
What do we need to do to increase the data literacy of our organization?
In a world where your personal data, and the preferences and biases buried in that data, are being used to influence your behaviors, beliefs, and decisions, data literacy becomes a fundamental skill. And it’s not just corporations that need this training. Data Literacy should be taught in universities, in high schools, in middle schools and even in adult education and nursing homes.
In the first blog of this two-part series on the Data Literacy Education Framework, I introduced the 4 stages of the Data Literacy Educational Framework, a framework which organizations, universities, high schools, and even adult education programs can use to create a more holistic data literacy training. In that blog, I discussed the first two stages of the Data Literacy Educational Framework (Figure 1):
- Data Awareness which talked about how everyone needs to be aware how their personal data is being captured and used to influence or manipulate how we think and the decisions that we make.
- Decision Literacy which discussed how humans make models of various complexity to make more informed and accurate decisions.
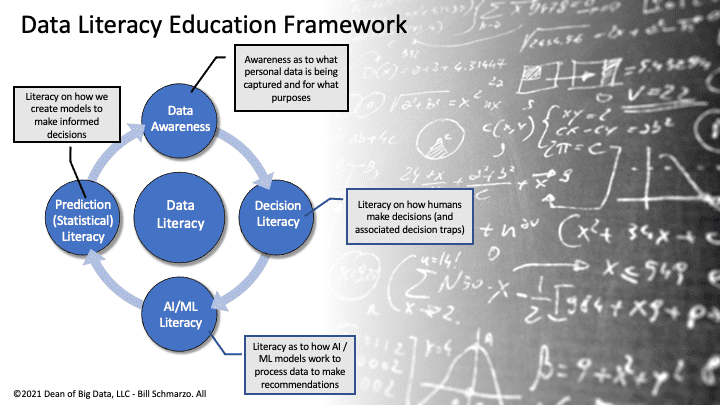
Figure 1: Data Literacy Education Framework
Now, I want to complete the Data Literacy Education Framework by discussing the third (AI / ML Literacy) and fourth stages (Prediction and Statistical Literacy) of the Data Literacy Education Framework.
Subject Area #3: AI / ML Literacy
My blog “The Growing Importance of Data and AI Literacy – Part 2” broadened the data literacy conversation by introducing AI (Artificial Intelligence) and ML (Machine Learning) Literacy; that is, an introduction into how AI and ML models work.
AI/ML Literacy is understanding how AI/ML models work as they seek to optimize the KPI’s and metrics that comprise the AI/ML Utility Function (and around which the AI/ML model measures decision effectiveness) as it continuously learns and adapts from the interactions with its environment.
An AI model seeks to optimize its AI Utility Function – the KPIs and metrics against which the AI model’s progress and success will be measured – as the AI model interacts with its environment. The AI Utility Function provides positive and negative feedback to the AI model (using stochastic gradient descent and backpropagation) so that the AI model can continuously learn and adapt its operations in search for making the “right” or “optimal” decisions or actions (Figure 2).
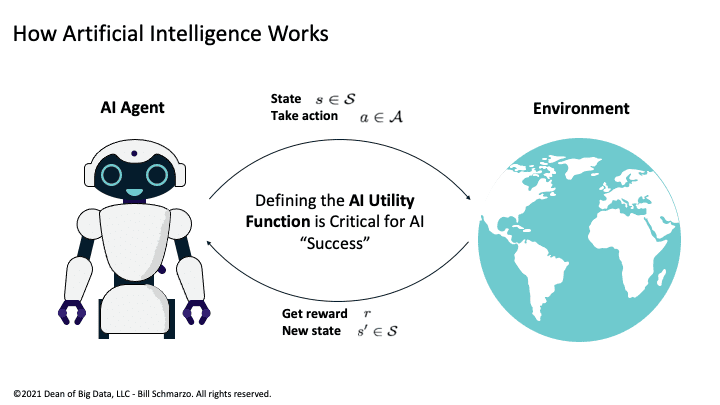
Figure 2: How Artificial Intelligence (AI) Works
The AI model is trained and learns through the following process:
- The AI Engineer (in very close collaboration with the business stakeholders) defines the AI Utility Function – the KPIs and metrics against which the AI model’s progress and success will be measured.
- The AI model operates and interacts within its environment using the AI Utility Function to gather feedback in order to continuously learn and adapt its operations (using backpropagation and stochastic gradient descent to constantly tweak the models weights and biases).
- The AI model seeks to make the “right” or “optimal” decisions, as framed by the AI Utility Function, as the AI model interacts with its environment.
