
This article was written by Sebastian Ruder. Sebastian is a PhD student in Natural Language Processing and a research scientist at AYLIEN. He blogs about Machine Learning, Deep Learning, NLP, and startups.
Gradient descent is one of the most popular algorithms to perform optimization and by far the most common way to optimize neural networks. At the same time, every state-of-the-art Deep Learning library contains implementations of various algorithms to optimize gradient descent (e.g. lasagne’s, caffe’s, and keras’documentation). These algorithms, however, are often used as black-box optimizers, as practical explanations of their strengths and weaknesses are hard to come by.
This blog post aims at providing you with intuitions towards the behaviour of different algorithms for optimizing gradient descent that will help you put them to use. We are first going to look at the different variants of gradient descent. We will then briefly summarize challenges during training. Subsequently, we will introduce the most common optimization algorithms by showing their motivation to resolve these challenges and how this leads to the derivation of their update rules. We will also take a short look at algorithms and architectures to optimize gradient descent in a parallel and distributed setting. Finally, we will consider additional strategies that are helpful for optimizing gradient descent.
Gradient descent is a way to minimize an objective function J(θ) parameterized by a multivariate model’s parameter θ parameters by updating the parameters in the opposite direction of the gradient of the objective function ∇J(θ) w.r.t. to the parameters. The learning rate η determines the size of the steps we take to reach a (local) minimum. In other words, we follow the direction of the slope of the surface created by the objective function downhill until we reach a valley. If you are unfamiliar with gradient descent, you can find a good introduction on optimizing neural networks here.
