
Convolutional neural network – In this article, we will explore our intuitive explanation of convolutional neural networks (CNNs) on high level. CNN are inspired by the structure of the brain but our focus will not be on neural science in here as we do not specialise in any biological aspect. We are going artificial in this post.
Convolutional Neural Networks are a special kind of multi-layer neural networks.
What are Convolutional Neural Networks
Convolutional neural networks (CNN) – Might look or appears like magic to many but in reality, its just a simple science and mathematics only. CNN’s are a category of Neural Networks that have proven very effective in areas of image recognition, processing and classification.
As per Wiki – In machine learning, a convolutional neural network (CNN, or ConvNet) is a class of deep, feed-forward artificial neural networks, most commonly applied to analysing visual imagery.
Artificial Intelligence solutions behind CNNs amazingly transforming how businesses and developers create user experiences and solve real-world problems. CNNs are also known as application of neuroscience to machine learning. It employe mathematical operations known as “Convolution”; which is a specialised kind of linear operation. For processing of data in CNN have grid topology for data i.e
- 1D Grid – Time series data – Takes samples at regular time intervals
- 2D Grid – Image data – Grid of pixels
In CNN’s data points is are called as grid-like topology as processing of data happens in a spatial correlation between the neighbourhood data points. This neural networks uses convolution method as oppose to general matrix multiplication in at least one of layers. Convolution leverages on
- Equivariant Representations – This simply means that if the input changes, the output changes in the same way
- Sparse Interactions – This allows the network to efficiently describe complicated interactions between many variables from simple building blocks.
- Parameter sharing – Using the same parameter for more than one function in a model
The above structure is created to improve a machine learning system. CNN’s also allows for working with inputs of variable size and efficiently describe complicated interactions between many variables from simple building blocks.
Some history around – Convolutional Neural Networks (CNNs)
ConvNets have been successful in identifying faces, objects and traffic signs apart from powering vision in robots and self driving cars. Yann LeCun was named LeNet5 after many previous successful iterations since the year 1988. LeNet was one of the very first convolutional neural networks which has pushed forward Deep Learning.

In 2012, Alex Krizhevsky used Convolutional neural network in ImageNet competition and ever since then all big companies are running for this. CNNs are the most influential innovations in computer vision field. in 1990’s LeNet architecture was used mainly for character recognition tasks such as reading zip codes, digits, etc.
Image Processing – Human vs Computers
For humans recognition of objects is the first skills we learn right from birth. New born baby starts recognising faces as Papa, Mumma etc. By the time turn to an adult; recognition becomes effortless and kind of automated process.
Human behaviour for processing image is very different from machines. Humans give label to to each image automatically by just looking around and immediately characterise the scene and give each object a label without even consciously noticing.
For computers recognising objects is slightly complex as to them every thing it sees through becomes input and output comes as class or set of classes. This is known as image processing which we will discuss in next section in details. In computers CNNs does images recognition, images classifications. It is very useful in objects detections, face recognition and also successful in various text classification with word embedding tasks etc.

So in simple words computer vision is the ability to automatically understand any image or video based on visual elements and patterns.
Inputs and Outputs – How it works
Our focus in this post will be on image processing only
In CNNs it requires to models to train and test. Each input image pass through a series of convolution layers with filters (Kernals), Pooling, fully connected layers (FC) and apply softmax function (Generalisation of the logistic function that “squashes” a K-dimensional vector of arbitrary real values to real values Kd vector) to classify an object with probabilistic values between 0 and 1. This is the reason every image in CCN gets represented as a matrix of pixel values.
The Convolutional Neural Network classifies an input image into categories e.g dog, cat, deer, lion or bird.
the Convolution + Pooling layers act as feature extractors from the input image while fully connected layer acts as a classifier. In above image figure, on receiving a dear image as input, the network correctly assigns the highest probability for it (0.94) among all four categories. The sum of all probabilities in the output layer should be one though. There are four main operations in the ConvNet shown in image above:
- Convolution
- Non Linearity (ReLU)
- Pooling or Sub Sampling
- Classification (Fully Connected Layer)
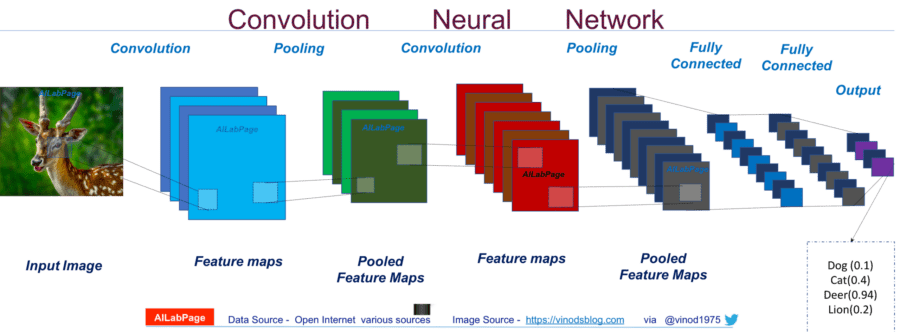
These operations are the basic building blocks of every Convolutional Neural Network, so understanding how these work is an important step to developing a sound understanding of ConvNets or CNNs.
Convolutional Neural Networks – Architecture
Layers used to build Convolutional Neural NetworksAs we have mentioned in above picture. Simple ConvNet is a sequence of layers, and every layer of a ConvNet transforms one volume of activations to another through a differentiable function. We use four main types of layers to build our ConvNet architectures above: Convolutional Layer, ReLU, Pooling, and Fully-Connected Layer.
Initialization
Initialization of all filters and parameters / weights with random values
Input Image & Convolution Layer
This holds raw pixel values of the training image as input. In example above an image (deer) of width 32, height 32, and with three colour channels R,G,B is used. It goes through the forward propagation step and finds the output probabilities for each class. This layer ensures spatial relationship between pixels by learning image features using small squares of input data.
- Lets assume the output probabilities for image above are [0.2, 0.1, 0.3, 0.4]
- The size of the feature map is controlled by three parameters.
- Depth – Number of filters used for the convolution operation.
- Stride – Number of pixels by which filter matrix over the input matrix.
- padding – Its good to input matrix with zeros around the border, matrix.
- Calculating total error at the output layer with summation over all 4 classes.
- Total Error = ∑ ½ (target probability – output probability) ²
- Computation of output of neurons that are connected to local regions in the input. This may result in volume such as [32x32x16] for 16 filters.
Rectified Linear Unit (ReLU) Layer
A non-linear operation. This layer apply an element wise activation function. ReLU is used after every Convolution operation. It is applied per pixel and replaces all negative pixel values in the feature map by zero. This leaves the size of the volume unchanged ([32x32x16]). ReLU is a non-linear operation.
Pooling Layer
Read full article here.
{kind=link}