
Learn More On Advance Pandas and NumPy for Data Science (Part -II) Cont…….
Welcome Back to Part II article. Hope you all enjoyed the content coverage there, here will continue with the same rhythm and learn more in that space.
We have covered Reshaping DataFrames and Combining DataFrames in Part I.
Working with Categorical data:
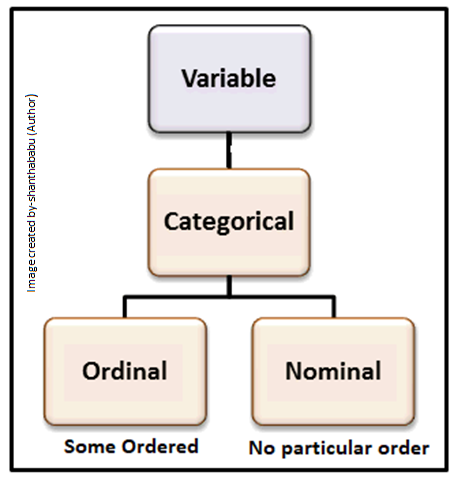
First, try to understand what is Categorical variables in a given dataset.
Categorical variables are a group of values and it can be labeled easily and it contains definite possible values. It would be Numerical or String. Let’s say Location, Designation, Grade of the students, Age, Sex, and many more examples.
Still, we could divide the categorical data into Ordinal Data and Nominal Data.
- Ordinal Data
- These categorical variables have proper inherent order (like Grade, Designation)
- Nominal Data
- This is just opposite to Ordinal Data, so we can’t expect an inherent order 🙂
- Continuous Data
- Continuous variables/features have an infinite number of values with certain boundaries, always it can be numeric or date/time data type.
Actually speaking we’re going to do “Encoding” them and take it for further analysis in the Data Science/Machine Learning life cycle process.
As we know that 70 80% of effort would be channelized for the EDA process in the Data Science field. Because cleaning and preparing the data is the major task, then only we could prepare the stable model selection and finalize it.
In Which the process of converting categorical data into numerical data is an unavoidable and necessary activity, this activity is called Encoding.
Encoding Techniques
- One Hot Encoding
- Dummy Encoding
- Label Encoding
- Ordinal Encoding
- Target Encoding
- Mean Encoding
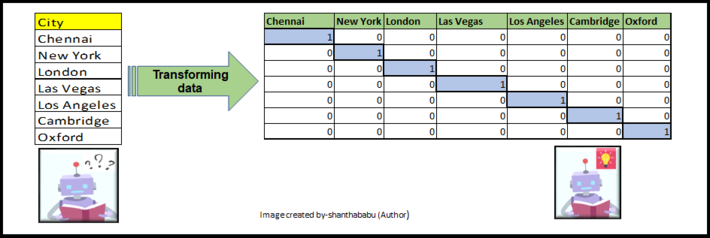
- One-Hot Encoding
- As we know that FE is transforming the given data into a reasonable form. which is easier to interpret and making data more transparent to helping to build the model.
- And the same time creating new features to enhance the model, in that aspects the One-Hot Encoding methodology coming into the picture.
- This technique can be used when the features are nominal.
- In one hot encoding, for each level of a categorical feature, we create a new variable. (Feature/Column)
- The category can be mapped with a binary variable 0 or 1. based on presence or absence.
- Dummy Encoding
- This scheme is similar to one-hot encoding.
- The categorical encoding methodology transforms the categorical variable into binary variables (also known as dummy variables).
- The dummy encoding method is an improved version of over one-hot-encoding.
- It uses N-1 features to represent N labels/categories.
One-Hot Encoding
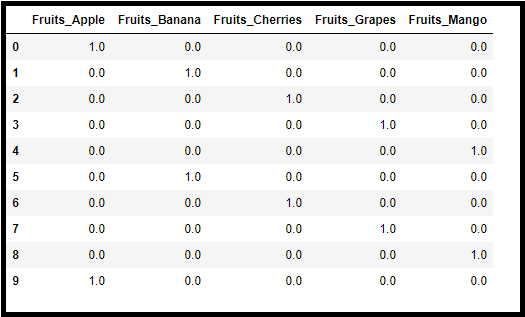
Code
data=pd.DataFrame({“Fruits”:”Apple”,”Banana”,”Cherries”,”Grapes”,”Mango”,”Banana”,”Cherries”,”Grapes”,“Mango”,”Apple”]})
data
#Create object for one-hot encoding
import category_encoders as ce
encoder=ce.OneHotEncoder(cols=’Fruits’,handle_unknown=’return_nan’,return_df=True,use_cat_names=True)
data_encoded = encoder.fit_transform(data)
data_encoded
Playing with DateTime Data
Whenever youre dealing with data and time datatype, we can use the DateTime library which is coming along with pandas as Datetime objects. On top of the to_datetime() function help us to convert multiple DataFrame columns into a single DateTime object.
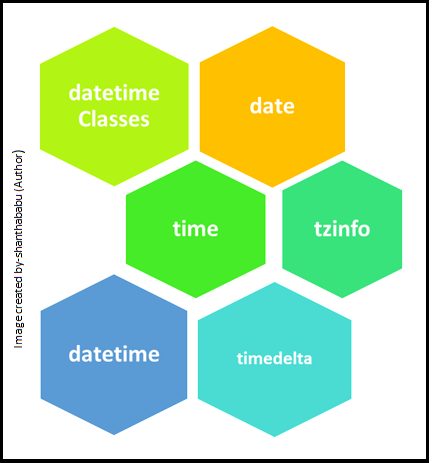
List of Python datetime Classes
- datetime To manipulate dates and times – month, day, year, hour, second, microsecond.
