
It is becoming a bit difficult to follow all the new AI, RAG and LLM terminology, with new concepts popping up almost every week. Which ones are important, and here to stay? Which ones are just old stuff rebranded with a new name for marketing purposes? In this new series, I start with chunking, indexing, scoring, and agents. These words can have different meanings depending on the context. It is noteworthy that recently, No-GPU specialized LLMs are gaining considerable traction. This is especially true for enterprise versions. My discussion here is based on my experience building such models, from scratch. It applies both to RAG and LLM.
Chunking
All large language models and RAG apps use a corpus or document repository as input source. For instance, top Internet websites, or a corporate corpus. LLMs produce nice grammar and English prose, while RAG systems focus on retrieving useful information in a way similar to Google search, but much better and with a radically different approach. Either way, when building such models, one of the very first steps is chunking.
As the name indicates, chunking consists in splitting the corpus in small text entities. In some systems, text entities have a fixed size. However, a better solution is to use separators. In this case, text entities are JSON elements, parts of a web page, paragraphs, sentences, or subsections in PDF documents. In my xLLM system, text entities, besides standard text, also have a variable number of contextual fields such as agents, categories, parent categories, tags, related items, titles, URLs, images, and so on. A critical parameter is the average size of these text entities. In xLLM, you can optimize the size via real-time fine-tuning.
Indexing
Chunking and indexing go together. By indexing, I mean assigning an ID (or index) to each text entity. This is different from automatically creating an index for your corpus, a task known as auto-indexing and soon available in xLLM, along with cataloging.
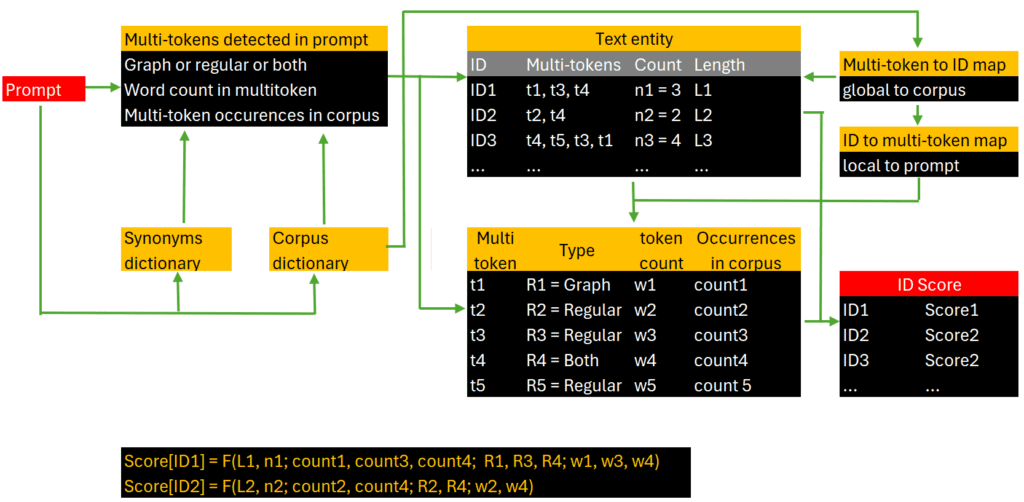
The goal is to efficiently retrieve relevant text entities stored in a database, thanks to the text entity IDs accessible in memory. In particular, a backend table maps each corpus token (multi-token for xLLM) to the list of text entities that contain them. Text entities are represented by their IDs. Then, when processing a prompt, you first extract prompt tokens, match them to tokens in the corpus, and eventually to text entities that contain them, using a local transposed version of the backend table in question, restricted to prompt tokens. The end result is a list of candidate text entities to choose from (or to blend and turn into prose), when displaying prompt results.
Agents
Sometimes the word agent is synonym to action: composing an email, solving a math problem, or producing and running some Python code as requested by the user. In this case, LLM may use an external API to execute the action. However, here, by agent, I mean the type of information the user wants to retrieve: a summary, definitions, URLs, references, best practices, PDFs, datasets, images, instructions about filling a form, and so on.
Standard LLMs try to guess the intent of the user from the prompt. In short, they automatically assign agents to a prompt. However, a better alternative consists in offering a selection of potential agents to the user, in the prompt menu. In xLLM, agents are assigned post-crawling to text entities, as one of the contextual fields. Agent assignment is performed with a clustering algorithm applied to the corpus, or via simple pattern matching. Either way, it is done very early on in the backend architecture. Then, it is easy to retrieve text entities matching specific agents coming from the prompt.
Relevancy Scores
If a prompt triggers 50 candidate text entities, you need to choose a subset to display in the prompt results, to not overwhelm the user. Even if the number is much smaller, it is still a good idea to use scores and show them in prompt results: it gives the user an idea of how confident your LLM is about its answer as a whole, or about parts of the answer. To achieve this goal, you assign a score to each candidate text entity.
In xLLM, the computation of the relevancy score, for a specific prompt and a specific text entity, is a combination of the following elements. Each of these elements has its own sub-score.
- The number of prompt multi-tokens present in the text entity.
- Multi-tokens consisting of more than one word and rare multi-tokens (with low occurrence in the corpus) boost the relevancy score.
- Prompt multi-tokens present in a contextual field in the text entity (category, title, or tag) boost the relevancy score.
- The size of the text entity has an impact on the score, favoring long over short text entities.
You then create a global score as follows, for each candidate text entity, with respect to the prompt. First, you sort text entities separately by each sub-score. You use the sub-ranks resulting from this sorting, rather than the actual values. Then you compute a weighted combination of these sub-ranks, for normalization purposes. That’s your final score. Finally, in prompt results, you display text entities with a global score above some threshold, or (say) the top 5. I call it the new “PageRank” for RAG/LLM, a replacement of the Google technology to decide on what to show to the user, for specific queries.
For detailed documentation, source code and sample input corpus (Fortune 100 company), see my books and articles on the topic, especially the new book “Building Disruptive AI & LLM Technology from Scratch”, listed at the top, here.
About the Author

Vincent Granville is a pioneering GenAI scientist and machine learning expert, co-founder of Data Science Central (acquired by a publicly traded company in 2020), Chief AI Scientist at MLTechniques.com and GenAItechLab.com, former VC-funded executive, author (Elsevier) and patent owner — one related to LLM. Vincent’s past corporate experience includes Visa, Wells Fargo, eBay, NBC, Microsoft, and CNET. Follow Vincent on LinkedIn.
{kind=link}