
This article was posted by Adam Geitgey. Adam is Interested in computers and machine learning and he likes to write about it.
Speech recognition is invading our lives. It’s built into our phones, our game consoles and our smart watches. It’s even automating our homes. For just $50, you can get an Amazon Echo Dot — a magic box that allows you to order pizza, get a weather report or even buy trash bags — just by speaking out loud:

Alexa, order a large pizza!
The Echo Dot has been so popular this holiday season that Amazon can’t seem to keep them in stock!
But speech recognition has been around for decades, so why is it just now hitting the mainstream? The reason is that deep learning finally made speech recognition accurate enough to be useful outside of carefully controlled environments.
Andrew Ng has long predicted that as speech recognition goes from 95% accurate to 99% accurate, it will become a primary way that we interact with computers. The idea is that this 4% accuracy gap is the difference between annoyingly unreliable and incredibly useful. Thanks to Deep Learning, we’re finally cresting that peak.
Let’s learn how to do speech recognition with deep learning!
Machine Learning isn’t always a Black Box
If you know how neural machine translation works, you might guess that we could simply feed sound recordings into a neural network and train it to produce text:
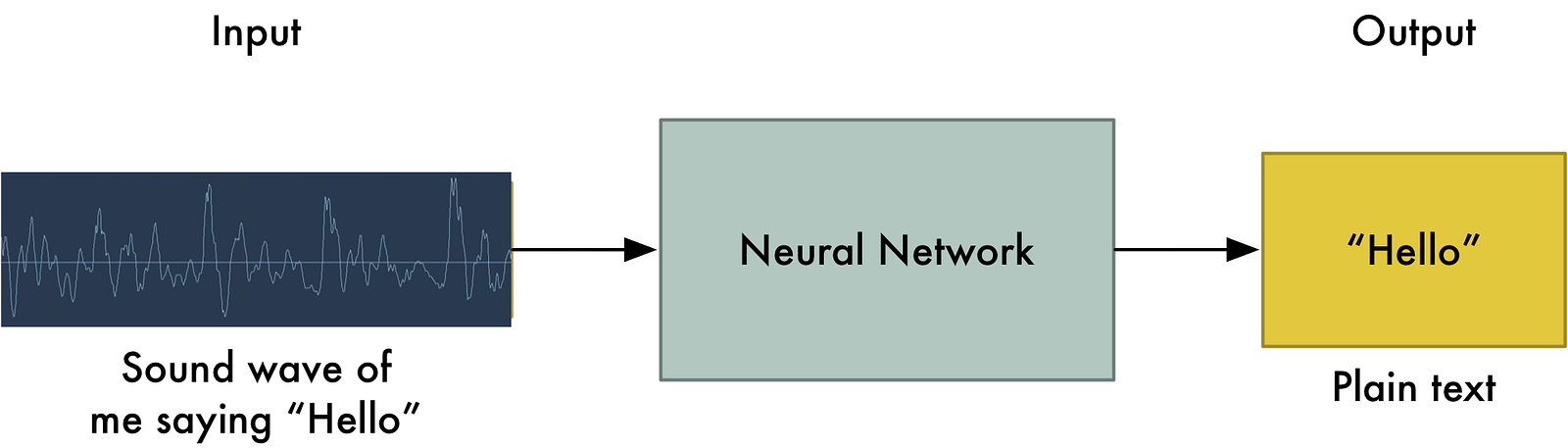
That’s the holy grail of speech recognition with deep learning, but we aren’t quite there yet (at least at the time that I wrote this — I bet that we will be in a couple of years).
The big problem is that speech varies in speed. One person might say “hello!” very quickly and another person might say “heeeelllllllllllllooooo!” very slowly, producing a much longer sound file with much more data. Both both sound files should be recognized as exactly the same text — “hello!” Automatically aligning audio files of various lengths to a fixed-length piece of text turns out to be pretty hard.
To work around this, we have to use some special tricks and extra precessing in addition to a deep neural network.
What you will find in this article:
– Turning Sounds into Bits
A Quick Sidebar on Digital Sampling
– Pre-processing our Sampled Sound Data
– Recognizing Characters from Short Sounds
Wait a second!
– Can I Build My Own Speech Recognition System?
– Where to Learn More
To learn more about all this information and to check out Part 1, Part 2, Part 3, Part 4 and Part 5 for more Machine Learning fun, click here.
Top DSC Resources
- Article: What is Data Science? 24 Fundamental Articles Answering This Question
- Article: Hitchhiker’s Guide to Data Science, Machine Learning, R, Python
- Tutorial: Data Science Cheat Sheet
- Tutorial: How to Become a Data Scientist – On Your Own
- Categories: Data Science – Machine Learning – AI – IoT – Deep Learning
- Tools: Hadoop – DataViZ – Python – R – SQL – Excel
- Techniques: Clustering – Regression – SVM – Neural Nets – Ensembles – Decision Trees
- Links: Cheat Sheets – Books – Events – Webinars – Tutorials – Training – News – Jobs
- Links: Announcements – Salary Surveys – Data Sets – Certification – RSS Feeds – About Us
- Newsletter: Sign-up – Past Editions – Members-Only Section – Content Search – For Bloggers
- DSC on: Ning – Twitter – LinkedIn – Facebook – GooglePlus
Follow us on Twitter: @DataScienceCtrl | @AnalyticBridge
{kind=link}