

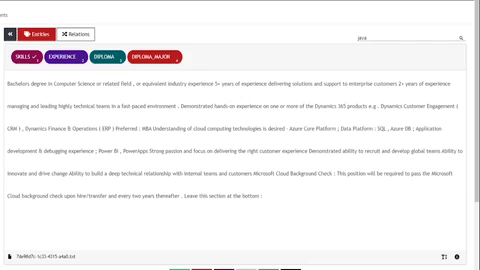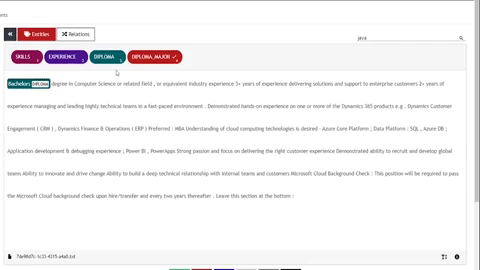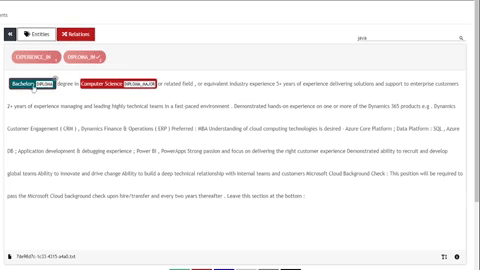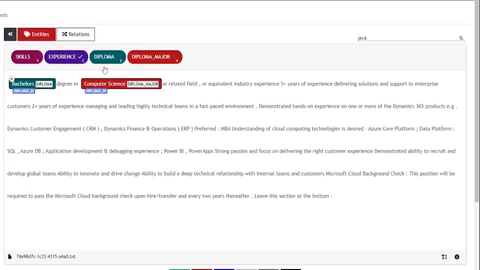
UBIAI’s joint entities and relation classification
For this tutorial, I have only annotated around 100 documents containing entities and relations. For production, we will certainly need more annotated data.
We repeat this step for the training, dev and test dataset to generate three binary spacy files (files available in github).
- Open a new Google Colab project and make sure to select GPU as hardware accelerator in the notebook settings. Make sure GPU is enabled by running: !nvidia-smi
- Install spacy-nightly: !pip install -U spacy-nightly –pre
- Install the wheel package and clone spacys relation extraction repo:
!pip install -U pip setuptools wheel
python -m spacy project clone tutorials/rel_component
- Install transformer pipeline and spacy transformers library:
!python -m spacy download en_core_web_trf
!pip install -U spacy transformers
- Change directory to rel_component folder: cd rel_component
- Create a folder with the name data inside rel_component and upload the training, dev and test binary files into it:
Training folder
- Open project.yml file and update the training, dev and test path:
train_file: “data/relations_training.spacy”dev_file: “data/relations_dev.spacy”test_file: “data/relations_test.spacy”
- You can change the pre-trained transformer model (if you want to use a different language, for example), by going to the configs/rel_trf.cfg and entering the name of the model:
[components.transformer.model]@architectures = "spacy-transformers.TransformerModel.v1"name = "roberta-base" # Transformer model from huggingfacetokenizer_config = {"use_fast": true}
- Before we start the training, we will decrease the max_length in configs/rel_trf.cfg from the default 100 token to 20 to increase the efficiency of our model. The max_length corresponds to the maximum distance between two entities above which they will not be considered for relation classification. As a result, two entities from the same document will be classified, as long as they are within a maximum distance (in number of tokens) of each other.
[components.relation_extractor.model.create_instance_tensor.get_instances]@misc = "rel_instance_generator.v1"max_length = 20
- We are finally ready to train and evaluate the relation extraction model; just run the commands below:
!spacy project run train_gpu # command to train train transformers
!spacy project run evaluate # command to evaluate on test dataset
You should start seeing the P, R and F score start getting updated:
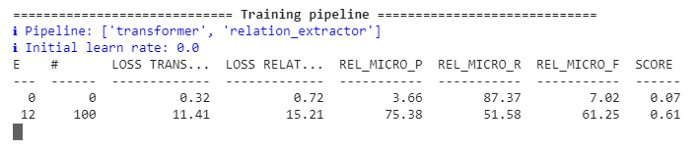
Model training in progress
After the model is done training, the evaluation on the test data set will immediately start and display the predicted versus golden labels. The model will be saved in a folder named training along with the scores of our model.