Below is an illustration of various learning-rate methods, showing higher performance of adaptive methods, in two differebt configurations of extrema.
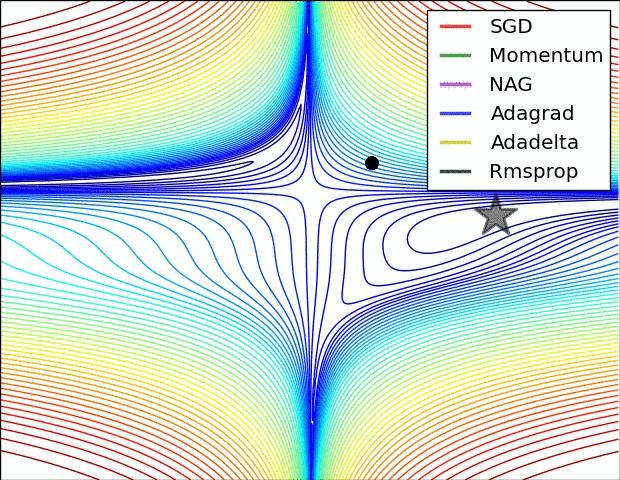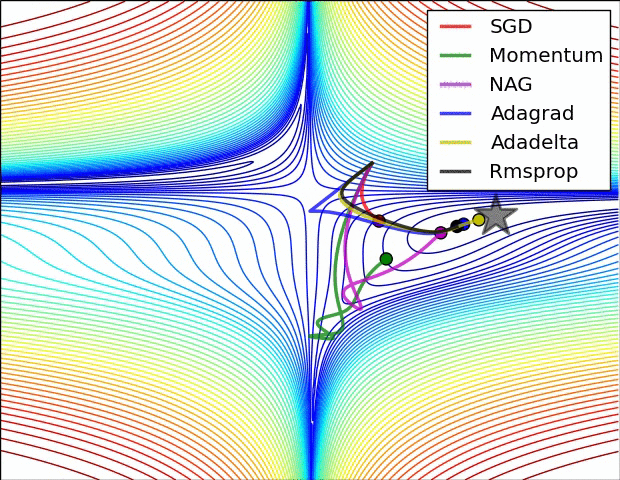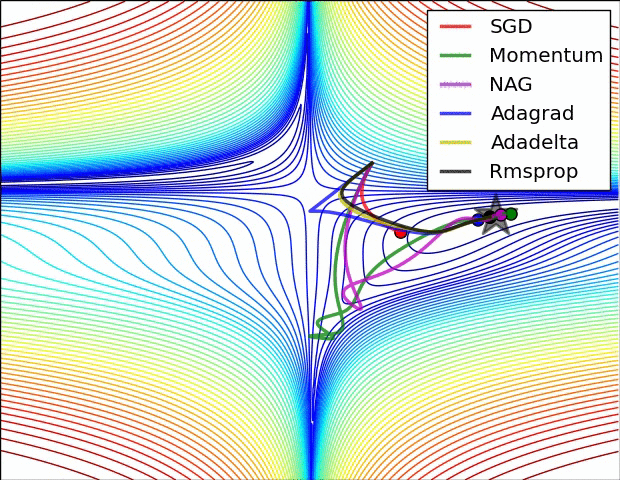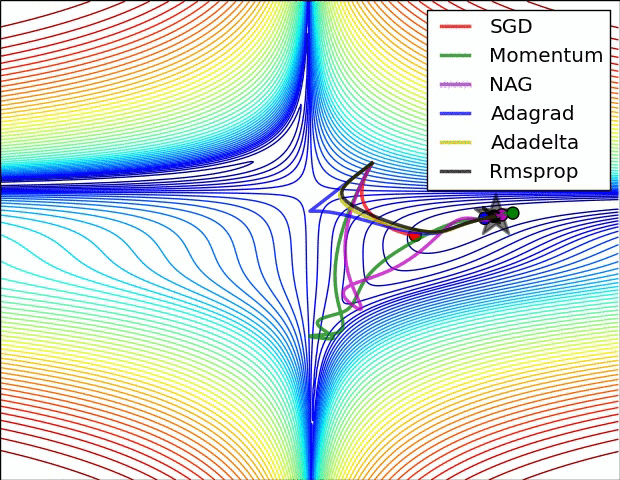
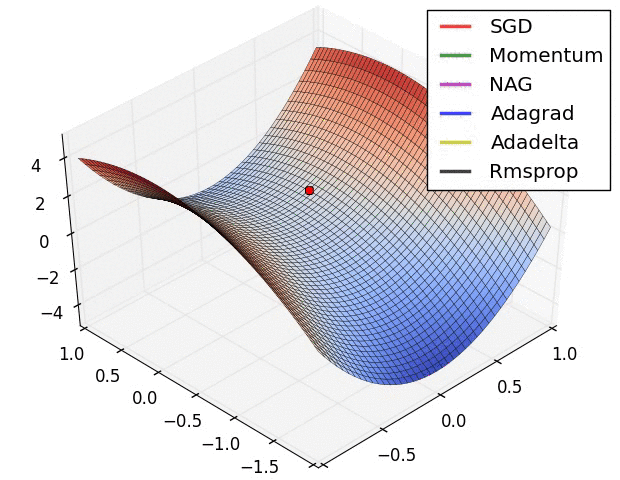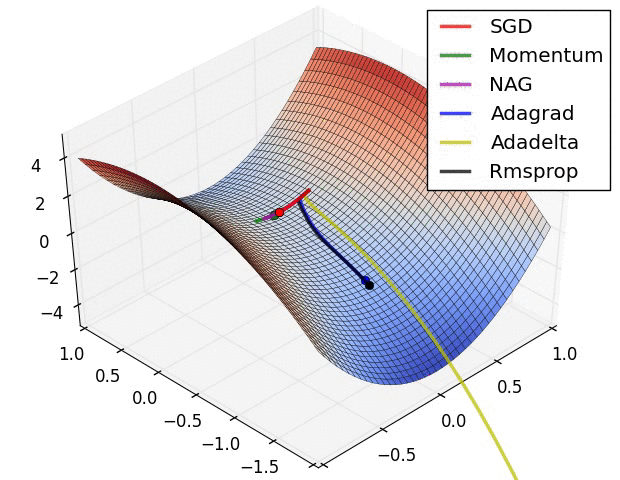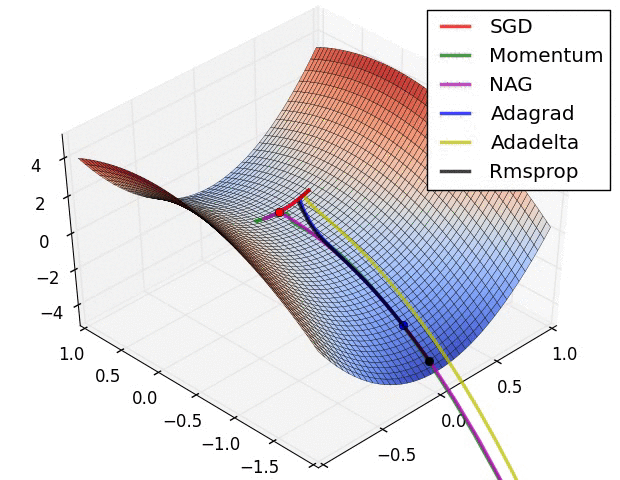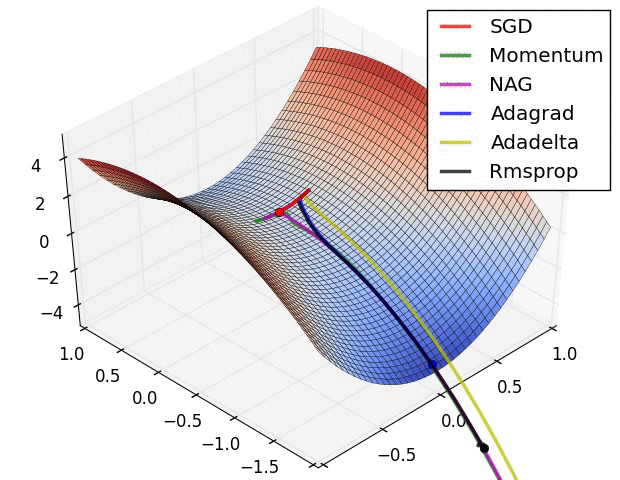
Table of contents:
Gradient descent optimization algorithms
- Momentum
- Nesterov accelerated gradient
- Adagrad
- Adadelta
- RMSprop
- Adam
- Visualization of algorithms
- Which optimizer to choose?
Parallelizing and distributing SGD
Additional strategies for optimizing SGD
To check out all this information, click here.
Top DSC Resources
- Article: What is Data Science? 24 Fundamental Articles Answering This Question
- Article: Hitchhiker’s Guide to Data Science, Machine Learning, R, Python
- Tutorial: Data Science Cheat Sheet
- Tutorial: How to Become a Data Scientist – On Your Own
- Categories: Data Science – Machine Learning – AI – IoT – Deep Learning
- Tools: Hadoop – DataViZ – Python – R – SQL – Excel
- Techniques: Clustering – Regression – SVM – Neural Nets – Ensembles – Decision Trees
- Links: Cheat Sheets – Books – Events – Webinars – Tutorials – Training – News – Jobs
- Links: Announcements – Salary Surveys – Data Sets – Certification – RSS Feeds – About Us
- Newsletter: Sign-up – Past Editions – Members-Only Section – Content Search – For Bloggers
- DSC on: Ning – Twitter – LinkedIn – Facebook – GooglePlus
Follow us on Twitter: @DataScienceCtrl | @AnalyticBridge
{kind=link}