

Whenever we begin dealing with machine learning, we often turn to the simpler classification models. In fact, people outside of this sphere have mostly seen those models at work. After all, image recognition has become the poster child of machine learning.
However, classification, while powerful, is limited. There are lots of tasks we would like to automate that are impossible to do on classification. A great example of that would be picking out some best candidates (according to historical data) from a set.
We are intending to implement something similar at Oxylabs. Some web scraping operations can be optimized for clients through machine learning. At least thats our theory.
The theory
In web scraping, there are numerous factors that influence whether a website is likely to block you. Crawling patterns, user agents, request frequency, total requests per day – all of these and more have an impact on the likelihood of receiving a block. For this case, well be looking into user agents.
We might say that the correlation between user agents and block likelihood is an assumption. However, from our experience (and from some of them being blocked outright), we can safely say that some user agents are better than others. Thus, knowing which user agents are best suited for the task, we can receive less blocks.
Yet, theres an important caveat – its unlikely that the list is static. It would likely change over time and over data sources. Therefore, static-rule-based approaches wont cut it if we want to optimize our UA use to the max.
Regression-based models are based on statistics. They take two (correlated) random variables and attempt to create a minimal cost function. A simplified way to look at minimal cost functions is to view it as a line that has the least average distance from all data points squared. Over time, machine learning models can begin to make predictions about the data points.
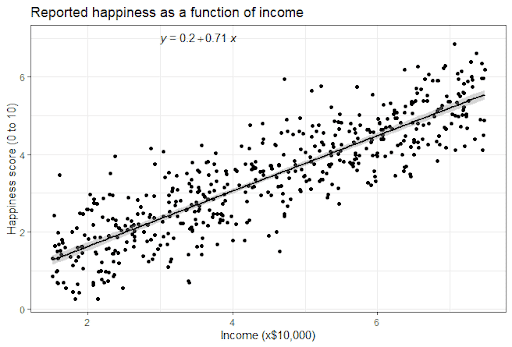
Simple linear regression. There are many ways to draw the line but the goal is to find the most efficient one. Source
We have already assumed with reason that the amount-of-requests (which can be expressed in numerous ways and will be defined later) is somehow correlated with the user agent sent when accessing a resource. As mentioned previously, we know that a small number of UAs have terrible performance. Additionally, from experience we know a significantly larger number of user agents have an average performance.
My final assumption might be clear – we should assume that there are some outliers that perform exceptionally well. Thus, we accept that the distribution of UAs to amount-of-requests will follow a bell-curve. Our goal is to find the really good ones.
Note that amount-of-requests will be correlated with a whole host of other variables, making the real representation a lot more complex.
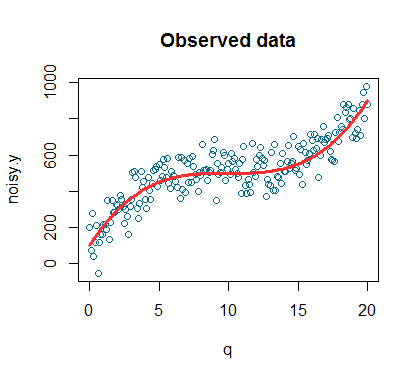
Intuitively our fit should look a little like this. Source
But why are user agents an issue at all? Well, technically theres a practically infinite set of possible user agents in existence. As an example, there are over 18 millions of UAs available in one database for just Chrome. Additionally, the number keeps growing by the minute as new versions of browsers and OS get released. Clearly, we cant use or test them all. We need to make a guess which will be the best.
Therefore, our goal with the machine learning model is to create a solution that can predict the effectiveness (defined through amount-of-requests) of UAs. We would then take those predictions and create a pool of maximally effective user agents to optimize scraping.
The math
Often, the first line of defense is sending the user a CAPTCHA to complete if he has sent out too many requests. From our experience, allowing people to continue scraping even if the CAPTCHA is solved, results in a block quite quickly.
Here we would define CAPTCHA as the first instance when the test in question is delivered and requested to be solved. A block is defined as losing access to the usual content displayed on the website (whether receiving a refused connection or by other means).
Therefore, we can define amount-of-requests as the amount of requests per given time to a specific source a single UA can make before receiving a CAPTCHA. Such a definition is reasonably accurate without forcing us to sacrifice proxies.
