

By Ari Kamlani, Senior AI Solutions Architect and Principal Data Scientist at Beyond Limits
Rogue AI, or an autonomous artificial intelligence system that commits potentially dangerous acts, may take many forms and can bring with it varying levels of severity, threats, or harm. Intelligent systems, while incredibly useful and full of great potential, can still malfunction, exhibiting misbehavior in an unexpected and undesirable manner. Some of these malfunctions may be known and articulated when designing the system, but oftentimes, many may fly under the radar due to learned behavior, lack of behavioral testing, or because they only emerge when exposed to different environments than intended.
This could take the form of an airplane malfunctioning mid-flight, causing the system to maneuver and navigate incorrectly. Data breaches that occur on a system protected by AI, exposing confidential or proprietary information, that may not be encrypted or redacted. There have been countless occurrences of companies exposing private data, either due to incorrect or no company policies in place or cybersecurity incidents — rogue AI may further complicate these situations.
Beyond the misbehavior, AI systems can be easily misused by organizations and individuals when put into practice. Today, companies must understand what rogue AI is, the risks it poses, and how they can responsibly prepare their AI systems to prevent rogue outcomes.
Understanding Rogue AI
Today, unless an AI system was specifically designed to be a malevolent security threat, the threat of rogue AI wreaking havoc is small. AI is not and will not become self-aware (at least, not anytime soon). The real threats are autonomous AI systems designed to respond to perceived threats.
In contrast to the better performing models — the “offensive” side of AI — rogue AI focuses on the “defensive” side, understanding, reasoning, and being proactive to protect and prevent conditions of what can go wrong. This is common in the info security space, where ‘red teams’ are integrated internally to play an adversarial role.
For example, an automated nuclear response system that is designed to fight back in case human leaders were unable to respond to an attack. At a high-level, the system would monitor channels for nuclear attack, and if detected, alert response channels. If all response channels were unresponsive, the AI might assume they were incapacitated and initiate an automated retaliation. It is possible to “jailbreak AI” or trick it such a system into believing there is an attack and that it cannot get a response, leading to inadvertent nuclear war.
While this is not technically “rogue,” the AI could pose a security threat simply because of how the system is designed. While many less existential scenarios exist, the important message is that security threats emerge because of how AI and systems interact, are built and used, not because of the AI itself.
Weighing the Potential Risk
When AI is deployed, progressing from sensory behavior towards that of judgement, decision control, and actions, undesirable behavior can have potentially dangerous effects. When humans transfer partial or full control to an intelligent system to influence decisions or act, there is a risk of placing trust where it shouldn’t be.
For example, if an illogical or immoral recommendation is given to a person, they can judge its utility and decide to pivot, try again, or optimize. But if this control is transferred to intelligent systems, not only may error rates potentially increase, those responses or actions could be highly questionable. This feedback loop is highly desirable and important when the actions and errors have high risk, impact, or decisions have high uncertainty.
Large language models (LLMs) and dialogue engines may be intentionally instructionally misled and other systems may suffer from data quality issues, like a prediction model training on a bad sensor feed. While it is possible to build protections to safeguard scenarios, there have been many scenarios with conversational dialects where these conditions have gone unforeseen.
As not all behaviors and errors are equal and the risk and severity of conditions progress, the underlying consequences can have long-lasting effects and take long cycles to recover from. It is important to identify and understand who the harm applies to (e.g., individuals, groups, organizations, ecosystems) and in what context (e.g., harm to interrelated systems within the global financial system).
The World is Changing
Traditionally, AI model development has been heavily dependent on having a good sampling representation of historical data that maps well to the applied use cases. However, it is unlikely that the industry will be able to continuously capture data and events to guard against. Instead, it will always have a very limited narrow view or biased view based on the context and scenario relative to the application usage.
Fundamentally, the way humans communicate and express intent and preferences with intelligent models is constantly changing. This can be seen particularly in the context of probing and prompting with large parameterized generative models.
A Framework for Rogue AI
As misaligned AI behavior is dependent on the environment and scenarios it operates in, what fits for one organization may be totally inadequate for another. Having a structured set of methods can help organizations stay ahead of the curve, mitigating the effects of potential harmful threats. For example, companies that operate in a highly regulated environment, such as the financial, healthcare, or energy sector, will need to place higher weight on compliance with government and state policies.
Below is a diagram of an opinionated point of view (POV) systematic framework on how to approach rogue AI. There are already existing frameworks not specific to rogue AI, such as the NIST AI Risk Management Framework.
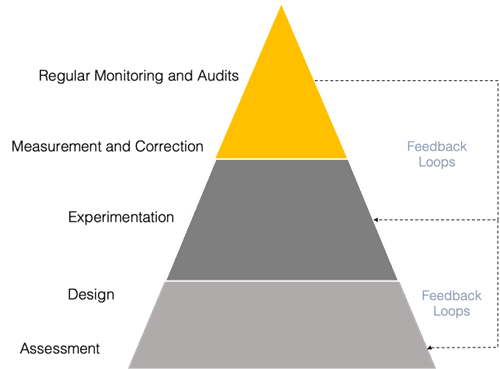
Assessment
Organizations and divisions within should take stake with performing an end-to-end (E2E) lifecycle audit or assessment of the current stakes of their businesses processes. The below questions should be asked during this process:
- Who are the users of the system and are they using it a responsible manner?
