

Introduction
Retrieval-augmented generation (RAG) models, more commonly known as RAG systems, are gaining significant attention in the AI industry. The concept behind the models is simple: instead of training a model on massive amounts of data, we allow the model to retrieve information from a separate dataset as they need it.
How could this improve machine learning models? Firstly, the process of training or fine-tuning a large language model (LLM) is extremely expensive, time-consuming, and tedious. It requires highly trained machine learning and AI practitioners. RAG systems utilize foundational LLMs and augment the input to keep your model up to date to the minute or second while still being able to incorporate new data. When new data is generated, it can be added to the retrieval database almost instantly.
In this article, we will focus on how to optimize RAG systems to be as efficient as possible. We’ll cover RAG systems from multiple perspectives, diving deeper into their purpose and how we can optimize them.
We will briefly explain Retrieval Augmented Generation but you can read more in-depth in a previous blog we wrote on how RAG makes LLMs smarter than before.
Understanding RAG models
As the name implies a RAG model is comprised of three main components: Retrieval, Augmentation, and Generation. These components represent the general workflow of the model, with each individual component including even more detail.
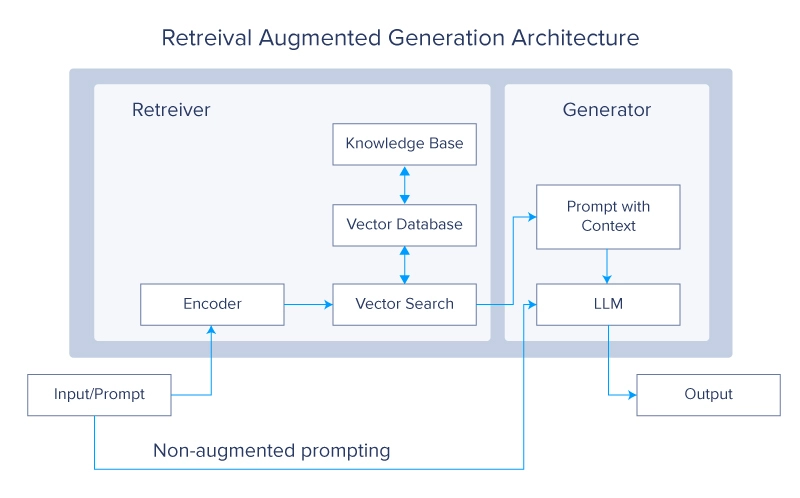
- Query Input – The process begins with the user inputting a query or prompt such as asking the LLM to perform a task like answering a question or helping with research on a topic. Depending on the model and its training data, you can either rely on the foundational model’s trained data, or you can rely on providing the model with data.
- Query Encoding – The query is encoded into a vector representation using an encoder model, typically a pre-trained language model like BERT or another transformer-based model. This vector representation captures the semantic meaning of the query.
- Information Retrieval – Using the encoded query vector, the system retrieves relevant documents or passages from supplied data. This retrieval step is crucial and can be implemented using various techniques like dense retrieval and sparse retrieval. Advanced indexing techniques can also be used to speed up the retrieval process. From the retrieved documents, the top-N candidates (based on relevance scores) are selected. These documents are considered the most relevant to the input query and are integral in generating the final response.
- Document Encoding – Each of the selected candidate documents is then decoded from vector representation to human-understandable language. This step ensures that the data retrieved will be used in the generation phase.
- Response Generation – The concatenated vector is fed into a LLM like GPT, Mistral, Llama, or others. The generator produces a coherent and contextually appropriate response based on the input. This response should ideally answer the query or provide the requested information in a clear and relevant manner.
So which areas of this process can we speed up? It’s in its name! We can optimize the R (retrieval), the A (augmentation), and the G (generation) in RAG.
Improving RAG retrieval – Increasing vectorization
An effective method to improve the performance a RAG system is by enhancing the vectorization process by increasing dimensions and value precision, creating more detailed and precise embeddings. The vectorization process transforms words or phrases into numerical vectors that capture their meanings and relationships and store them in a dimensional database. By increasing the granularity of each data point, we can hope to achieve a more accurate RAG model.
- Increasing Vector Dimensions – Increasing the number of dimensions allows the vector to capture more nuanced features of the word. A higher-dimensional vector can encode more information, providing a richer representation of the word’s meaning, context, and relationships with other words.
- Low-Dimensional Vector: Some basic embedding models might transform a word into a 512-dimensional vector.
- High-Dimensional Vector: More complex models can transform a word into a vector with over 4,000 dimensions.
- Improving Value Precision – By increasing the range of values, you enhance the granularity of the vector representation. This means that the model can capture subtler differences and similarities between words, leading to more precise and accurate embeddings.
- Low-Precision Vector: In a simple model, a field value might range from 0 to 10.
