

Modern AI applications like autonomous vehicles, medical imaging, and satellite analysis require pixel-perfect visual understanding that traditional object detection cannot deliver. When an AI system misclassifies parts of an image or misses critical details, the consequences range from inefficient processes to potentially dangerous failures.
Semantic segmentation addresses this challenge by classifying every pixel in an image, creating a complete understanding of visual content. This approach enables AI systems to make precise decisions based on detailed scene comprehension.
Successfully implementing semantic segmentation requires thoughtful planning – from defining clear objectives and preparing quality datasets to selecting appropriate model architectures and integrating the solution into production systems.
This guide provides a structured approach to building effective semantic segmentation capabilities, helping you navigate key decisions and avoid common pitfalls throughout the implementation process.
Understanding semantic segmentation
Semantic segmentation is a deep learning technique that assigns each image pixel to a predefined category, creating a detailed map of visual content. Unlike object detection, it classifies at the pixel level rather than using bounding boxes.

Key differences
- Semantic Segmentation: Labels every pixel but does not differentiate between identical objects (e.g., multiple cars in a scene share the same label).
- Instance Segmentation: Similar to semantic segmentation but assigns unique labels to different instances of the same class.
- Object Detection: Identifies and localizes objects using bounding boxes without classifying individual pixels.
Benefits of AI workflows
- Better scene understanding for vehicles, medical imaging, and AR/VR.
- More precise decisions in applications needing pixel-accurate analysis.
- Better performance across varied datasets and real situations.
Before implementing semantic segmentation, it’s important to understand exactly what it is and how it differs from other computer vision approaches.
Key components of an AI pipeline for semantic segmentation
1. Data collection and annotation
High-quality annotations are essential for accurate semantic segmentation, helping reduce misclassification and improve AI decisions. Balanced classes, consistent labeling, and varied data sources all help models perform better and work well in new situations. The foundation of any successful segmentation model begins with properly annotated training data.
Here are the key annotated datasets commonly used for semantic segmentation:

2. Model selection
Selecting the right model architecture is crucial for effective semantic segmentation. Below are three widely used architectures, each offering unique advantages in different application scenarios:

3. Computational resources
Semantic segmentation needs substantial computing power for pixel-level processing. GPUs speed up training through parallel computing, while cloud-based GPU services offer flexible, cost-effective options without requiring hardware purchases.
With these components in mind, let’s examine a structured approach to implementation.
Step-by-step guide to implement semantic segmentation
When AI systems can classify each pixel in an image, they make better decisions, detecting defects or identifying objects in complex scenes. These six steps will help you gather good data, select the right models, and deploy solutions that improve with ongoing feedback.
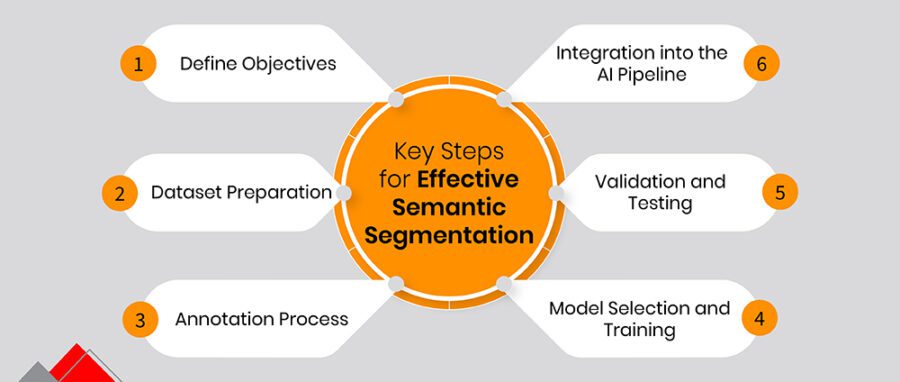
Step 1: Define objectives
Before diving into data collection or or training models, be clear about your project’s purpose. Are you improving automated inspections or finding manufacturing defects? Clear goals align team members and create measurable targets that will shape everything from annotation methods to model choices.
- Connect objectives to measurable results (like fewer errors or faster processing) to show business value.
- Review available resources early to match model complexity with your data and computing capabilities.
- Work with cross-functional teams to align technical work with business goals.
Step 2: Dataset preparation
When gathering images, it includes real-world conditions like different lighting, object sizes, and partial occlusions. Good preprocessing—cleaning and normalizing data—protects quality. Data augmentation adds variety, helping models handle different environments.
- Gather examples specific to your application (such as production line images or aerial photos).
- Remove duplicates, incorrect labels, and irrelevant samples to keep your dataset clean.
- Use transformations such as rotation, color adjustments, and cropping to create more diverse training examples and prevent overfitting.
Step 3: Annotation process
Select annotation tools that handle complex shapes and boundaries, so each region is marked accurately. Give clear instructions to annotators to reduce confusion and keep labeling consistent throughout your dataset.
- Use established labeling tools (like LabelMe or CVAT) that support polygon or brush-based marking methods.
- Train your annotation team to handle challenging cases such as overlapping objects or partially visible items.
- Create a quality check system where you regularly review random samples of annotations for accuracy and make corrections when needed.
Step 4: Model selection and training
Pick an architecture that matches your segmentation task. U-Net works well for medical images while DeepLab is better for recognizing objects at different sizes. Starting with pre-trained networks can save time and resources. Watch your computing limits and memory needs throughout training.
- Consider advanced models like SegNet or PSPNet for tasks needing detailed context understanding.
- Test different optimizers, batch sizes, and learning rates to improve training stability and prevent convergence problems.
- Save model checkpoints regularly so you can return to the best-performing version if performance declines.
Step 5: Validation and testing
Careful testing ensures your model performs well in real situations. Metrics like Intersection over Union (IoU) and Dice Coefficient measure how accurately your model segments images. Include challenging cases in your test data to find problems early. Regular validation helps you adjust settings and model structure for better results, ensuring reliability in real-world deployment.
- Use cross-validation to check if your model performs consistently across different data subsets.
- Compare training and validation losses to spot overfitting; add regularization when needed.
- Test on separate holdout data or real-world examples to confirm your model works well beyond your training examples.
Step 6: Integration into the AI pipeline
After testing, put your model into production. Using containers or serverless functions makes scaling easier and reduces management work. Monitor your system to catch data shifts or performance issues. Create feedback loops so your model can improve from new data as real-world conditions change.
- Build APIs so other services can easily use your segmentation model.
- Create alerts for unusual patterns, slow response times, or drops in segmentation quality.
- Plan regular retraining with new examples to keep your model effective as environments change.
Conclusion
Pixel-level understanding of visual data remains a critical challenge in computer vision that semantic segmentation effectively addresses. This guide outlines a methodical implementation approach – from setting clear objectives and preparing quality data to model selection, rigorous validation, and seamless integration.
The journey from raw images to production-ready semantic segmentation requires attention to detail at each step. Quality annotations establish the foundation, while appropriate model architecture and training strategies build reliability. Thorough validation ensures real-world performance, and thoughtful integration makes the solution accessible across your AI ecosystem.
As visual data continues to grow in volume and importance, organizations that master semantic segmentation gain a powerful advantage, enabling more accurate analyses, automated decision-making, and innovative applications that transform how they interact with visual information.
{kind=link}