

The original intent of this post was to take a real-life project with GraphQL and to see the performance of gRPC against HTTP. Instead, we ended up using the awesome GraphCool framework, so this post will be more of an experiment trying to emulate real-life conditions, and who knows there will be more projects so part III may be a real-life project.
Since we medium readers are busy people I’ll present the results first and explain the benchmark last.
It would seem that when you got a GraphQL query that aggregates data from different sources gRPC really shines, but when you sizable data from a single source, HTTP is a bit faster.
This benchmark faces three GraphQL queries to aggregate their data. One uses gRPC, another one uses classic HTTP and the third one uses HTTP compression.
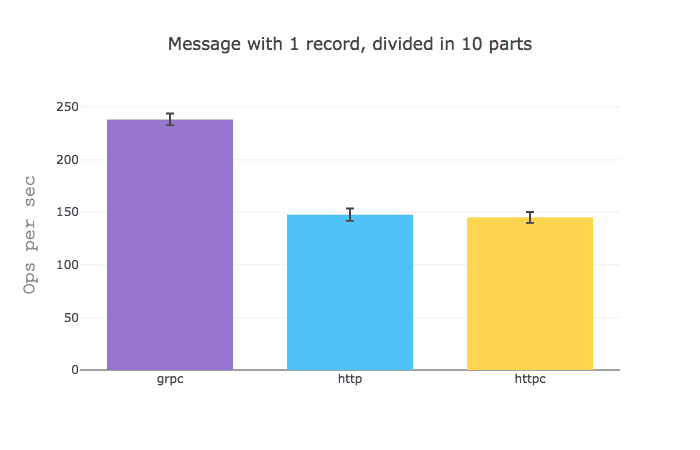
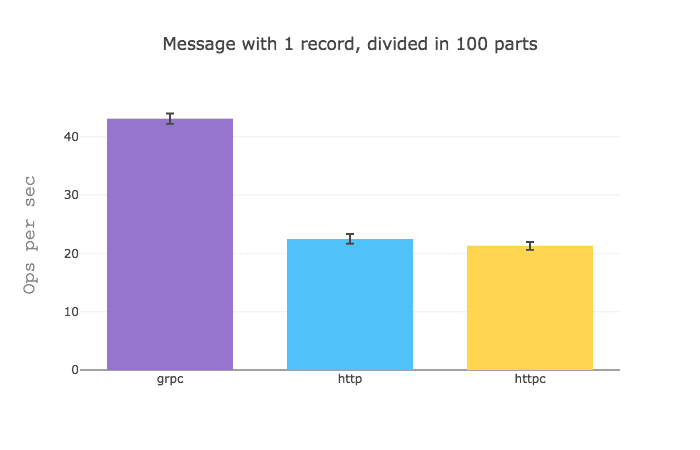
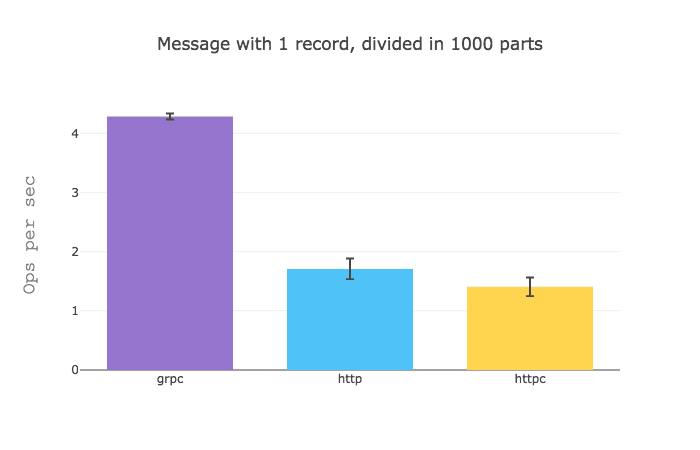
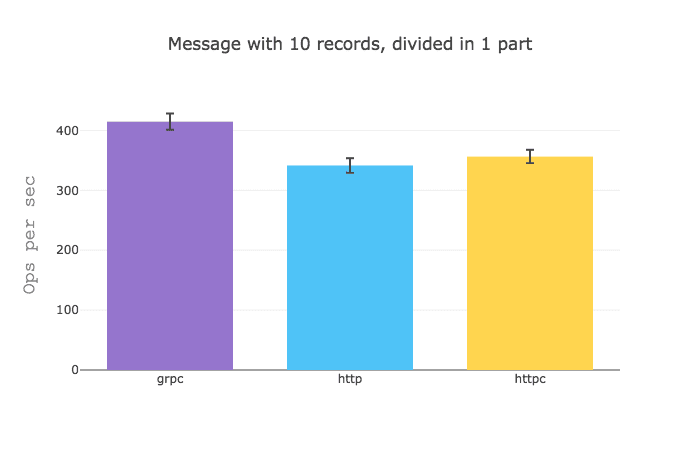
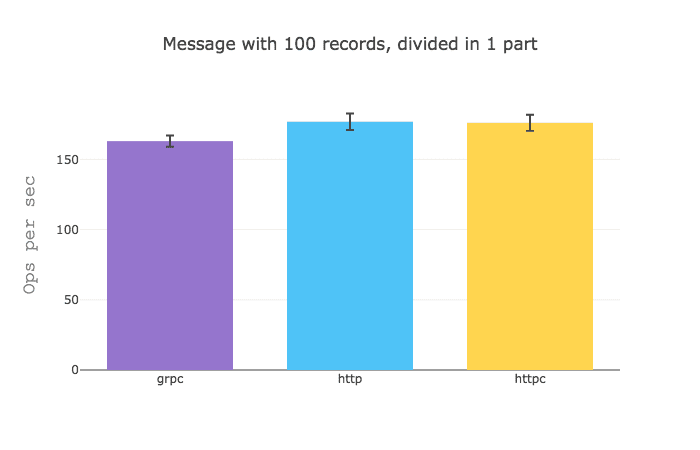
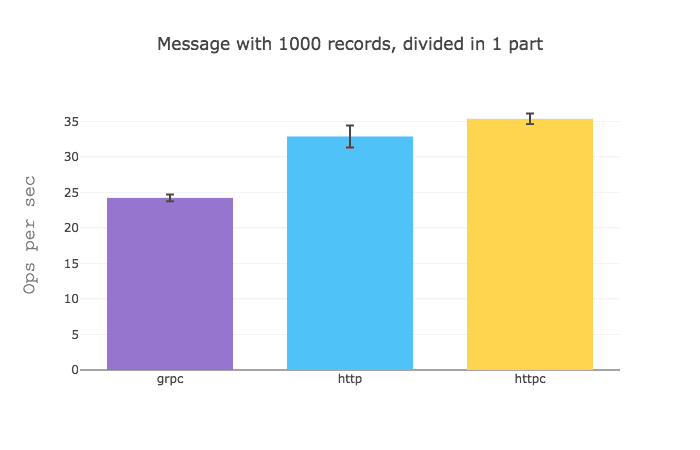
I would assume that these results are due to the fact that the overhead of establishing an HTTP request is quite greater than that of a gRPC request.
If you made it this far, I assume you want to know how the benchmark was structured. The code is in this repo.

Benchmark architecture
The benchmark consisted of two separate EC2 machines containing the GraphQL client and another containing the three gRPC and HTTP servers. The tests did not take place simultaneously in order to avoid biasing any results.
){kind=link}