

Large language models (LLMs) fit parameters (features in data topography) to a particular dataset, such as text scraped off the web and conformed to a training set.
Logical data models (LDMs), by contrast, model what becomes shared within entire systems. They bring together the data in a system with the help of various kinds of logic. As such, they are a primary means of managing the data in a system, the connecting glue that brings the system together and makes the data foundation reusable as a whole.
Knowledge graphs provide an any-to-any means of connecting and articulating the meaning of data in a system. At the heart of each knowledge graph is an extensible graph data model called an ontology. The ontology contextualizes the disparate instance data brought into the graph. Ideally, it makes all data in the graph findable, accessible, interoperable, and reusable (FAIR).
Once connected and contextualized, the data in the system becomes a holistic search, data management and decision making resource, rather than just a collection of stranded datasets.
Ontologies in graphs can be used directly: Conceptual, logical and physical are all created at the same time. And given the right design, they can be reliably generated.
In that sense, a knowledge graph is the data fabric. It is the data mesh. It is the key means businesses can use to transform information systems, by harnessing the knowledge power of ontologies within the context of extensible, articulated, graph-connected data.
Data modeling and management at scale versus data sprawl
Businesses have a choice. They can transform their systems using a knowledge graph approach, a feasible means of systems transformation at scale by modeling the essence of what they do and how so that it’s available to both humans and machines. Or they can continue to add to the data sprawl they already have.
Unnecessary complexity gets in the way of transformation, so it’s important to consider how to reduce complexity rather than add to it. Dave McComb, author of Software Wasteland, in a Business Rules Community interview : “Starting with a single, simple core data model is the best prescription to reducing overall complexity. Most application code — and therefore most complexity — comes from the complexity of the schema the code is written to.
How’s the model useful? Later in this interview, McComb says, “I often ask professionals to imagine what a data lake would be like if they could build transactional applications directly on, and write to, the data lake. This is essentially the goal of a data-centric architecture: to be able to read and write to a single, simple, shared data model, with all the requisite data integrity and security required in enterprise applications.”
How shared data models are evolving in the public sector
The Dataverse Project began in 2006 with a common repository framework that allowed researchers to “share, find, cite, and preserve research data. The Dataverse is for all, including individual researchers who need to make their datasets accessible to others “
The Project’s mandate is broader today: To provide a global, open source data management and sharing solution for researchers. Researchers can set up their own Dataverses and federate their data with others. Ideally, they will all be able to search across Dataverses. The Project has over 100 installations worldwide.
It’s interesting to see how the Project’s methods are evolving along with its mandates. Slava Tykhonov, a researcher at Data Archiving and Networking Services (DANS-KNAW) in the Netherlands, presented in August 2023 on his efforts in collaboration with Jim Myers, who’s a senior developer and architect for the Global Dataverse Community Consortium.
DANS’ Dataverse installation has what it calls Data Stations, which are operational and planned data services based on Dataverse technology. The data stations Tykhonov mentioned include the DataverseNL, Data Vault, Social Sciences, Humanities, Archaeology, and Generic. DANS is using international projects to extend the technology, make it more robust and interoperable.
Tykhonov noted that earlier attempts at interoperability involved mapping across conventional metadata schemas, which worked to some extent. But now the goal is to add Linked Data/semantic web technology and global knowledge graphs, with Dataverse instances conceived as nodes in an interlinked data network.
Controlled vocabularies and the interconnecting logic of knowledge graphs
More specifically, Tyknonov and Myers are working on providing external controlled vocabulary (CV) support to Dataverses. Researchers in individual domains have been modelling their own domains, and each CV can be considered a subgraph designed to be connectable to other subgraphs, whether instance or logical model data (descriptions, declarations and rules).
The external controlled vocabulary support Tykhonov refers to is key to adhering to findable, accessible, interoperable and reusable (FAIR) data principles for Dataverse data management purposes. The CV support was first developed and later written up as a part of the Horizon 2020 project funded by the SSHOC EU. This diagram provides an overview of the SKOSMOS plug-in CV support architecture:

Myers and Tykhonov, “A Plug-in Approach to Controlled Vocabulary Support in Dataverse,” Dataverse Project Community (Zenodo) site, August 2023.
