
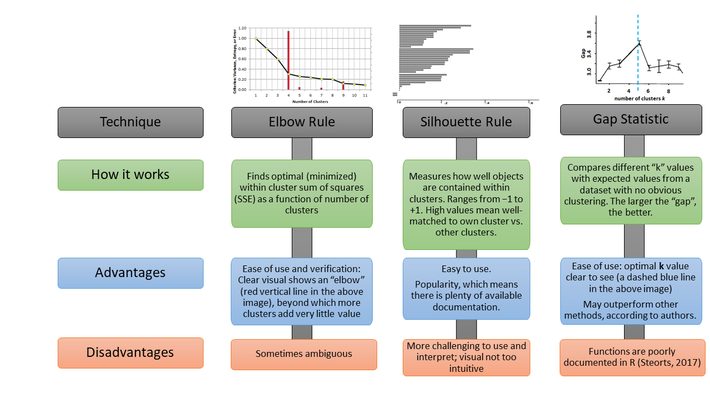
If you want to determine the optimal number of clusters in your analysis, you’re faced with an overwhelming number of (mostly subjective) choices. Note that there’s no “best” method, no “correct” k, and there isn’t even a consensus as to the definition of what a “cluster” is. With that said, this picture focuses on three popular methods that should fit almost every need: Silhouette, Elbow, and Gap Statistic.
Click on the picture to zoom in
For other machine learning concepts explained in one picture, see here. For other tutorials on clustering, follow this link.
References
- How to choose the number of clusters K?
- How to determine the number of clusters in your data
- Estimating the number of clusters in a data set via the gap statistic.
- Kassambara, A. (2017)Practical Guide to Cluster Analysis in R: Unsupervised Machine Learning. STHDA.
{kind=link}