

20 years ago, most CIOs didnt care much about data, but they did care about applications and related process optimization. While apps and processes were where the rubber met the road, data was ephemeral. Data was something staffers ETLed into data warehouses and generated reports from, or something the spreadsheet jockeys worked with. Most of a CIOs budget was spent on apps (particularly application suites) and the labor and supporting networking and security infrastructure to manage those apps.
In the late 2000s, and early 2010s, the focus shifted more to mobile apps. Tens of thousands of large organizations, whod previously listened to Nick Carr tell them that IT didnt matter anymore, revived their internal software development efforts to build mobile apps. And/or they started paying outsiders to build mobile apps for them.
At the same time, public cloud services, APIs, infrastructure as a service (IaaS) and the other the Xs as a service (XaaS) began to materialize. By the late 2010s, most large organizations had committed to migrating to the cloud. What that meant in practice meant that most large businesses (meaning 250 or more employees) began to subscribe to hundreds, if not thousands, of software-as-a-service (SaaS) offerings, in addition to one or more IaaSes, PaaSes, DBaaSes and other XaaSes.
Business departments subscribed directly to most of these SaaSes with the help of corporate credit cards. Often a new SaaS suggests a way department managers can get around IT bureaucracy and try to solve the problems IT doesnt have the wherewithal to address. But the IT departments themselves backed the major SaaS subscriptions, in any case–these were the successors of application suites. Networking and application suites, after all, were what IT understood best.
One major implication of XaaS and particularly SaaS adoption is that businesses in nearly all sectors (apart from the dominant tech sector) of the economy have even less control of their data now than they did before. And the irony of it all is that in 99 percent of the subscriptions, according to Gartner, any SaaS security breaches through 2024 will be considered the customers fault–regardless of how sound the foundation for the SaaS is or how its built.
The end of AI winter…and the beginning of AI purgatory
20+ years into the 21st century, data shouldnt just be an afterthought anymore. And few want it that way. All sorts of hopes and dreams, after all, are pinned on data. We want the full benefits of the data were generating, collecting, analyzing, sharing and managing, and of course we plan to generate and utilize much more of it as soon as we can.
AI, which suffered through three or four winters over the past decades because of limits on compute, networking and storage, no longer has to deal with major low temperature swings. Now it has to deal with prolonged stagnation.
The problem isnt that we dont want artificial general intelligence (AGI). The problem is that the means of getting to AGI requires the right kind of data-centric, system-level transformation, starting with a relationship-rich data foundation that also creates, harnesses, maintains and shares logic currently trapped in applications. In other words, we have to desilo our data and free most of the logic trapped inside applications.
Unless data can be unleashed in this way, contextualized and made more efficiently and effectively interoperable, digital twins wont be able to interact or be added to systems. Kevin Kellys Mirrorworld will be stopped dead in its tracks without the right contextualized, disambiguated and updated data to feed it.
As someone who tracked many different technologies and how they are coming together, there’s a particular feeling of frustration that brought to mind a story I read awhile back. 117 years ago, The Strand Magazine published a short story by H.G. Wells — a parable, really — called The Country of the Blind. The parable is about a mountain climber named Nunez who has all of his faculties, including sight. Nunez after a big climb falls down the remote slope of a South American mountain. He ends up in a village consisting entirely of blind people.
Once Nunez lives among the villagers for a bit and learns theyre all blind, Nunez assumes he can help them with his gift of sight. In the Country of the Blind, the one-eyed man is king, he repeats to himself.
The thing is, the villagers dont believe in the sense of sight. They dont take any stock in what Nunez is saying. Finally, realizing he cant help them, Nunez leaves and starts to climb back up the mountain. In a 1939 update to the story, Nunez notices a rockslide starting, and calls out to the villagers to save themselves. They again ignore him. The rockslide buries the village.
The data-centric architecture that AGI requires
Nowadays, data can be co-mingled with some logic in standard knowledge graphs. In these knowledge graphs, description logic, (including relationship logic, which contextualizes the data so it can be shared and reused) and rule logic together with data become a discoverable, shared and highly scalable resource, a true knowledge graph that allows the modeling and articulation of business contexts that AGI demands..
With a properly formed knowledge graph as the foundation, data-centric rather than application-centric architecture, as Dave McComb of Semantic Arts pointed out in Software Wasteland and the Data-Centric Revolution, can become a means of reducing complexity, rather than adding to it. Even more importantly, these knowledge graphs are becoming a must-have for scalable AI operations, in any case.
Sounds great, doesnt it? The thing is, even though these methods have been around for years now, Id guess that less than one percent of those responsible for AI in enterprise IT are aware of the broad knowledge graph-based data and knowledge management possibilities that exist, not to mention the model-driven development possibilities. This is despite the fact that 90 percent of the companies with the largest market capitalizations in the world have been using knowledge graphs for years now.