!spacy project run evaluate We can compare the performance of the two models:
“performance”:{“rel_micro_p”:0.8476190476,“rel_micro_r”:0.9468085106,“rel_micro_f”:0.8944723618,}
“performance”:{“rel_micro_p”:0.8604651163,“rel_micro_r”:0.7872340426,“rel_micro_f”:0.8222222222,}
- Install spacy transformers and transformer pipeline
- Load the NER model and extract entities:
import spacynlp = spacy.load("NER Model Repo/model-best")Text=['''2+ years of non-internship professional software development experience Programming experience with at least one modern language such as Java, C++, or C# including object-oriented design.1+ years of experience contributing to the architecture and design (architecture, design patterns, reliability and scaling) of new and current systems.Bachelor / MS Degree in Computer Science. Preferably a PhD in data science.8+ years of professional experience in software development. 2+ years of experience in project management.Experience in mentoring junior software engineers to improve their skills, and make them more effective, product software engineers.Experience in data structures, algorithm design, complexity analysis, object-oriented design.3+ years experience in at least one modern programming language such as Java, Scala, Python, C++, C#Experience in professional software engineering practices & best practices for the full software development life cycle, including coding standards, code reviews, source control management, build processes, testing, and operationsExperience in communicating with users, other technical teams, and management to collect requirements, describe software product features, and technical designs.Experience with building complex software systems that have been successfully delivered to customersProven ability to take a project from scoping requirements through actual launch of the project, with experience in the subsequent operation of the system in production''']for doc in nlp.pipe(text, disable=["tagger"]): print(f"spans: {[(e.start, e.text, e.label_) for e in doc.ents]}")
- We print the extracted entities:
spans: [(0, '2+ years', 'EXPERIENCE'), (7, 'professional software development', 'SKILLS'), (12, 'Programming', 'SKILLS'), (22, 'Java', 'SKILLS'), (24, 'C++', 'SKILLS'), (27, 'C#', 'SKILLS'), (30, 'object-oriented design', 'SKILLS'), (36, '1+ years', 'EXPERIENCE'), (41, 'contributing to the', 'SKILLS'), (46, 'design', 'SKILLS'), (48, 'architecture', 'SKILLS'), (50, 'design patterns', 'SKILLS'), (55, 'scaling', 'SKILLS'), (60, 'current systems', 'SKILLS'), (64, 'Bachelor', 'DIPLOMA'), (68, 'Computer Science', 'DIPLOMA_MAJOR'), (75, '8+ years', 'EXPERIENCE'), (82, 'software development', 'SKILLS'), (88, 'mentoring junior software engineers', 'SKILLS'), (103, 'product software engineers', 'SKILLS'), (110, 'data structures', 'SKILLS'), (113, 'algorithm design', 'SKILLS'), (116, 'complexity analysis', 'SKILLS'), (119, 'object-oriented design', 'SKILLS'), (135, 'Java', 'SKILLS'), (137, 'Scala', 'SKILLS'), (139, 'Python', 'SKILLS'), (141, 'C++', 'SKILLS'), (143, 'C#', 'SKILLS'), (148, 'professional software engineering', 'SKILLS'), (151, 'practices', 'SKILLS'), (153, 'best practices', 'SKILLS'), (158, 'software development', 'SKILLS'), (164, 'coding', 'SKILLS'), (167, 'code reviews', 'SKILLS'), (170, 'source control management', 'SKILLS'), (174, 'build processes', 'SKILLS'), (177, 'testing', 'SKILLS'), (180, 'operations', 'SKILLS'), (184, 'communicating', 'SKILLS'), (193, 'management', 'SKILLS'), (199, 'software product', 'SKILLS'), (204, 'technical designs', 'SKILLS'), (210, 'building complex software systems', 'SKILLS'), (229, 'scoping requirements', 'SKILLS')]
We have successfully extracted all the skills, number of years of experience, diploma and diploma major from the text! Next we load the relation extraction model and classify the relationship between the entities.
