
This blog takes a closer look at the concept of privacy-preserving synthetic data. It answers the question “what is synthetic data” and looks at the origin of synthetic data in the context of data privacy. It also presents one way of generating privacy-preserving synthetic data and its benefits for organizations.
What is synthetic data?
In a general sense, synthetic data is information that is artificially generated, as opposed to collected from the real-world. But it’s important to note that synthetic data is used for a variety of purposes. As a result, there are several types of synthetic data with different properties depending on the use-cases.
For instance, one scenario in which companies use synthetic data is the training of AI/ML models. Real-world data is sometimes expensive to collect, or simply hard to come by. If you take for instance self-driving vehicles, the development of software for autonomous driving involves considerable volumes of data.
In these cases, synthetic data is easier to produce than collecting real-world driver data. It also allows the training of models on a wide variety of situations that real-world data might not capture.
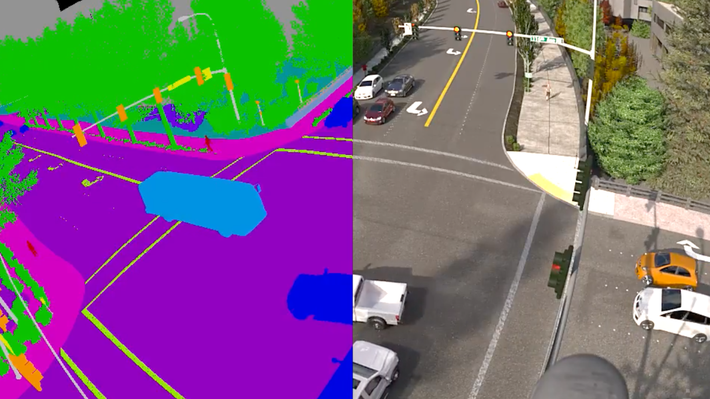
Companies have been using synthetic data to train computer vision algorithms — Credit: Unity3D
Another scenario in which companies use synthetic data is to make information available for processing when regulations or other privacy concerns restrict access to the original data. For instance, the processing of customer data in a post-GDPR world involves strict compliance and governance rules for companies.
In these cases, synthetic data is used as an anonymization method that brings companies more agility and freedom to process data in a safe and compliant way. This is what we focus on in this article, synthetic data in the context of privacy preservation.
Privacy-preserving synthetic data
When companies use synthetic data as an anonymization method, a balance must be met between utility and the level of privacy protection. In this context, utility refers to the analytical completeness and validity of the data. This means that synthetic data should provide, from an analytics point of view, the closest value to real-world data. Privacy refers to the protection of information on individual data. The method used to generate synthetic data will affect both privacy and utility.
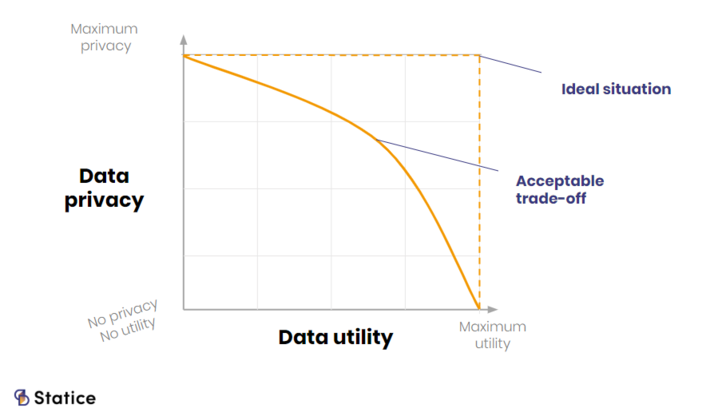
When working with synthetic data in the context of privacy, a trade-off must be found between utility and privacy.
For instance, the company Statice developed algorithms that learn the statistical characteristics of the original data and create new data from them. As a result, a synthetic dataset consists of new data points that preserve to a high degree the statistical properties and structure of the original dataset. This is done in order to maximize the utility of synthetic data.