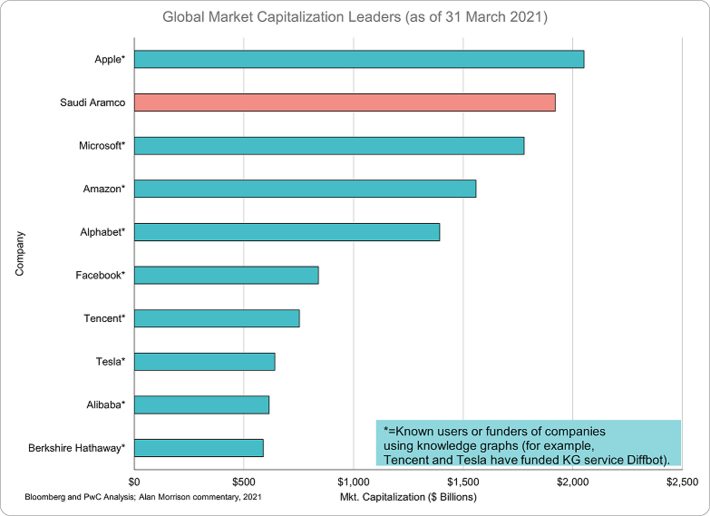
Why such a low level of awareness? Most are too preoccupied with the complexities of cloud services and how to take best advantage of them to notice. If they are innovating on the AI/data science front, theyre consumed with small, targeted projects rather than how systems need to evolve.
17 years after Nick Carrs book Does IT Matter? was published, most are still focused on the faucet, when the rest of the Rube Goldberg-style data plumbing has long ago become rusty and obsolete and should have been switched out years ago.
Should software as a service come with a warning label?
Which begs the question–why should we trust the existing system at all, if as McComb points out, its so duplicative, antiquated, and wasteful? Its easy to make the case that we shouldnt: Considering that so few know about how true data-centric systems should be designed, commercial software should come with prominently placed warning labels, just like drugs do.Thats even more the case with software thats data-dependent–AI-enhanced applications, for instance.
This is not to mention that many B2C SaaSes are basically giant data farming, harvesting and personalized advertising operations, platforms that require high data-dependent machine-learning loops. From a privacy and security perspective, much of the risk comes from data farming, storing, duplicating and distributing. Most major B2B SaaSes, for their part, are designed to take best advantage of customer data–but only within the SaaS or the providers larger system of systems.
Shouldnt we put warning labels on SaaSes if billions of people are using them, especially while those SaaSes are using archaic forms of data and logic management that dont scale? Some of the necessary cautions to those who dare to use todays more ominous varieties of AI-enhanced, data-dependent and data-farming software that come to mind include these:
|
Suggested warning to new users |
Principle to counter implicit risk |
|
This new AI-enhanced technology, even more than most previous software technologies in use, has been developed in a relative vacuum, without regard to broader, longer-term consequences or knock-on effects. |
Murphys Law (anything that can go wrong, will go wrong) applies when adding this software to operational systems.Relevant backup plans and safety measures should be put in place prior to use. |
|
This social media platform utilizes advanced gamification techniques designed to encourage high levels of use. When excessive use is coupled with the platforms inherently broad disinformation campaign distribution abilities at web scale, the risk of sociopolitical destabilization may increase dramatically. |
The principle of Occams Razor (the simplest answer is usually correct) is a good starting point for any assessment of widely believed but easily discreditable theories and assertions (e.g., COVID-19 isnt real) in postings you come across, like, or share that depend on high numbers of assumptions.Consider carefully the disinformation proliferation risks that will result. |
|
A typical medium to large-sized organization is likely to have subscriptions to hundreds or thousands of software-as-a-service platforms (SaaSes).
Are you sure you want to subscribe to yet another one and add even more complexity to your employers existing risk, compliance, application rationalization and data management footprint? |
McCombs Cost of Interdependency Principle applies: Most of the cost of change is not in making the change; it’s not in testing the change; it’s not in moving the change into production.
Most of the cost of change is in impact analysis and determining how many other things are affected. The cost of change is more about the systems being changed than it is about the change itself. Please dont keep adding to the problem. |
|
This form requires the input of correlatable identifiers such as social security, home address and mobile phone numbers that could afterwards be duplicated and stored in as many as 8,300 or more different places, depending on how many different user databases we decide to create, ignore the unnecessary duplication of, or sell off to third-party aggregators we have no control over and dont have the resources or desire to monitor in any case. |
The Pareto Principle (80 percent of the output results from 20 percent of the input) may apply to the collectors of personally identifiable information (PII) management, i.e.,one out of five of the sites we share some PII with might be responsible for 80 percent of that PIIs proliferation. Accordingly, enter any PII here at your own risk. |
As you might be able to guess from a post thats mostly a critique of existing software, this blog wont be about data science, per se. It will be about whats needed to make data science thrive. It will be about what it takes to shift the data prep burden off the shoulders of the data scientist and onto the shoulders of those wholl build data-centric systems that for the most part dont exist yet. It will be about new forms of data and logic management that, once in place, will be much less complicated and onerous than the old methods.
Most of all, this blog will be about how systems need to change to support more than narrow AI. All of us will need to do what we can to make the systems transformation possible, at the very least by providing support and guidance to true transformation efforts. On their own, systems wont change the way we need them to, and incumbents on their own certainly wont be the ones to change them.
{kind=link}