
Written by Andy Palmer, CEO of Tamr
Why It’s Time to Embrace “DataOps” as a New Discipline
Over the past 10 years, many of us in technology companies have experienced the emergence of “DevOps.” This new set of practices and tools has improved the velocity, quality, predictability and scale of software engineering and deployment. Starting at the large internet companies, the trend towards DevOps is now transforming (albeit slowly) the way that systems are developed and managed inside the enterprise — often dovetailing with enterprise cloud adoption initiatives.
Regardless of your opinion about on-prem vs. multi-tenant cloud infrastructure, the adoption of DevOps is undeniably improving how quickly new features and functions are delivered at scale for end users.
I think there is much to be learned from the evolution of DevOps — across the modern internet as well as within the modern enterprise — most notably for those of us who work with data every day.
At its core, DevOps is about the combination of software engineering, quality assurance and technology operations. DevOps emerged because traditional systems management wasn’t remotely adequate to meet the needs of modern, web-based application development and deployment.
DevOps in the Enterprise
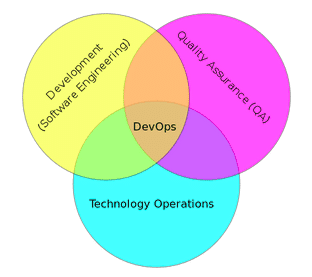
From DevOps to DataOps
I believe that it’s time for data engineers and data scientists to embrace a similar new discipline — let’s call it “DataOps” — that at its core addresses the needs of data professionals on the modern internet and inside the modern enterprise.
Two trends are creating the need for DataOps:
1. The democratization of analytics, which is giving more individuals access to cutting-edge visualization, data modeling, machine learning and statistics. Tableau CEO Christian Chabot has frequently championed democratization as “a tremendous opportunity to help people answer questions, solve problems and generate meaning from data in a way that has never before been possible. And we believe there’s an opportunity to put that power in the hands of a much broader population of people.”
2. The implementation of “built-for-purpose” database engines, which radically improve the performance and accessibility of large quantities of data at unprecedented velocities. My partner Mike Stonebraker has been arguing convincingly for years, as he does in this KDnuggets interview, that “one size does not fit all — i.e. in every vertical market I can think of, there is a way to beat legacy relational DBMSs by 1-2 orders of magnitude. The techniques used vary from market to market. Hence, StreamBase, Vertica, VoltDB and SciDB are all specialized to different markets.”
More recently — as in this week — Google has made its massive Bigtable database (the same one that powers Google search, Maps, YouTube, Gmail, etc.) available to everyone in an “extremely scalable NoSQL database service” accessible through “the industry-standard, open-source ApacheHBase API.
Together these trends create “pressure from both ends of the stack.” From the top of the stack, more users want access to more data in more combinations. And from the bottom of the stack, more data is available than ever before — some aggregated, much of it not. The only way for data professionals to deal with pressure of heterogeneity from both the top and bottom of the stack is to embrace a new approach to managing data that blends operations and collaboration to organize and deliver data from many sources to many users reliably with the provenance required to support reproducible data flows.
Let me take a stab at definition: DataOps is a data management method that emphasizes communication, collaboration, integration, automation and measurement of cooperation between data engineers, data scientists and other data professionals.
DataOps acknowledges the interconnected nature of data engineering, data integration, data quality and data security/privacy — and aims to help an organization rapidly deliver data that accelerates analytics and enables previously impossible analytics.
DataOps in the Enterprise
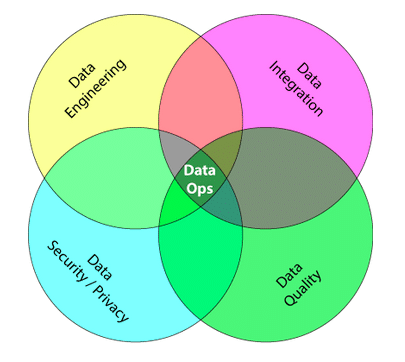
The “ops” in DataOps is very intentional. The operation of infrastructure required to support the quantity, velocity and variety of data available in the enterprise today is radically different than what traditional data management approaches have assumed. The nature of DataOps embraces the need to manage MANY data sources and MANY data pipelines with a wide variety of transformations.
People have been managing data for a long time, but we’re at a point now where the quantity, velocity and variety of data available to a modern enterprise can no longer be managed without a significant change in the fundamental infrastructure. The design point must focus on the thousands of sources that are not controlled centrally and frequently change their schema without notification — much in the way that websites change frequently without notifying search engines.
Consider this post the starting point for an argument for thinking about data sources (especially tabular data sets) as if they were websites being published inside of an organization.
Next up: a look at each of the four areas that come together in this DataOps model: Integration, Engineering, Quality and Security/Privacy.
Until then, as my partner Mike likes to say, “Brickbats welcome.”
# # #
{kind=link}