- date To manipulate dates alone – month, day, year.
- time To manipulate time – hour, minute, second, microsecond.
- timedelta Dates and Time measuring.
- tzinfo Dealing with time zones.
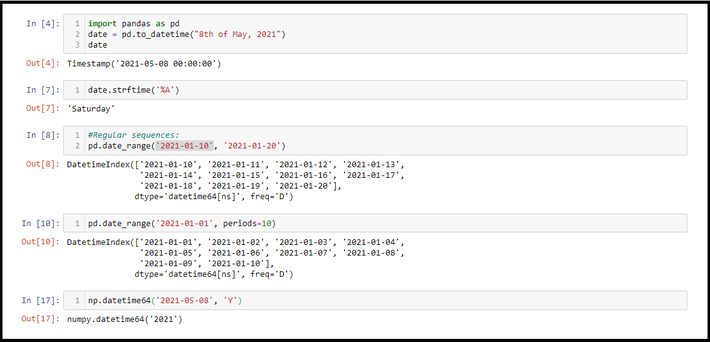
Converting data types
As we know that converting data type is common across all programming languages. Python not exceptional for this. Python provided type conversion functions to convert one data type to another.
Type Conversion in Python:
- Explicit Type Conversion: During the development, the developer will write the code to change the type of data as per their requirement in the flow of the program.
- Implicit Type Conversion: Python has the capability to convert type automatically without any manual involvement.
Explicit Type Conversion
Code
# Type conversion in Python
strA = “1999” #Sting type
# printing string value converting to int
intA = int(strA,10)
print (“Into integer : “, intA)
# printing string converting to float
floatA = float(strA)
print (“into float : “, floatA)
Output
Into integer : 1999
into float : 1999.0
# Type conversion in Python
# initializing string
strA = “Welcome”
ListA = list(strA)
print (“Converting string to list :”,(ListA))
tupleA = tuple(strA)
print (“Converting string to list :”,(tupleA))
Output
Converting string to list : [‘W’, ‘e’, ‘l’, ‘c’, ‘o’, ‘m’, ‘e’]
Converting string to list : (‘W’, ‘e’, ‘l’, ‘c’, ‘o’, ‘m’, ‘e’)
Few other function
dict() : Used to convert a tuple into a dictionary.
str() : Used to convert integer into a string.
Implicit Type Conversion
a = 100
print(“a is of type:”,type(a))
b = 100.6
print(“b is of type:”,type(b))
c = a + b
print(c)
print(“c is of type:”,type(c))
Output
a is of type: <class ‘int’>
b is of type: <class ‘float’>
200.6
c is of type: <class ‘float’>
Access Modifiers in Python: As we know that Python supports Oops. So certainly we Public, Private and Protected has to be there, Yes Of course!
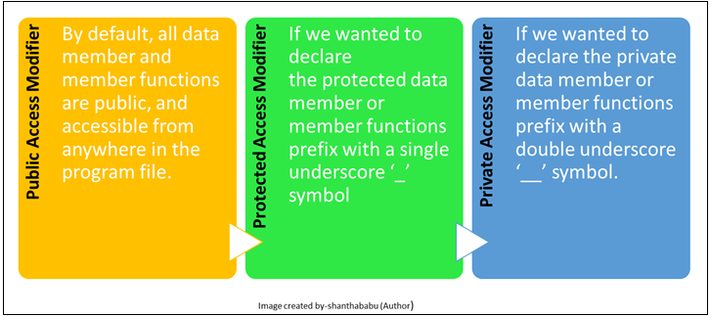
Python access modifications are used to restrict the variables and methods of the class. In Python, we have to use UNDERSCORE _ symbol to determine the access control for a data member and/or methods of a class.
- Public Access Modifier:
- By default, all data member and member functions are public, and accessible from anywhere in the program file.
- Protected Access Modifier:
- If we wanted to declare the protected data member or member functions prefix with a single underscore _ symbol
- Private Access Modifier:
- If we wanted to declare the private data member or member functions prefix with a double underscore __ symbol.
Public Access Example
class Employee:
def __init__(self, name, age):
# public data mambers
self.EmpName = name
self.EmpAge = age
# public memeber function displayEmpAge
def displayEmpAge(self):
# accessing public data member
print(“Age: “, self.EmpAge)
# creating object of the class from Employee Class
objEmp = Employee(“John”, 40)
# accessing public data member
print(“Name: Mr.”, objEmp.EmpName)
# calling public member function of the class
objEmp.displayEmpAge()
OUTPUT
Name: Mr. John
Age: 40
Protected Access Example
Creating super class and derived class. Accessing private and public member function.
# super class
class Employee:
# protected data members
_name = None
_designation = None
_salary = None
# constructor
def __init__(self, name, designation, salary):
self._name = name
self._designation = designation
self._salary = salary
# protected member function
def _displayotherdetails(self):
# accessing protected data members
print(“Designation: “, self._designation)
print(“Salary: “, self._salary)
# derived class
class Employee_A(Employee):
# constructor
def __init__(self, name, designation, salary):
Employee.__init__(self, name, designation, salary)
# public member function
def displayDetails(self):
# accessing protected data members of super class
print(“Name: “, self._name)
# accessing protected member functions of superclass
self._displayotherdetails()
# creating objects of the derived class
obj = Employee_A(“David”, “Data Scientist “, 5000)
# calling public member functions of the class
obj.displayDetails()
OUTPUT
Name: David
Designation: Data Scientist
Salary: 5000
Hope we learned so many things, very useful for you everyone, and have to cover Numpy, Here I am passing and continue in my next article(s). Thanks for your time and reading this, Kindly leave your comments. Will connect shortly!
Until then Bye and see you soon – Cheers! Shanthababu.
){kind=link}