We also implemented privacy mechanisms, so our algorithms generate privacy-preserving synthetic data. This means that private and sensitive information of an individual present in the original dataset will be protected after releasing the synthetic dataset.
For instance, one of these mechanisms is to train the model using algorithms that satisfy the definition of differential privacy. A model respecting this definition guarantees that the synthetic data is robust against all sorts of privacy attacks, for example, which could lead to the re-identification of an individual. The main premise of this approach is that in synthetic data produced with such a model, it is impossible to tell whether a single individual was part of the original dataset or not.
The properties of privacy-preserving synthetic data
Privacy-preserving synthetic data preserves to a high degree the properties and statistical information of the original data. This means that the utility of the synthetic data should be high enough to allow drawing similar conclusions as one would from the original data.
It retains the data structure of the original data. This means it should be possible to use the same code and tools on synthetic data than on the original data, without the need for any modification.
No information can be learned about a particular individual from privacy-preserving synthetic data. It should not be possible to tell whether a real-world individual was a part of the original dataset.

Properties of privacy-preserving synthetic data
The origins of privacy-preserving synthetic data
The idea of privacy-preserving synthetic data dates back to the 90s when researchers introduced the method to share data from the US Decennial Census without disclosing any sensitive information. The US Census Bureau has since been actively working on generating synthetic data.
While it has been around since the 90s, the last decade saw a growing interest from both the public and private sectors. In 2018, synthetic data and differential privacy were the subjects of an innovation challenge run by the US National Institute of Standards and Technology. In 2019, Deloitte and the World Economic Forum’s team released a study highlighting the potential of privacy-enhancing technologies, including synthetic data, in the future of financial services.
A reason for the growing interest in privacy-preserving synthetic data is the fact that it addresses some of the shortcomings of traditional “anonymization” methods, such as pseudonymization or k-anonymity. As I explained in a previous blog, not all anonymous data is created equal.
Some of the techniques currently used present limitations when it comes to guaranteeing the privacy or utility of the data. As a result, researchers are always looking for new or improved methods to overcome this trade-off between data utility and privacy. Today, privacy-preserving synthetic data represents an alternative to other traditional methods like pseudonymization.
How to generate privacy-preserving synthetic data
It’s important to note that different methods produce different types of synthetic data. As opposed to partially synthetic data, where only a selection of the dataset is replaced with synthetic data, fully synthetic data doesn’t contain any of the original data. Depending on the approach, privacy-preserving fully synthetic has the potential of providing a stronger privacy guarantee, without significant loss on utility.
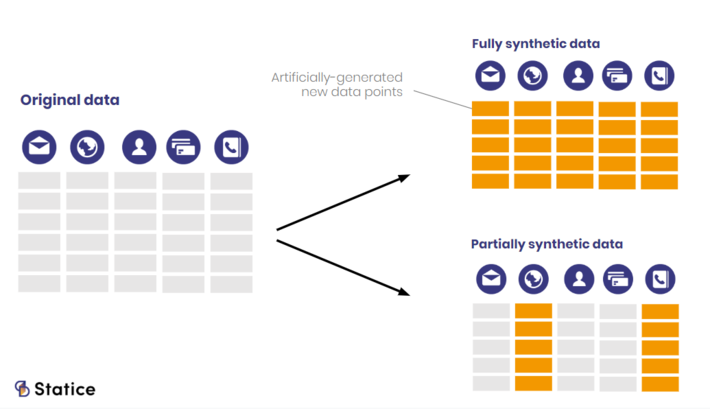
Illustration of fully synthetic data vs. partially synthetic data
One way of producing synthetic data is to use deep generative models. As the name suggests, these models are a way of generating data that rely on deep learning techniques. They can learn the statistical distribution underlying in the data in an unsupervised way and generate new data by sampling from it.
A famous example of leveraging deep generative models is the phenomenon of deep fakes. To create these artificial images or videos, algorithms train on real-word data to produce synthetic media that mimic the original subject but aren’t real. Similarly, if you train deep generative models on datasets containing people’s pictures, they can recreate synthetic faces mimicking human faces features. These new faces are entirely artificially generated.

