
A podcast with Weimo Liu and Sam Magnus of PuppyGraph

Open source Apache Iceberg, Hudi and Delta Lake have made it possible to dispense with the complexities and duplication of data warehousing. Instead of requiring time-consuming extract, transform and load (ETL) procedures, these large table formats make it simple to tap S3 and other repositories directly for analytics purposes.
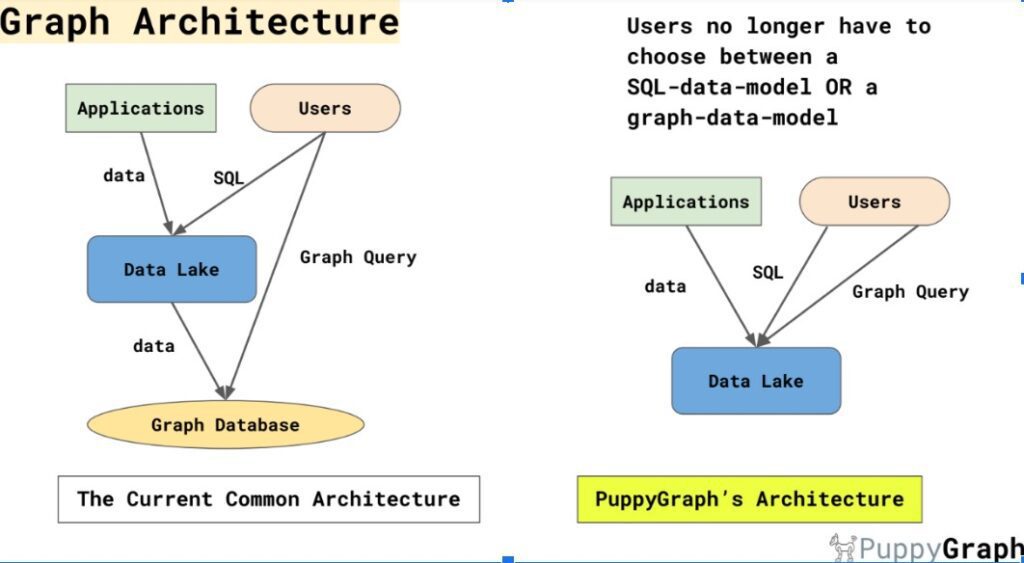
PuppyGraph takes this modern data lake capability a step further, making it possible to create and query graphs on top of one of these large analytic table formats. After creating a subgraph with a SQL group by statement, for example, a user can do graph traversal via Gremlin or declarative graph querying using Cypher via these tables, or use a prompt interface on the data via LlamaIndex. Here’s how the PuppyGraph architecture eliminates the need for a graph database.
With a single logical schema, you can tap multiple heterogeneous repositories such as one that’s MySQL and an S3 bucket both via an Iceberg-enabled table, says PuppyGraph CEO Weimo Liu.
Let’s say a user has a table with transaction records. The sender, receiver and amount fields already suggest a graph of sorts. The user can just use SQL and a “group by” query to create a subgraph of selected records, then create a logical schema and do graph queries. That’s how you can leverage both SQL and graph querying with a tool such as Gremlin in the same use case.
With a SQL query engine side by side with a graph engine, users can feed the retrieved outputs into machine learning algorithms and reporting tools, says PuppyGraph founding member Sam Magnus.
A video Weimo posted on YouTube called “PuppyGraph – Query the Data in Your Data Lake as a Graph in One Minute” walks users through how to create a simple schema to query their data via a modern data lake enabled by Iceberg as a graph by following these steps (paraphrased here):
- Create a schema JSON file to tell PuppyGraph these specifics:
- The URL of your data lake
- Which tables are nodes
- Which tables are edges.
- Post the file to the server. The server will confirm the schema creation.
- Connect the console of a graph query tool such as Gremlin or Cypher to the server
- Run your query to retrieve the results.
Note that PuppyGraph is not a database, but a graph analytics engine designed to work with all the seemingly limitless information modern data lakes can store.
“Single copy” analytics is a phrase Sam Magnus uses to underscore that multiple data analystics users can all use the same copy of the data to support both SQL and graph workloads, rather than having to copy over and over again.
By using PuppyGraph, Sam estimates that consultants hired for graph analytics projects can be up and running within an hour at client sites, assuming the necessary data is accessible. That’s a big deal, considering that graph database proofs of concept (PoCs) have historically required extensive up-front work to begin delivering results.
Sam and Weimo encourage everyone to try out PuppyGraph–they’ve got a free Docker in the user manual and haven’t been charging for consulting. Hope you enjoy the podcast.
{kind=link}