

Instead of focusing on Automated Machine Learning or AutoML, maybe we should focus on Automated Data Management or AutoDM?
You probably know that feeling. You start a blog with some ideas to share, but everything changes once you get started. That’s what happened with this blog. I discussed the promise and potential of Automated Machine Learning (AutoML) in my blog “What Movies Can Teach Us About Prospering in an AI World“. It seems quite impressive.
So, I decided to conduct a LinkedIn poll to garner insights from real-world practitioners, folks who can see through the hype and BS (and that’s not Bill Schmarzo…or maybe it should be) about the potential ramifications of AutoML. It was those conversations that lead to my epiphany. But before I dive into my epiphany, let’s provide more on AutoML.
What is AutoML?
Automated machine learning (AutoML) automates applying machine learning to real-world problems. AutoML covers the complete pipeline from the raw data to the deployable machine learning model. The high degree of automation in AutoML allows non-experts to create ML models without being experts in machine learning. AutoML offers the advantages of producing simpler solutions, faster creation of those solutions, and models that often outperform hand-designed models.[1] See Figure 1.
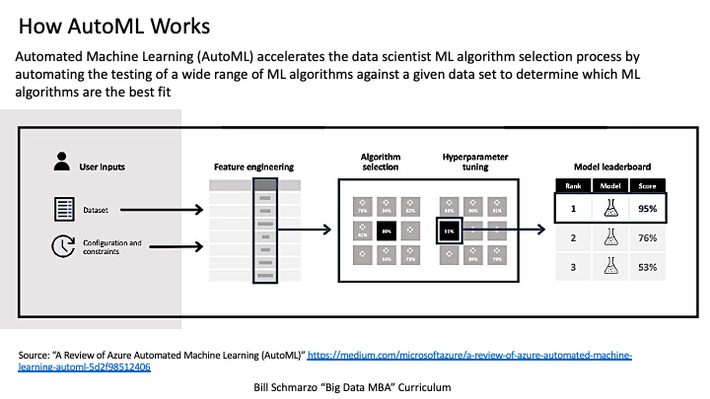
Figure 1: Image sourced from: “A Review of Azure Automated Machine Learning (AutoML)”
Man, that is quite a promise. But here’s the AutoML gotcha: to make AutoML work, data experts need to perform significant data management work before getting into the algorithm selection and hyperparameter optimization benefits of AutoML. This includes:
- Data Pre-processing which includes data cleansing (detecting and correcting corrupt or inaccurate records), data editing (detecting and handling errors in the data), and data reduction (elimination of redundant data elements).
- Data wrangling which transforms and maps data from one “raw” data format into a format that is usable by the AI/ML models.
- Feature Engineering which is the process of leveraging domain knowledge to identify and extract features (characteristics, properties, attributes) from raw data that are applicable to the problem being addressed.
- Feature Extraction involves reducing the number of features or variables required to describe a large set of data. This likely requires domain knowledge to identify those features most relevant to the problem being addressed.
- Feature Selection is the process of selecting a subset of relevant features (data variables) for use in model construction. Again, this likely requires domain knowledge to identify those features most relevant to the problem being addressed.
That’s a lot of work to do before even getting into the AutoML space. But us old data dogs already knew that 80% of the analytics work was in data preparation. It’s just that today’s AI/ML generation needs to hear that, and who better to deliver that message than one of the industry’s AI/ML spiritual leaders – Andrew Ng.
Andrew Ng: Become More Data-Focused and Less Algorithm-Focused
Here is a must watch video from by Andrew titled :Big Data to Good Data: Andrew Ng Urges ML Community to Be More Data…”. There are lots of great insights in the video, but what struck me was Andrew’s own epiphany on the critical importance of spending less time tweaking the AI/ML models (algorithms) and investing more time on improving the data quality and completeness that feeds the AI/ML models. Andrew’s message is quite clear: while tweaking the AI/ML algorithms will help, bigger improvements in overall AI/ML model performance and accuracy can be achieved by quality and completeness improvements in the data that feed the AI/ML algorithms (see Figure 2).

Figure 2: Transitioning from Algorithm-centric to Data-centric AI/ML Model Development
And note that those improvements in data quality and completeness that feeds the AI/ML models will benefit all AI/ML models that use that same data! Sounds a lot like the Schmarzo Economic Digital Asset Valuation Theorem – the economic theorem on sharing, reusing, and refining of the organization’s data and analytic assets.
In the video, Andrew shared hard data with respect to improvement in results from tweaking the model (algorithm) versus improving data quality and completeness (see Figure 3).
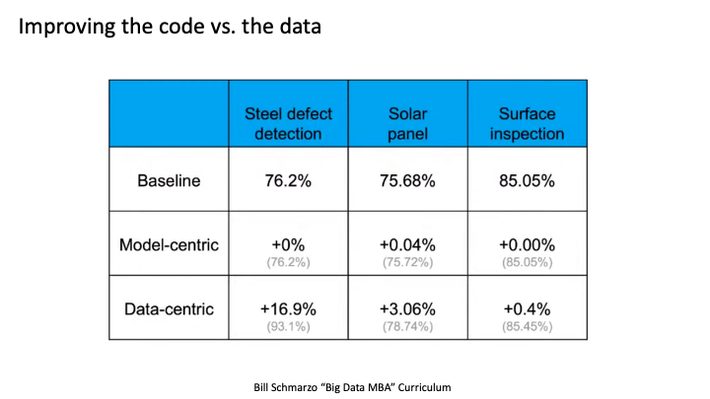
Figure 3: Improving the Code versus Improving the Data
In the three use cases in Figure 4, there was literally no improvement in AI/ML model accuracy and effectiveness from tweaking the AI/ML models. However, efforts applied against improving the data yielded quantifiable improvements, and in one case, very significant improvements!
