

This post is a token of appreciation for the amazing open source community of Data Science, to which I owe a lot of what I have learned.
For last few months, I have been working on a side project of mine to develop machine learning application on streaming data. It was a great learning experience with numerous challenges and lots of learning, some of which I have tried to share in here.
This post is focused on how to deploy machine learning models on streaming data and covers all 3 necessary areas of a successful production application: infrastructure, technology, and monitoring.
DEVELOPING A MACHINE LEARNING MODEL WITH SPARK-ML AND STRUCTURED STREAMING
The first step for any successful application is to determine the technology stack in which it should be written, on the basis of business requirements. As a general rule, when the amount of data is huge, use Spark.
Primary benefits of using Spark is its proven ability in big data processing and, availability of inbuilt distributed machine learning libraries. The initial challenges in using spark was the use of RDD, which were in-intuitive and very different from the Dataframes, which, Data Scientists are used to working with. However, with the introduction of Dataset API in Spark2.0 it has now become easier than before, to code up a machine learning algorithm.
During my experience, I have found that working with machine learning models becomes extremely easy with proper utilization of “Pipeline” framework. What a Pipeline does is provide a structure to include all the steps required for processing & cleaning data, training a model, and then writing it out as an Object.
This object then can directly be imported to process new data and get results freeing the developer with process of re-writing and maintaining the exact copy of processing steps for the new data which were followed for building a model with the training data.
In the snippet below I have tried to cover how to use this API to build, save and use the models for prediction.For building and saving a model one can follow the following code structure.
// Create a sqlContext
var sqlContext = new SQLContext(sparkContext)
// Read the training data from a source. In this case i am reading it from a s3 location
var data = sqlContext.read.format(“csv”).option(“header”, “true”).option(“inferSchema”, “true”).load(“pathToFile”)
// Select the needed messages
data = data.select(“field1”,”field2",”field3")
// Perform pre-processing on the data
val process1 = … some process …
val process2 = … some process …
// Define an evaluator
val evaluator = … evaluator of your choice …
// split the data into training and test
val Array(trainingData, testData) = data.randomSplit(Array(ratio1, ratio2))
// Define the algorithm to train. For example decision tree
val dt = new DecisionTree()
.setFeaturesCol(featureColumn).setLabelCol(labelColumn)
// Define the linear pipeline. Methods specified in the pipeline are executed in a linear order. Sequence of steps is binding
val pipelineDT = new Pipeline().setStages(Array(process1, process2, dt))
// Define the cross validator for executing the pipeline and performing cross validation.
val cvLR = new CrossValidator()
.setEstimator(pipelineDT)
.setEvaluator(evaluator)
.setNumFolds(3) // Use 3+ in practice
// Fit the model on training data
val cvModelLR = cvLR.fit(trainingData)
// extract the best trained pipeline model from the cross validator.
val bestPipelineModel = cvModelLR.bestModel.asInstanceOf[PipelineModel]
// Save the model in a s3 bucket
cvModelLR.write.overwrite().save(mlModelPath)
Once a model is saved it can be used for prediction on streaming data easily with the following steps.
1. Read data from a Kafka topic
// Create a spark session object
val ss = SparkSession.builder.getOrCreate()
// Define schema of the topic to be consumed
val schema= StructType( Seq(
StructField(“Field1”,StringType,true),
StructField(“Field2”,IntType,true)
)
)
// Start reading from a Kafka topic
val records = ss.readStream
.format(“kafka”)
.option(“kafka.bootstrap.servers”, kafkaServer)
.option(“subscribe”,kafkaTopic)
.load()
.selectExpr(“cast (value as string) as json”)
.select(from_json($”json”,schema).as(“data”))
.select(“data.*”)
2. Load a saved ML model and use it for prediction
// Load the classification model from saved location
val classificationModel = CrossValidatorModel.read.load(mlModelPath)
// Use the model to perform predictions. By default best model is used
val results = classificationModel.transform(records)
3. Save the results to s3 or other locations
In csv format
// Saving results to a location as csv
results.writeStream.format(“csv”).outputMode(“append”)
.option(“path”, destination_path) .option(“checkpointLocation”, checkpointPath)
.start()
In parquet format
// Saving results to a location as parquet
results.writeStream.format(“parquet”).outputMode(“append”)
.option(“path”, destination_path) .option(“checkpointLocation”, checkpointPath)
.start()
Or if we want to send the results to some database or any other extensions
val writer = new JDBCSink(url, user, password)
results.writeStream
.foreach(writer)
.outputMode(“append”)
.option(“checkpointLocation”, checkpointPath)
.start()
A separate writer needs to be implemented for this purpose by extending the ForeachWriter interface provided with spark structured streaming. A sample code for jdbc is shown below , taken from https://docs.databricks.com/_static/notebooks/structured-streaming-…
import java.sql._
class JDBCSink(url:String, user:String, pwd:String) extends ForeachWriter[(String, String)] {
val driver = “com.mysql.jdbc.Driver”
var connection:Connection = _
var statement:Statement = _
def open(partitionId: Long,version: Long): Boolean = {
Class.forName(driver)
connection = DriverManager.getConnection(url, user, pwd)
statement = connection.createStatement
true
}
def process(value: (String, String)): Unit = {
statement.executeUpdate(“INSERT INTO zip_test “ +
“VALUES (“ + value._1 + “,” + value._2 + “)”)
}
def close(errorOrNull: Throwable): Unit = {
connection.close
}
}
}
}
MONITORING, LOGGING, AND ALERTS
The next step is to integrate monitoring, alerting and logging services in the application, so as, to get instantaneous alerts and keep a tab on how the application has been working. There are many tools available in the AWS stack, to avail these. A couple of them which are used frequently are CloudWatch for Monitoring and Elastic Search for Logging.
