
This article was written by Montana Low.
An open source framework for configuring, building, deploying and maintaining deep learning models in Python.
As Instacart has grown, we’ve learned a few things the hard way. We’re open sourcing Lore, a framework to make machine learning approachable for Engineers and maintainable for Machine Learning Researchers.
Common Problems
- Performance bottlenecks are easy to hit when you’re writing bespoke code at high levels like Python or SQL.
- Code Complexity grows because valuable models are the result of many iterative changes, making individual insights harder to maintain and communicate as the code evolves in an unstructured way.
- Repeatability suffers as data and library dependencies are constantly in flux.
- Information overload makes it easy to miss newly available low hanging fruit when trying to keep up with the latest papers, packages, features, bugs… it’s much worse for people just entering the field.
To address these issues we’re standardizing our machine learning in Lore. At Instacart, three of our teams are using Lore for all new machine learning development, and we are currently running a dozen Lore models in production.
TLDR
If you want a super quick demo that serves predictions with no context, you can clone my_app from github. Skip to the Outline if you want the full tour.
Feature Specs
The best way to understand the advantages is to launch your own deep learning project into production in 15 minutes. If you like to see feature specs before you alt-tab to your terminal and start writing code, here’s a brief overview:
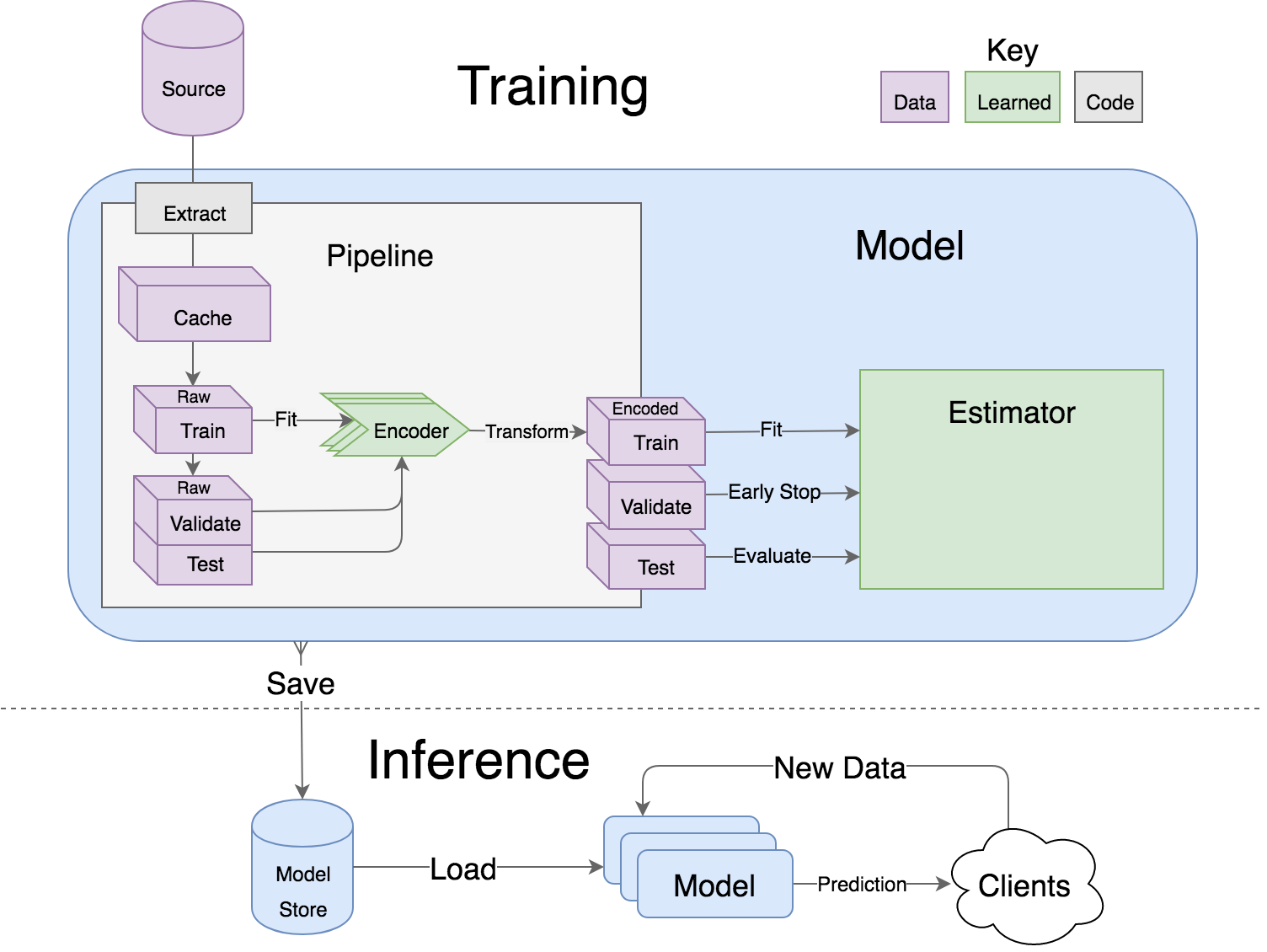
- Models support hyper parameter search over estimators with a data pipeline. They will efficiently utilize multiple GPUs (if available) with a couple different strategies, and can be saved and distributed for horizontal scalability.
- Estimators from multiple packages are supported: Keras, XGBoost and SciKit Learn. They can all be subclassed with build, fit or predictoverridden to completely customize your algorithm and architecture, while still benefiting from everything else.
- Pipelines avoid information leaks between train and test sets, and one pipeline allows experimentation with many different estimators. A disk based pipeline is available if you exceed your machines available RAM.
- Transformers standardize advanced feature engineering. For example, convert an American first name to its statistical age or gender using US Census data. Extract the geographic area code from a free form phone number string. Common date, time and string operations are supported efficiently through pandas.
- Encoders offer robust input to your estimators, and avoid common problems with missing and long tail values. They are well tested to save you from garbage in/garbage out.
- IO connections are configured and pooled in a standard way across the app for popular (no)sql databases, with transaction management and read write optimizations for bulk data, rather than typical ORM single row operations. Connections share a configurable query cache, in addition to encrypted S3 buckets for distributing models and datasets.
- Dependency Management for each individual app in development, that can be 100% replicated to production. No manual activation, or magic env vars, or hidden files that break python for everything else. No knowledge required of venv, pyenv, pyvenv, virtualenv, virtualenvwrapper, pipenv, conda. Ain’t nobody got time for that.
- Tests for your models can be run in your Continuous Integration environment, allowing Continuous Deployment for code and training updates, without increased work for your infrastructure team.
- Workflow Support whether you prefer the command line, a python console, jupyter notebook, or IDE. Every environment gets readable logging and timing statements configured for both production and development.
To read the whole article, click here.
{kind=link}