- High-Precision Vector: To increase precision, you could extend this range from 0 to 1,000 or even higher. This allows the model to capture more accurate values. For instance, human age generally ranges from 1 to 100, so a 0 to 10 range would lack the necessary capabilities for accurate representation. Expanding the range enhances the model’s ability to more accurately reflect real-world variations.
However, it’s important to note that these optimizations come with trade-offs. Increasing both the vector dimensions and precision values of the system will result in a larger, more storage and computationally intensive model.
Improve RAG augmentation – Multiple data sources
In a Retrieval-Augmented Generation (RAG) system, the retrieval component is responsible for fetching relevant information that the generative model uses to produce responses.
By incorporating multiple data sources, we can significantly enhance the performance and accuracy of the RAG system. This approach, known as augmentation optimization, leverages a variety of information repositories to provide richer and more comprehensive context, which eventually leads to better responses. Here a some examples:
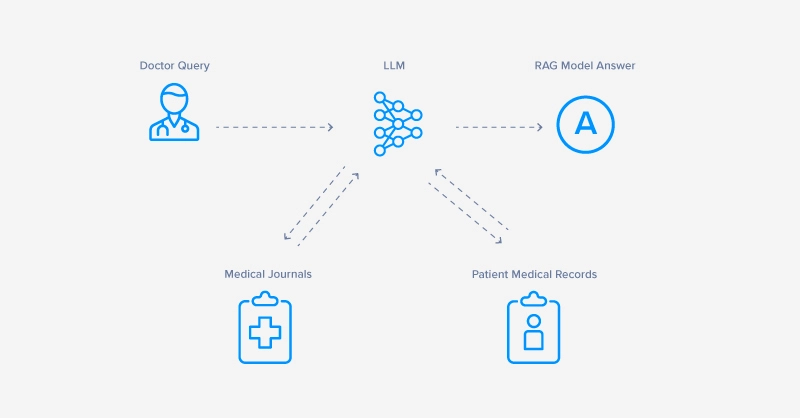
- Healthcare – RAG systems designed to assist doctors by answering complex medical queries benefit from retrieving information from medical journals and patient medical records to craft tailored responses.
- Law – RAG systems designed to assist lawyers in case research can benefit from retrieving information across multiple related cases. By vectorizing the topics within each case, the RAG model can, when prompted, identify which case can be used to support or argue a legal position.
- Technical Documentation – For any product, software, hardware, or even board games, a RAG LLM to answer FAQs can dramatically help the consumer obtain quick responses without needing to read extensive owner manual jargon.
Improving RAG generation – Choosing the optimal model
Although utilizing state-of-the-art LLMs can often promise superior content generation and analysis capabilities when it comes to implementing a Retrieval-Augmented Generation (RAG) system, opting for the most complex LLMs isn’t always the best choice.
Below are five points to focus on when utilizing the generation part of your RAG system.
- Complexity vs. Efficiency – While advanced LLMs like GPT or Llama are powerful, they come with significant computational costs and resource requirements. Integrating these models into a RAG system may introduce latency issues or strain computational resources, especially in scenarios requiring real-time response capabilities.
- Use Case – The effectiveness of a RAG based LLM depends heavily on the specific use case and domain requirements. In some cases, a simpler fine-tuned model may outperform a more complex, general-purpose LLM. Tailoring the choice of model to the application’s needs ensures that computational resources are efficiently utilized without compromising on performance. Read more on when to fine-tune versus RAG for LLMs.
- User Experience and Responsiveness – For applications where responsiveness and real-time interaction are critical, prioritizing speed and efficiency in a smaller LLM can enhance user experience. A streamlined approach that balances computational efficiency with effective content generation ensures that users receive fast and relevant responses.
- Cost Considerations – Deploying complex RAG-based LLMs may involve higher hardware and/or operational costs. Evaluate the operational objective and weigh the benefits against the costs to make informed decisions on investing in a highly complex RAG deployment.
Improving RAG model’s speed – hardware
The immense value of RAG-based LLMs is popularized by their potential for optimized, cost-effective, and efficient usage. These extensions are already providing a powerful way to enhance the capabilities of LLMs by allowing them to retrieve and incorporate up-to-date information, ensuring your models remain relevant and accurate.
However, improving the RAG system in every possible lead to other considerations. Increasing vector precision enhances retrieval accuracy but leads to higher computational costs longer training times, and slower inferencing response speed. The most effective RAG system is the one that’s tailored to your unique needs and objectives to optimal performance without compromising overall effectiveness. Customizing your RAG system to align with your specific use cases, data sources, and operational requirements will provide the best results.
The same goes for the system that stores your data and powers your RAG. High-performance hardware is in high demand to deliver the best performance against competitors in the AI industry. But these systems are rarely one-size-fits-all. At Exxact, our goal is to tailor the right system unique to your needs and objectives within a fixed budget without compromising performance. With over 30 years of expertise, we have built systems for various workloads working with AI startups, renowned research institutions, and Fortune 500 companies. Our expertise is in your hands to configure the best data center infrastructure to power your innovations to be shared with the world.
{kind=link}