
“Autonomous vehicle” is a buzzword that’s been circulating in recent decades. However, the development of such a vehicle has posed a significant challenge for automotive manufacturers. This article describes how deep learning autonomous driving and navigation can help to turn the concept into a long-awaited reality.
The low-touch economy in a post-pandemic world is driving the introduction of autonomous technologies that can satisfy our need for contactless interactions. Whether it’s self-driving vehicles delivering groceries or medicines or robo-taxis driving us to our desired destinations, there’s never been a bigger demand for autonomy.
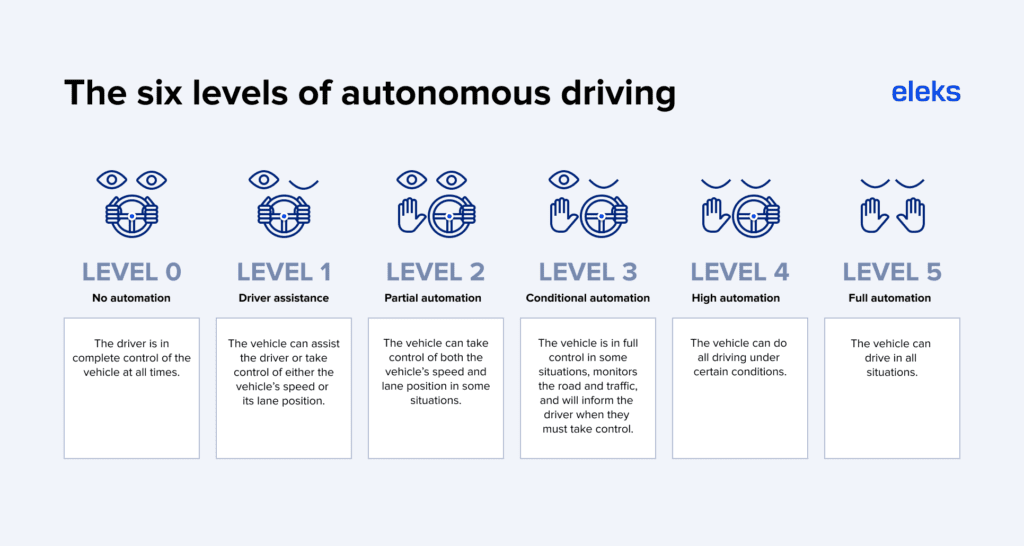
Self-driving vehicles have six different levels of autonomy, from drivers being in full control to full automation. According to Statista, the market for autonomous vehicles in levels 4 and 5 will reach $60 billion by 2030. The same research indicates that 73% of the total number of cars on our roads will have at least some level of autonomy before fully autonomous vehicles are introduced.
Countries and automobile companies around the world are working on bringing a higher level of unmanned driving to a wider audience. South Korea has recently announced it is to invest around $1 billion in autonomous vehicle technologies and introduce a level 4 car by 2027.
Machine learning and deep learning are among other technologies that enable more sophisticated autonomous vehicles. Applications of deep learning techniques in self-driving cars include:
- Scene classification
- Path planning
- Scene understanding
- Lane and traffic sign recognition
- Obstacle and pedestrian detection
- Motion control
Deep learning for autonomous navigation
Deep learning methods can help to address the challenges of perception and navigation in autonomous vehicle manufacturing. When a driver navigates between two locations, they drive using their knowledge of the road, how streets look like and traffic lights, etc. It is a simple task for a human driver, but quite a challenge for an autonomous vehicle.
Here at ELEKS, we’ve created a demo model that can help vehicles to navigate the environment as humans already do using eyesight and previous knowledge. We came up with a solution that offers autonomous navigation without GPS and vehicle telemetry by using modern deep learning methods and other data science possibilities.
We used only an on-dash camera and street view dataset of the city of Lviv, Ukraine; we used no GPS or sensors. Below is an overview of the techniques applied and our key findings.
1. Image segmentation task
We used a Cityscapes dataset with 19 classes, which focuses on buildings, road, signs, etc., and an already trained model from DeepLab. The model we used is based on Xception inference. Other models with different maps/IoUs are also available.
Final layers were the semantic probabilities mostly dim ~ classes*output_image_dims (without channels), so they could be filtered and become the inference to similarity model. It is recommended to transform them into the embedding layer or find a more suitable layer before the outputs. However, even after transformation objects position (higher or lower) on the frame and distance to it, may have influenced the embedding robustness.

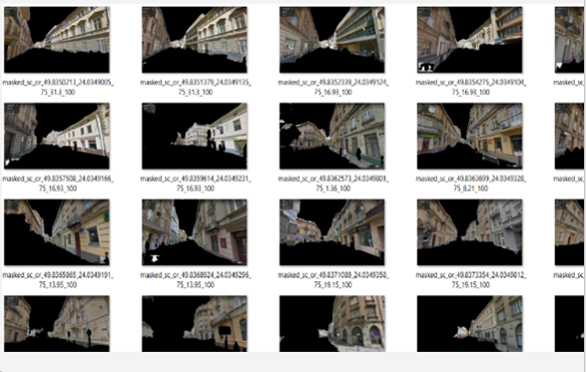
2. Gathering additional data and labelling
We then downloaded raw photos from the web of the streets, road names and locations (coordinates, etc.), and we also got the Street View API key for download. We added labels in semi-automated ways based on the names and locations and verified them manually. We created pairs of images for similarity model training.
Finally, we used the image augmentation (also adding photos of different times of day and seasons) and image labelling using model (for example, additional negative samples, which the model recognizes as similar, but they are not located on the one street (GPS, street names, etc.)). As a result, we created a dataset containing approximately 8-12K augmented images.

3. Similarity models ideation and validation
We tested a few streets view comparison approaches from classical descriptor and template matching to modern SOTA DL algorithms like QATM. The most accurate was the inference model with representation for each segmented image in a pair, like VGG, ResNet or efficientNet and binary classifier (xgb or rf). Validated accuracy equals to approximately 82.5% (whether the right street was found or not), taking into account Lvivs most known streets between 2011 and 2019 and with augmentation (changing image shapes, lightning, etc).



4. Outcome and performance features
We segmented every tenth frame, which was helpful for near real-time calculation, and because there would not be any huge changes in the environment in the space of 10 frames (1/3 s). Then, DeepLab models have shown >70 mIoU (Cityscapes, third semantic mat buildings), time for prediction CPU 15s-more than 10m based on Xception, GPU ~ <1s.
The similarity prediction was equal to 1min per 100 pairs (inference on GPU (4Gb VRAM) + classifier on 6 CPU cores). It can be optimised, after the first estimated positions, by limiting search only to closer street views, because the vehicle cant appear more than 1 km in 10-50 frames.
Not all of the citys streets were covered, so we found videos with a drive around the city centre. For the map positioning, we used wiki maps; however, other maps can be used if needed. We got the vehicle coordinates from street image metadata (lat/long, street name).
Some streets segments are available in a few different versions the same location in 2011, 2015 or 2019 and photos from different sources, etc., so the classifier can find any of them. We used mostly weak affine transformations for the streets augmentation with no flipping or strong colour and shape changes.
Some of the estimations may be inaccurate for the following reasons:
- Street and road estimation the static object area is low, street noise is quite high (vehicles, pedestrians) or seasonality changes (trees, snow, rain, etc.)
- Vehicle position and speed errors the same street position and different street step or Euclidean distance for curved streets can be viewed with a different focus (distance to an object), etc.
You can check out a video sample of prerecorded navigation with post-processing here.
Want to learn more about our demo? We will be happy to answer your questions!
Originally published at ELEKS Labs blog.
{kind=link}