LinkedIn Poll: What Is True About AutoML?
Figure 4 shows the LinkedIn poll results where I asked participants to select the option they felt was most true about AutoML (sorry, only 4 options are available on LinkedIn).
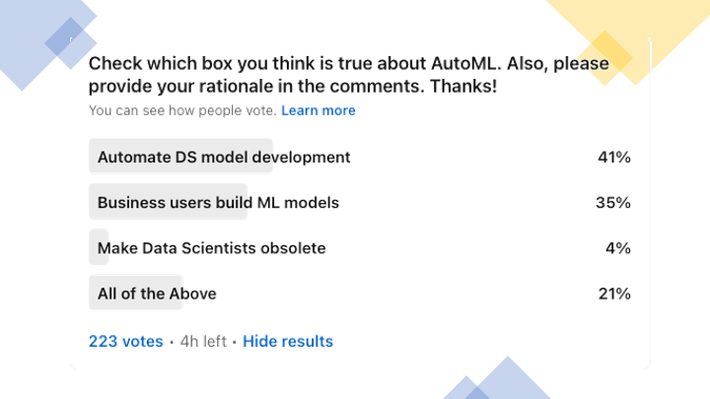
Figure 4: LinkedIn AutoML Poll
If we factor the “All of the Above” choice with the top two choices, we get the following results:
- 62% of respondents feel AutoML will help automate data science model development
- 56% of respondents feel AutoML will enable business users to build their own ML models
Unfortunately, not having a “None of the Above” option was unfair because the results of the poll differ from poll comments. Here is my summary of those comments:
- AutoML will not be replacing data scientists anytime soon. However, AutoML can help jumpstart the Data Science process in ML model exploration, model selection, and hyperparameter tuning.
- AutoML will not suddenly turn business analysts into data scientists. That’s because ~80% of the ML model development effort is still focused on data preparation. To quote one person, “AutoML by untrained users would be like giving an elite athlete training plan and diet to average people and expecting elite results.”
- AutoML will be even more lacking as Data Scientist’s data preparation work evolves to semi-structured (log files) and unstructured data (text, images, audio, video, smell, waves).
- Realizing the AutoML promise will require a strong metadata strategy and plan.
- AutoML could help in AI/ML product management as the number of production ML models grows into the hundreds and thousands. But AutoML would need an automated set-up to monitor and correct for ML data drift while in production.
- Automating the ML process is just a small step. AutoML results need to be explainable to help in the evaluation of the analytic results using techniques such as SHAP or CDD.
- AutoML is a commodification of the loops and utilities that ML folks run through various ML algorithms, tune hyper-parameters, create features, and calculate metrics of all kinds.
- AutoML can be a great tool to get align teams around an organization’s ML aspirations. A field only flourishes when everyone from every discipline can use it to try different ideas.
- For AutoML to be successful, it is critical important to scope, validate, and plan the operationalization of the problem that one is trying to solve (e.g., Is the target variable here *really* what you want to model? Are all of the inputs available in a production environment? What decisions will this model support? How will you monitor the ongoing accuracy and usage of the model? How will you govern changes to the model, including commissioning and decommissioning it?). Hint, see Hypothesis Development Canvas?
- Finally, is AutoML a marketing ploy by cloud vendors to broaden their appeal to include enabling business users to build their own ML models?
I suggest that you check out the chat stream. The comments were very enlightening.
AutoML or AutoDM Summary
My takeaway is that the concept of AutoML is good, but scope of the AutoML vision is missing 80% of the AI/ML model development and operationalization, providing high quality and complete data that feeds the AI/ML models. Figure 5 from “Big Data to Good Data: Andrew Ng Urges ML Community to Be More Data…” nicely summarizes the broader AutoML challenge with respect to data management.
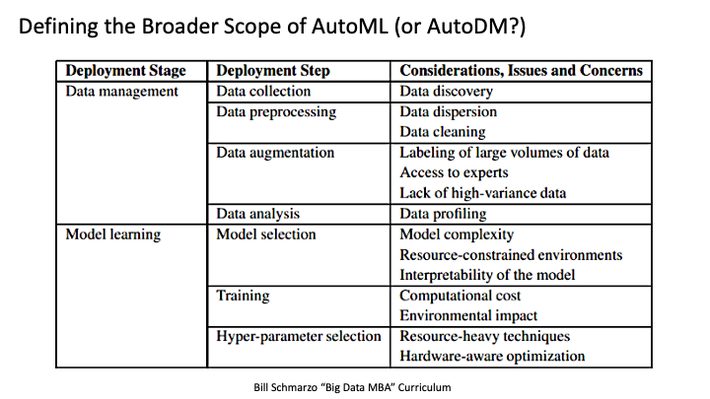
Figure 5: Scope of What AutoML Needs to Address
Instead of focusing on Automated Machine Learning or AutoML, maybe we should focus on Automated Data Management or AutoDM?
Now that’s a thought…
[1] Wikipedia, AutoML https://en.wikipedia.org/wiki/Automated_machine_learning
?){kind=link}