Face samples, all completely fake, created by a deep generative model — see https://thispersondoesnotexist.com/
Generating privacy synthetic data is similar, except that the data we work with at Statice isn’t images or videos. Rather, our software can generate privacy-preserving synthetic data from structured data such as financial information, geographical data, or healthcare information.
Use-cases for synthetic data
Because it holds similar statistical properties as the original data, synthetic data is an ideal candidate for any statistical analysis intended for original data. A common use-case is thus to make data available for processing when regulations or other privacy concerns restrict access to the original data. This processing can be of multiple nature:
- Big data analysis: With synthetic data, organizations can run Business Intelligence analysis on sensitive data because its processing doesn’t fall under GDPR regulations.
- Training of machine learning algorithms: because of privacy constraints, accessing data to train a system is sometimes impossible, or it is a long and costly compliance process. With synthetic data, data operation teams can access training data way faster to build innovative products.
- Cloud processing: with non-compliant data, using public cloud infrastructures for processing data presents significant risks. With synthetic data, organizations can migrate and process data to public cloud infrastructure in a compliant manner.
- Internal or external data sharing: synthetic data enables organizations to access, share, and combine data internally or with partners. For example, when developing a new product, testing, or setting a hackathon that makes use of sensitive data, organizations can share it safely with other stakeholders.
Benefits of privacy-preserving synthetic data
Many organizations started using privacy-preserving synthetic data because it offers many benefits. One of the most significant ones is the ability to overcome sensitive data usage restrictions while safeguarding individuals’ privacy.
Indeed, in today’s highly regulated data landscape, processing data for secondary purposes, such as analysis, is often not only complex and time-consuming, but it also presents multiple security risks. With privacy-preserving synthetic data, an organization gets the ability to:
- Future-proof the compliance of data operations with safe data processing. Because synthetic data is anonymous, organizations using synthetic data aren’t at risk of being fined for non-compliance. Organizations reduce corporate and financial risks by complying with data regulations.
- Increase speed and boost agility when it comes to accessing data. With privacy-preserving synthetic data, the teams wanting to access internal sensitive data do not need to go through lengthy procedures. Organizations grow more agile with their data when it comes to internal sharing.
- Unlock any use of data without compliance concerns. From storage to monetization or processing of sensitive data, organizations are able to make the most out of any data assets with privacy-preserving synthetic data.
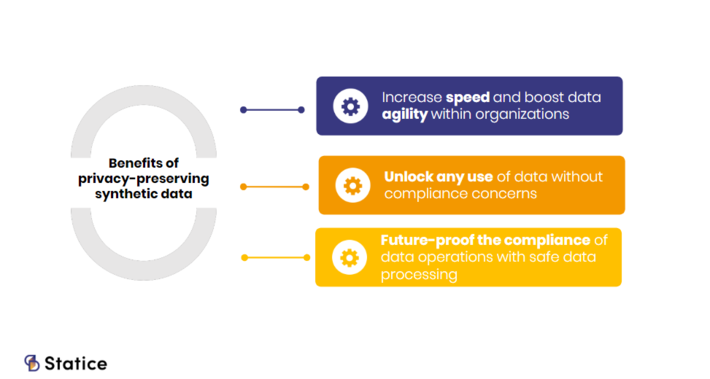
Benefits related to the use of privacy-preserving synthetic data
Besides the data anonymization field, another interesting aspect of working with synthetic data is that for large volumes of data, the production cost can be lower than for real-world data. Today, the training of machine learning and AI systems require huge amounts of data. Synthetic data offers a cost-effective alternative for organizations.
Synthetic data holds a lot of potentials. In essence, the idea of synthetic data is to be used just like real data, while protecting sensitive information and safeguarding the privacy of individuals. In a world where regulatory bodies are strengthening data protection laws, where citizens are asking for more privacy, and where data breaches are putting businesses and individuals at risk, privacy-preserving synthetic data can help companies protect their sensitive data while remaining data-driven and innovative.
{kind=link}