
What data scientists do?
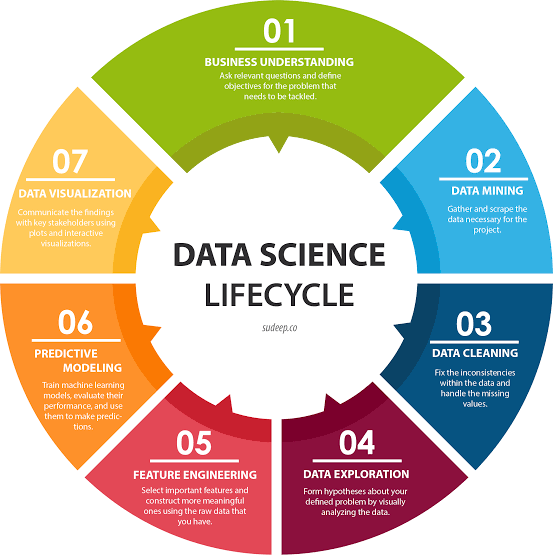
As per my personal perception, i do break data science down into three components:
(1) business intelligence, which is essentially about “taking data that the company has and getting it in front of the right people” in the form of dashboards, reports, and emails;
(2) decision science, which is about “taking data and using it to help a company make a decision”;
(3) machine learning, which is about “how can we take data science models and put them continuously into production.”
We now know how data science works, at least in the tech industry. First, data scientists lay a solid data foundation in order to perform robust analytics. Then they use online experiments, among other methods, to achieve sustainable growth. Finally, they build machine learning pipelines and personalized data products to better understand their business and customers and to make better decisions. In other words, in tech, data science is about infrastructure, testing, machine learning for decision making, and data products.
Nearly all of my friends understand that working data scientists make their daily bread and butter through data collection and data cleaning; building dashboards and reports; data visualization; statistical inference; communicating results to key stakeholders; and convincing decision makers of their results.
As we’re seeing rapid developments in both the open-source ecosystem of tools available to do data science and in the commercial, productized data-science tools, we’re also seeing increasing automation of a lot of data-science drudgery, such as data cleaning and data preparation. It has been a common trope that most of a data scientist’s valuable time is spent simply finding, cleaning, and organizing data, leaving only less to actually perform analysis.
Ethics is among the field’s biggest challenge for the data scientist.
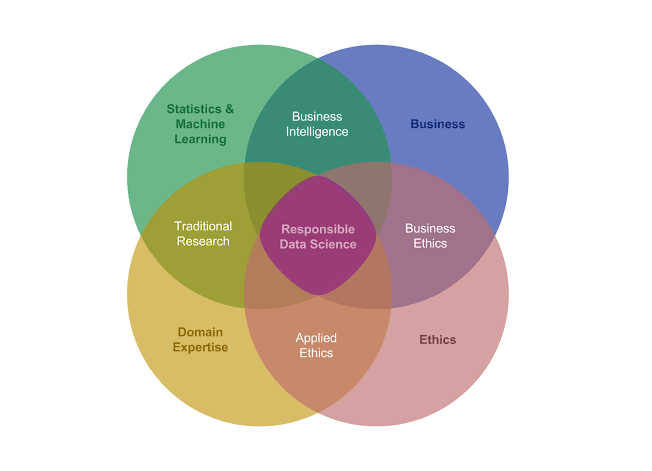
I think that imprecise ethics, no standards of practice, and a lack of consistent vocabulary are enough challenges for data scientist today.
We need to have that ethical understanding, we need to have that training, and we need to have something akin to a Hippocratic oath. And we need to actually have proper licenses so that if you actually do something unethical, perhaps you have some kind of penalty, or disbarment, or some kind of recourse, something to say this is not what we want to do as an industry, and then figure out ways to remediate people who go off the rails and do things because people just aren’t trained and they don’t know.
We’re approaching a consensus that ethical standards need to come from within data science itself, as well as from legislators, grassroots movements, and other stakeholders. Part of this movement involves a reemphasis on interpretability in models, as opposed to black-box models. That is, we need to build models that can explain why they make the predictions they make. Deep learning models are great at a lot of things, but they are infamously uninterpretable.
Many dedicated, intelligent researchers, developers, and data scientists are making headway here with work such as Lime, a project aimed at explaining what machine learning models are doing.
Please share your opinion also……
{kind=link}