Note: Make sure to copy rel_pipe and rel_model from the scripts folder into your main folder:
Scripts folder
import random
import typerfrom pathlib
import Path
import spacy
from spacy.tokens import DocBin, Docfrom spacy.training.example import Examplefrom rel_pipe import make_relation_extractor, score_relationsfrom rel_model
import create_relation_model, create_classification_layer, create_instances, create_tensors
# We load the relation extraction (REL) model
nlp2 = spacy.load(“training/model-best”) # We take the entities generated from the NER pipeline and input them to the REL pipeline
doc = proc(doc)# Here, we split the paragraph into sentences and apply the relation extraction for each pair of entities found in each sentence. for value, rel_dict in doc._.rel.items():
for sent in doc.sents:
for e in sent.ents:
for b in sent.ents:
if e.start == value[0] and b.start == value[1]:
if rel_dict[‘EXPERIENCE_IN’] >=0.9 :
print(f” entities: {e.text, b.text} –> predicted relation: {rel_dict}”)
Here we display all the entities having a relationship Experience_in with confidence score higher than 90%: “entities”:
{“DEGREE_IN”:1.2778723e-07,”EXPERIENCE_IN”:0.9694631}“entities”:”(“”1+ years”, “contributing to the””) –>
predicted relation“:
{“DEGREE_IN”:1.4581254e-07,”EXPERIENCE_IN”:0.9205434}“entities”:”(“”1+ years”,”design””) –>
predicted relation“:
{“DEGREE_IN”:1.8895419e-07,”EXPERIENCE_IN”:0.94121873}“entities”:”(“”1+ years”,”architecture””) –>
predicted relation“:
{“DEGREE_IN”:1.9635708e-07,”EXPERIENCE_IN”:0.9399484}“entities”:”(“”1+ years”,”design patterns””) –>
predicted relation“:
{“DEGREE_IN”:1.9823732e-07,”EXPERIENCE_IN”:0.9423302}“entities”:”(“”1+ years”, “scaling””) –>
predicted relation“:
{“DEGREE_IN”:1.892173e-07,”EXPERIENCE_IN”:0.96628445}entities: (‘2+ years’, ‘project management’) –>
predicted relation:
{‘DEGREE_IN’: 5.175297e-07, ‘EXPERIENCE_IN’: 0.9911635}“entities”:”(“”8+ years”,”software development””) –>
predicted relation“:
{“DEGREE_IN”:4.914319e-08,”EXPERIENCE_IN”:0.994812}“entities”:”(“”3+ years”,”Java””) –>
predicted relation“:
{“DEGREE_IN”:9.288566e-08,”EXPERIENCE_IN”:0.99975795}“entities”:”(“”3+ years”,”Scala””) –>
predicted relation“:
{“DEGREE_IN”:2.8477e-07,”EXPERIENCE_IN”:0.99982494}“entities”:”(“”3+ years”,”Python””) –>
predicted relation“:
{“DEGREE_IN”:3.3149718e-07,”EXPERIENCE_IN”:0.9998517}“entities”:”(“”3+ years”,”C++””) –>
predicted relation“:
{“DEGREE_IN”:2.2569053e-07,”EXPERIENCE_IN”:0.99986637}
entities: (‘Bachelor / MS’, ‘Computer Science’) –> predicted relation: {‘DEGREE_IN’: 0.9943974, ‘EXPERIENCE_IN’:1.8361954e-09} entities: (‘PhD’, ‘data science’) –> predicted relation: {‘DEGREE_IN’: 0.98883855, ‘EXPERIENCE_IN’: 5.2092592e-09}
This again demonstrates how easy it is to fine tune transformer models to your own domain specific case with low amount of annotated data, whether it is for NER or relation extraction.
With only a hundred of annotated documents, we were able to train a relation classifier with good performance. Furthermore, we can use this initial model to auto-annotate hundreds more of unlabeled data with minimal correction. This can significantly speed up the annotation process and improve model performance.
If you need data annotation for your project, dont hesitate to try out UBIAI annotation tool. We provide numerous programmable labeling solutions (such as ML auto-annotation, regular expressions, dictionaries, etc¦) to minimize hand annotation.
If you have any comment, please email at [email protected]!
{kind=link}