So how does the SKOSMOS help with interoperability? The logic of scientific research domains is captured in these various interrelated controlled vocabularies. In other words, scientists have described how domains and the terms that describe them work together. And Tykhonov and Myers are linking those CVs to the previous metadata schemas to scale the interconnection and discovery process with description logic.
Controlled vocabularies are just one variety of logical modeling that can be used to federate the likes of graph-enabled repositories. They are on the humble side of strong semantics and interoperability, but are certainly a necessary and viable starting point. The diagram below puts controlled vocabularies, thesauri, etc. within the context of other complementary logical semantic modeling methods that can help with interoperability.
Building context and reasoning capability into semantic metadata
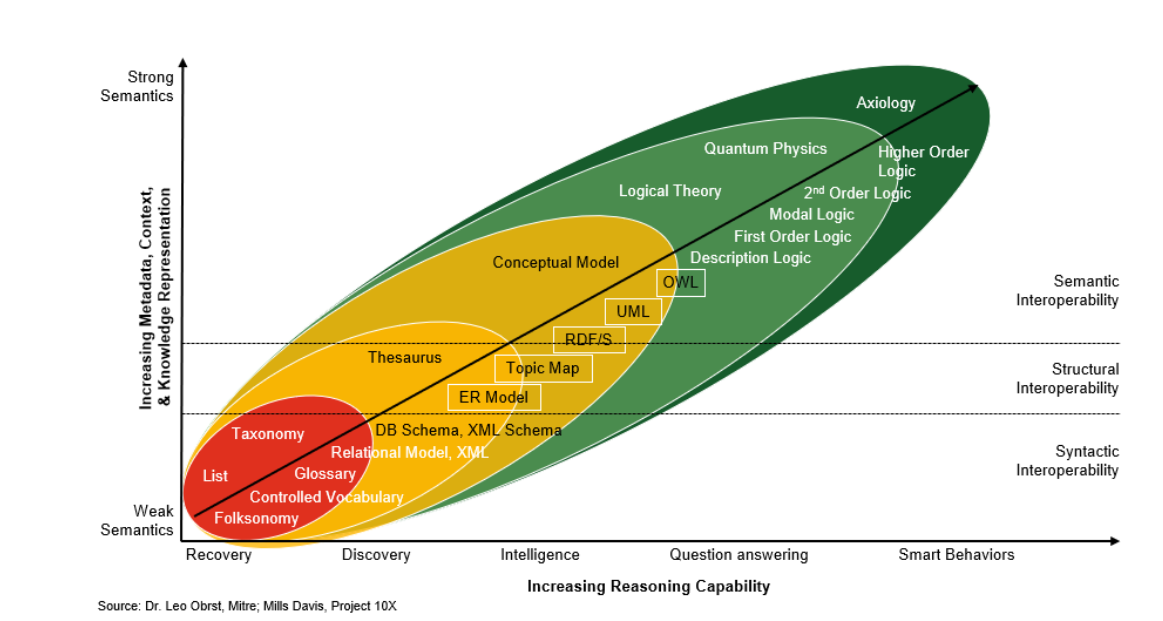
Using CV metadata as a “supervisor” within an LLM context
As I understand it, Tykhonov has been interacting with Meta’s Llama (an LLM) to give Llama a way to retrieve answers accurately from the Dataverse network to questions that aren’t in the Llama dataset with the help of SPARQL (a standard knowledge graph query language) queries.
This is similar to what Denny Vrandečić of the Wikimedia Foundation spoke about at the Knowledge Graph Conference earlier this year–i.e., augmenting an LLM’s capabilities with a knowledge graph’s capabilities, as well as the capabilities of other tooling. LLMs, Tykhonov points out, can be prompted to answer in JSON-LD. Knowledge graphs can ingest JSON-LD directly.
The evident promise is a multi-capability feedback loop could cure some of the major ills that LLMs have as a standalone resource. Vrandečić also mentioned that LLMs are far too expensive for questions that could be easily asked via knowledge graphs.
Cost factors are first among the many issues that we’ll have to address by stepping back and evaluating how whole systems should evolve in light of LLM advances.
References
Tykhonov, Vyacheslav. (2023, August 22). Knowledge Graphs and Semantic Search in Dataverse. Zenodo.
James D. Myers, & Vyacheslav Tykhonov. (2023). A Plug-in Approach to Controlled Vocabulary Support in Dataverse.
{kind=link}