A sample monitoring dashboard will look something like this
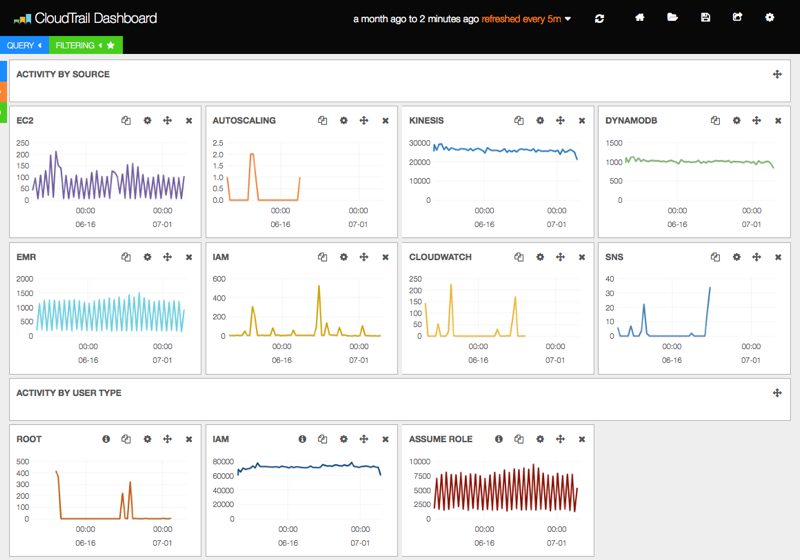
Image courtesy: https://github.com/amazon-archives/cloudwatch-logs-subscription-con…
INFRASTRUCTURE
Once the code is ready for deployment it is time to choose appropriate infrastructure for deploying it. What I found to be best infrastructure is Kafka (mainly because of its multi publisher/consumer architecture and the ability to set retention periods over different topics), and AWS EMR as the core infrastructure for running up applications
AWS EMR became the obvious choice owing to the availability of clusters with pre-installed spark and internal resource management. Ability to spin up a new cluster with full deployment in a short time is also a major plus point.
A simplified architecture diagram will look like.
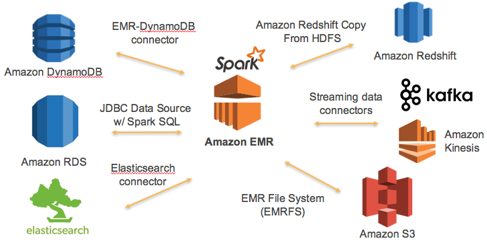
Image courtesy — https://dmhnzl5mp9mj6.cloudfront.net/bigdata_awsblog/images/Spark_S…
{kind=link}
TUNING A SPARK JOB
Lastly, as in any other spark job, tuning it is necessary in the case of a streaming job as well for maximum efficiency. First step in tuning a spark job is to choose appropriate instances for the job. On performing several experiments on M4(general purpose) vs C4(computation heavy) instance types, I found M4 to be better performing primarily because of its ability to provide virtual cores as well.
DynamicAllocation property in spark was also extremely useful in maximizing the utilization in a stable way. There are a number of other parameters as well which I found useful in tweaking performance:
a) — conf spark.yarn.executor.memoryOverhead=1024: The amount of memory overhead defined for the job
b) — conf spark.yarn.maxAppAttempts=4: This property defines the maximum number of attempts which will be made to submit the application. It’s quite useful for scenarios where multiple spark jobs are being submitted to a single cluster and sometimes submit jobs fail because of lack of available resources.
c) — conf spark.task.maxFailures=8: This property sets the maximum number of times a task can fail before the spark job fails itself. The default value is 2. It’s always a good idea to keep this number higher
d) — conf spark.speculation=false: When this property is set as true, yarn automatically kills and reassigns tasks based on the time they are consuming (if yarn sees them as being stuck). In our case we didn’t found this to be contributing much in performance but is a good property to look for while processing skewed data sets
e) — conf spark.yarn.max.executor.failures=15: The maximum number of executor failures before an application fails. Always set it to a higher number.
f) — conf spark.yarn.executor.failuresValidityInterval=1h: Defines the time interval for validity of executor failures. Combining with above property basically in hour maximum 15 executors can fail before the job dies.
g) — driver-memory 10g: Provide sufficiently high driver memory so as to not fail in case of a burst of messages are to be processed.
I hope this material proves out to be useful to people who are starting out with structured streaming. It will be a pleasure to contribute back to the open source community through which I have learned a lot.
For a much detailed technical overview please do visit https://spark.apache.org/docs/2.0.0/structured-streaming-programmin…
{kind=link}