However, in order to measure the performance of any specific UA, we need to know the expected value of the event. Luckily, from the Law of Large Numbers we can deduce that after an extensive amount of trials, the average of the results will converge towards the expected value.
Thus, all we need to do is allow our clients to continue their daily activities and measure the performance of each user agent according to the amount-of-requests definition.
Since we have an unknown expected value that is deterministic (although noise will occur, we know that IP blocks are based on a specified ruleset), we will commit a mathematical atrocity – decide when the average is close enough. Unfortunately, without data its impossible to say beforehand how many trials we need.
Our calculations of how many trials are needed until our empirical average (i.e. the average of our current sample) might be close to the expected value will depend on sample variance. Our convergence of random variables to a constant c can be denoted by:
![]()
where the variance is: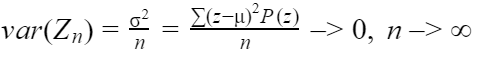
From here we can deduce that higher sample variances (2) mean more trials-to-convergence. Thus, at this point its impossible to make a prediction on how many trials we would need to approach a reasonable average. However, in practice, getting a grasp on the average performance of an UA wouldnt be too difficult to track.
Deducing the average performance of an UA is a victory in itself. Since a finite set of user agents per data source is in use, we can use the mean as a measuring rod for every combination. Basically, it allows us to remove the ones that are underperforming and attempt to discover those that overperform.
However, without machine learning, discovering overperforming user agents would be guesswork for most data sources unless there was some clear preference (e.g. specific OS versions). Outside of such occurrences, we would have little information to go by.
The model
There are numerous possible models and libraries to choose from, ranging from PyCaret to Scikit-Learn. Since we have guessed that the regression is polynomial, our only real requirement is that the model is able to fit such distributions.
I wont be getting into the data feeding part of the discussion here. A more pressing and difficult task is at hand – encoding the data. Most, if not all, regression-based machine learning models only accept numeric values as data points. User agents are strings.
Usually, we may be able to turn to hashing to automate the process. However, hashing removes relationships between similar UAs and can even potentially result in two taking the same value. We cant have that.
There are other approaches. For shorter strings, creating a custom encoding algorithm could be an option. It can be done through a simple mathematical process of creating:
- A custom base(n), where n is the number of all symbols used.
- Assign each symbol to an integer starting from 0.
- Select a string.
- Multiply each assigned integer by nx-1, where x is the length of the string.
- Sum the result.
Each result would be a unique integer. When needed, the result can be reversed through the use of logarithms. However, user agents are fairly long strings which can result in some unexpected interactions in some environments.
A cognitively more manageable approach would be to tilt user agents vertically and use version numbers as ID generators. As an example, we can create a simple table by taking some existing UA:
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/605.1.15 (KHTML, like Gecko)
|
UA ID |
Mozilla |
Intel Mac OS X |
AppleWebKit |
Windows NT |
|
50101456051150 |
5.0 |
10_14_5 |
605.1.15 |
0 |
You might notice that theres no Windows NT in the example. Thats the important bit as we want to create strings of as equal length as possible. Otherwise, we increase the likelihood of two user agents pointing to the same ID.
As long as a sufficient number of products is set into the table, unique integers can be easily generated by stripping version numbers and creating a conjunction (e.g. 50101456051150). For products that have no assigned versions (e.g. Macintosh), a unique ID can be assigned, starting from 0.
As long as the structure remains stable over time, integer generation and reversion will be easy. They will likely not result in overflows or other nastiness.
Of course, there needs to be some careful consideration before the conversion is implemented because changing the structure would result in a massive headache. Leaving a few blind-spots in case it needs to be updated might be wise.
Once we have the data on performance and a unique integer generation method, the rest is relatively easy. As we have assumed that it might follow a bell-curve distribution, we will likely have to attempt to fit our data into a polynomial function. Then, we can begin filling the models with data.
Conclusion
You dont even need to build the model to benefit from such an approach. Simply knowing the average performance of the sample and the amount-of-requests of specific user agents, would allow you to look for correlations. Of course, that would take a lot of effort until a machine learning model would be able to do it all for you.
{kind=link}