
As the world is getting more tech savvy and advancements made in the information technology especially in the healthcare industry has opened areas in data mining and machine learning. Within the area of data mining one technique which has gained a lot of popularity as well as skepticism among the auditors and fraud detectives is Benford’s Law or “The Law of First digit.
In the past some researchers in Canada used the Benford’s Law distribution to detect anomalies within the claims amount data for one of the healthcare organization. In this article we will understand the mechanics of this technique and will also look at its practical usage on some random claims amount data.
What is Benford’s Law?
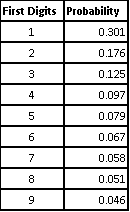
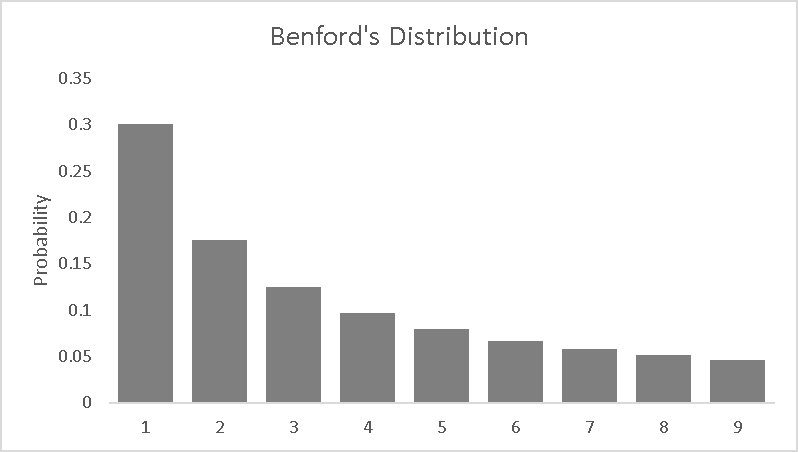
Benford’s Law is an observation about the frequency distribution of leading digits and per the Benford’s Law the digit 1 tends to occur with the probability of ~30% much greater than the expected 11.1% (1/9). This law can be observed by probing the tables of logarithms and noting that the first pages are more worn off than the last pages (Newcomb 1881). There is no question about the usability of this law in real life situations especially where finances are involved.
This phenomenon of “First Digit Law” also gained a lot of popularity and attention when it was used in television crime dramas like Numbers and Running Man Season 2.
This law can be often used with as an indicator of fraudulent data and can assist with auditing financial data. Benford’s distribution is non-uniform, with digits starting with 1 is more likely to than the larger digits like 9.
Benford’s Distribution Table
Best Data Types for Benford’s Law
- Data with values formed a mathematical combination of numbers from several distributions
- Data with wide variety of values in hundreds, thousands, etc.
- Large Data Sets
- Skewed data where mean is greater than the median
- Data with no predefined max. or min. limit
Testing the usability of this law in the real life scenario of Medicare claim submission amounts
Considering the fact that there is no specific measure of health care fraud exists, the perpetrators can cost billions of dollars to the health care programs while putting the recipient’s health and wellbeing at risk.
We will look at the applicability of this technique based on one of the Medicare abuse definition which is charging excessively for the services and supplies. In this article we will look at the sample of 1033 Medicare Claim Amount (submitted) to understand whether they are spurious in nature (if they fall under the Benford’s Law Curve or not).
Understanding the Distribution
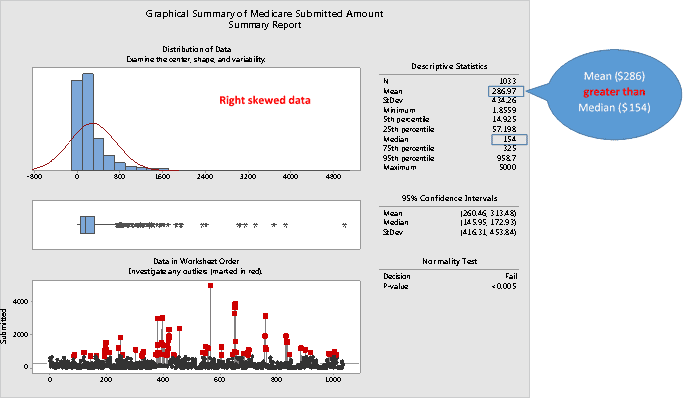
The above graphical summary conforms to the Benford’s Law data characteristics requirement.
Post establishing that this data is apt for the Benford’s Law technique. Let’s see how this technique can uncover some interesting patterns within this claims submission data set. The goal of applying Benford’s Law is to understand how “natural” these claim submissions are.
The process:
![]()
Sample the data – “The more the merrier” as this expression says the more observations the better. However, for illustration purposes I am using 1033 claims submission out of ~100K claim submission data.
![]()
Parse the leading digit – As discussed above that Benford’s Law focuses on the leading digits in sets of naturally occurring numbers. The actual claims amount, whether it is $100, $200, $300 etc. is unimportant and this can be achieved by using the Excel “Left” formula to get the lead digit for each dollar amount.
![]()
Create Frequency Distribution – The next step is to create the frequency distribution of the leading digit that have been parsed from the sample data. This can be achieved by either using the “count if” formula or by using the pivot function within MS Excel.
Compute the Distribution – Per the Benford’s Law ~30.1% percent of lead digits should be a 1 and 9 should be the least i.e. ~5% keeping this as a standard in mind compute the actual distribution of the leading digits. Once the distribution is computed compare it with Benford’s Law distribution and identify any potential outliers. Refer to the image below to see how the end results will look like.
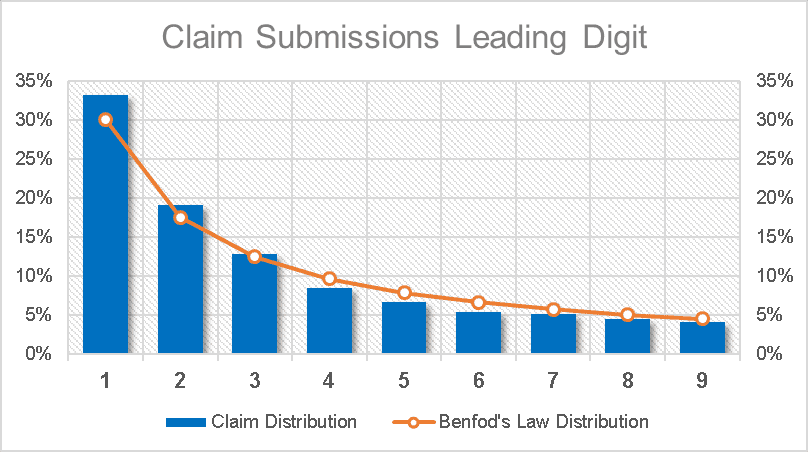
The above graphs clearly indicate that there is an unusual amount of claim submissions with leading digits 1,2 & 3. This clearly highlights a potential manipulation, error or even a fraud. Auditors can further apply tests like Chi Square test which acts as a “goodness of fit” statistic that measures how well the data distribution complies with the hypothetical distribution explained in the theory. Outputs such as 90% indicates a good fit whereas small percentages such as 3% indicates a poor fit.
Most business data, such as count of sales, costs, accounts receivables, payments, and even the buyer’s street addresses, can be considered as logical or naturally occurring numbers. By connecting the first-digit frequency distribution of naturally occurring data with Benford’s probability curve, auditors can easily spot possible data flaws or fraudulent transactions. Hence, when used appropriately, Benford’s law can be a valuable and low-costing tool for identifying spurious transactions for advance analysis.
%20to%20Debunk%20the%20Fraudsters){kind=link}