- What are the known conditions of the bad actors?
- What were the unknown conditions that occurred that had not been planned for?
- Had bad design decisions been encountered throughout the lifecycle?
Design
Identification: Organizations must identify what can go wrong in the context of in-real-life applied contextual scenarios. Listing the potential weaknesses, vulnerabilities, and violations where AI can be misused or misbehave is necessary. In mitigating harm, it is important to recognize not only the events and scenarios, but who the responsible parties are that will utilize and deploy or distribute the applied usage of AI.
Definition: Defining the risk class of severity taxonomy and associated per violations in the identification phase is the next step. Implementing a classification taxonomy and identifying boundaries based on assumptions and intended behavior can ensure the appropriate guardrails are put in place and the level of AI involvement in important decisions.

When progressing higher up the stack, higher cases of risk and harm are introduced — it is important to mitigate exposure to risk when moving up the rack.
Mapping: Finally, map out which failure modes are riskier than others, when those events are triggered, the risk impact associated with them and measurement dimensions such as frequency, recency, recurrence.
For scenarios where it may be impossible to enumerate all risky situations, such as long tail or insufficient negative training data (behaviors that should never occur), best practices should be created and observed.
In recent years, different AI research and development (R&D) disciplines have used some form of ‘checklist,’ such as those for behavioral testing in natural language and recommender systems to reduce undesirable behavior and cut down risks. However, this assumes, individuals or corporations explicitly know the characteristics to guardrail and test against at reasonable scale.
Experimentation
For the experimentation set in the framework, organizations can follow several key practices:
- Decomposition: Decompose and select a series of experiments to de-risk how AI may be misused or may misbehave based on the risk class severity, input context, or decision making. Select a set of experiments to execute for where AI is appropriate to be used.
- Sequencing: From a sequence of trials, execute a series of “connected” progressive experiments, to test and gather more evidence, validating or invalidating any assumptions, further prioritizing and ranking. As the industry gains maturity in the experiments, reducing uncertainty, launching limited pilots in a trustworthy and safe manner will be realistic. These experiments will help provide a better vision.
- Protection: Further introduce protection, safety, privacy, and/or secure policy control higher-level layers that will guard against AI being misused a reliable manner, incorporating multiple redundant fail-safes. Decide where it is appropriate to have a human-in-the-loop (HITL), intervening and acting on suggestions or decisions, and limiting the decisions of automation. While automation principles may seem desirable for scaling across responsiveness and cost perspectives, they can also have an undesirable effect for organizations and individuals.
As noted in assessment and sesign sections, there may be many too many conditions to test for, many of which may be unknown. In the context of rogue AI, a good starting point is to check for these high impact usage and behavior patterns that have high utility and frequency. However, it is important that experiments are also executed for those more severe risk classes, even if rare, that may be at the long tail.
Measurement and Correction
The steps for measurement and correction include steering, mitigation, and the creation of policies:
- Steering: What was learned from these experiments? How could the organization course-correct and steer AI in a better manner, ensuring that behaviors are not poorly aligned with human values. There is the possibility that the system may not have been trained to be well aligned, such as that form biased pre-training data. In this next wave of AI, companies should expect the nudging and steering of AI to be a major focus.
- Mitigation: Organizations must ensure a plan is in place to limit potential threats and correct, mitigate, and normalize behavior. Having a plan to address mitigate and response to incidents based on the severity can help. Ensuring guardrails are put in place, connected to the appropriate risk class and risk score, based on experimentation and assumptions or hypotheses that need to be corrected, is crucial.
- Policies: With questions surrounding AI to be governed and regulated, the applied misuse or harm may warrant rethinking if the risk is too large to not have oversight. For example: the establishment of global conventions and guidelines for the use of AI in military and life-serving infrastructure (such as water, food, electricity, etc.) and beyond.
Regular Monitoring and Audits
As AI is undergoing dramatic shifts in much shorter periods of time, regular monitoring and audits should be put in place to review and update the system. This may look like monitoring for performance instability, placing new safeguards, reviewing for potential new threats, or needs for regulations at a local or global scale.
With these regular audits will come a need for continual transformation. In cases where AI was deemed not appropriate before, organizations should check if these conditions still hold true.
Staying Prepared
As digital products and services are augmented with AI, complex challenges are introduced. Regardless of the industry, organizations will need to continually transform and evolve, in an agile and iterative fashion that demonstrates technology maturity. In this new wave of AI, transformational shifts are occurring in days and months, not years. While it is important to evaluate trade-offs in decision making, businesses shouldn’t overinvest on a particular dimension, that may easily be prone to change.
While “rogue AI” that becomes sentient and works against humans likely won’t happen in this lifetime, it is still important for the industry to adopt standards to protect the world from poorly designed AI systems. These standards can take the form of well published guidelines and frameworks from associations, best practices adopted by the industry, policies set forth via internal governance divisions, or internal steering committees to contextualize safety and malicious concerns for the business.
Organizations must have an incentive to install proper procedures to prepare for these undesirable behaviors, limit adoption of misuse, and limit the potential negative effects of autonomous AI systems.
{kind=link}