustrates a risk unique to the public sector. The system is widely praised by school administrators since it dramatically decreased the work created by overlapping deadlines, multiple applications, and some admissions game playing. So it appears to have benefited the agency but not necessarily the students.
COMPAS Recidivism Prediction: There is one example of bias we can all probably agree on from the public sector and that’s COMPAS, a predictive model widely used in the courts to predict who will reoffend. Judges across the United States use COMPAS to guide their decisions about sentencing and bail. A well-known study showed that the system was biased against blacks but not in the way you might expect.
COMPAS was found to correctly predict recidivism for black and white defendants at roughly the same rate. However the false positive rate for blacks was almost twice as high for blacks as for whites. That is, when COMPAS was wrong (predicted to reoffend but did not) it did so twice as often for blacks. Interestingly it made a symmetrical false negative prediction for whites (predicted not to reoffend but did).
Curiously these were the only three examples offered for risk in the public sector, only one of which seems to be legitimately a case of modeling bias. However, given the expansion of predictive analytics and AI, the public sector as a “high stakes” arena for our personal freedoms looks like a good place for this discussion to begin.
How Regulated Industries Really Work
Space doesn’t allow a deep dive into this topic but let’s start with these three facts:
- Certain types of information are off limits for modeling. This includes the obvious protected categories, typically race, gender, sex, age, and religion. This extends to data which could be proxies for these variables like geography. I’m told that these businesses also elect not to use variables that might look like ‘bad PR’. These include variables such as having children or lifestyle patterns like LGBTQ even though these are probably correlated with different levels of risk.
- Modeling techniques are restricted to completely transparent and explainable simple techniques like GLM and simple decision trees. Yes that negatively impacts accuracy.
- State agencies like the Department of Insurance can and do question the variables chosen in modeling. In business like insurance in most states they have the authority to approve profit margin ranges for the company’s total portfolio of offerings. In practice this means that some may be high and others may be loss-leaders but competition levels this out in the medium time frame.
What doesn’t occur is testing for bias beyond these regulated formulas and restrictions. There’s no specific test for disparate impact or for bias in false positives or false negatives. The regulation is presumed to suffice backed up by the fact that there are no monopolies here, and competition rapidly weeds out the outliers.
Similarly you may have wondered about equal parity or proportionate parity testing. It’s just not possible. An insurance company for example will have dozens of policy programs each targeting some subset of the population where they believe there is competitive advantage.
So long as those targeted subsets don’t encroach on the protected variables they are OK. So for example, it’s perfectly OK to have a policy aimed at school teachers and another at a city-wide geography in a city dominated by blue collar manufacturing. There’s no way to correctly test for parity in these examples since they are designed to be demographically unique.
How Much Bias is Too Much Bias?
You may be interested to know that the government has already ruled on this question, and while there are somewhat different rules used in special circumstance, the answer is 80%.
The calculation is simple, if you hired 60% of the applicants in an unprotected class and 40% in a protected class the calculation is 40/60 or 66% and does not meet the 80% threshold. But 40% versus 50% would be calculated as 80% and would meet the requirement.
This rule dates back to 1971 when the State of California Fair Employment Practice Commission (FEPC) assembled a working group of 32 professionals to make this determination. By 1978 it was codified at the federal level by the EEOC and the DOJ for Title VII enforcement.
So Is Bias in Modeling Really a Problem?
Well yes and no. Our regulated industries seem to be doing a pretty good job. Not perhaps up to the statistical standards of data science. They don’t guard against all four types of bias identified by the University of Chicago, but from a practical standpoint, there are not a lot of complaints.
The public sector as a “high stakes” arena deserves our attention, but of the limited number of examples put forth to prove bias, only one, COMPAS clearly illustrates a statistical bias problem.
Still, given the rapid expansion of analytics and the limited data science talent in this sector, I vote for keeping an eye on it. Not however with the requirement to immediately stop using algorithms at all.
To paraphrase a well turned observation, if I evaluate the threat of modeling bias on a scale of 0 to 10, where 0 is the tooth fairy and 10 is Armageddon, I’m going to give this about a 2 until better proof is presented.
Other articles by Bill Vorhies.
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist since 2001. He can be reached at:
{kind=link}