The AI model seeks to maximize “rewards” based upon the definitions of “value” as articulated in the AI Utility Function (Figure 3).
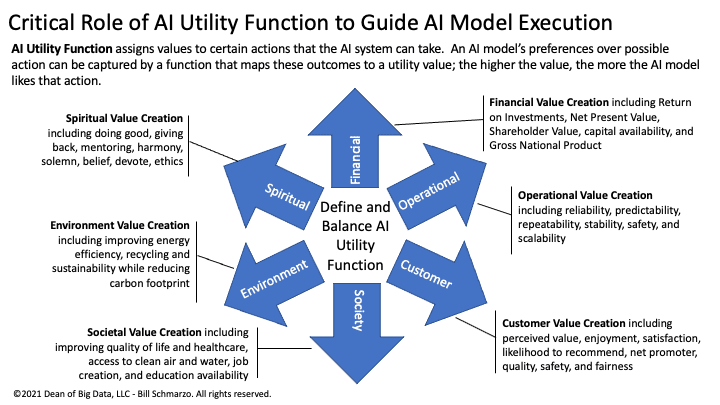
Figure 3: The AI Utility Function
The AI Utility Function assigns values to certain actions that the AI system can take. An AI model’s preferences over possible action can be captured by a function that maps these outcomes to a utility value; the higher the value, the more the AI model likes that action. Defining the AI Utility Function is critical to AI model operational effectiveness and relevance because AI systems are basically dumb systems that will continuously seek to optimize around the variables and metrics that are defined in the AI Utility Function.
Subject Area #4: Prediction (and Statistical) Literacy
A prediction is a statement about the likelihood of a future event.
Predictions are natural, everyday occurrences. We watch the news for predictions about tomorrow’s weather. We use GPS apps for predictions about how long it’ll take to drive to the movie theater. We read columns from sports experts who provide predictions about whether your favorite sports team will win. And in each of these situations, a human or machine “expert” is blending the patterns, trends, and relationships buried in the historical data with current operational, environmental, financial, and societal data to make that prediction.
Prediction Literacy is understanding how we leverage patterns, trends, and relationships to try to make predictions about what is likely to happen so that we can make more accurate decisions.
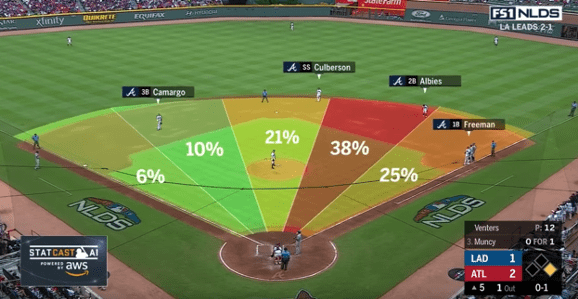
We inherently know that how people or devices performed in the past is a highly predictive to how these humans and devices will perform in the future. Look no further than the infield shift in baseball, where baseball coaches position their infielders to infield locations where the batter is predicted to most likely to hit the baseball (Figure 4).
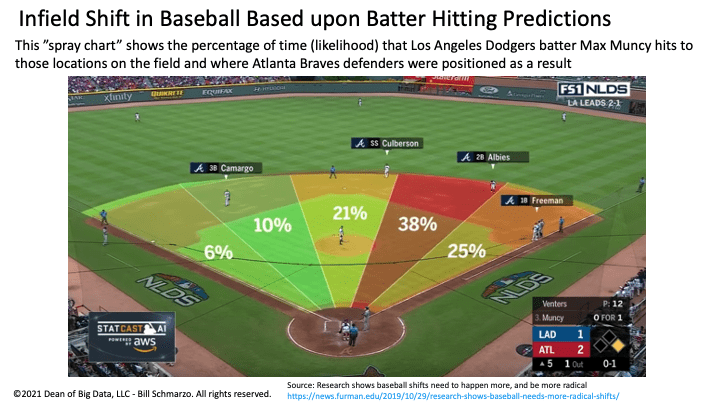
Figure 4: Infield Shift in Baseball Based upon Batter Hitting Predictions
And while the SEC warns investors that a fund’s past performance does not necessarily predict future results, we also know that well managed funds over time outperform poorly managed funds (and hopefully direct our investments accordingly and not invest in that latest, hot financial trend).
This next section will likely make folks cringe a bit, to better achieve Prediction Literacy, we are going to a quick primer on the basics of statistics. Sorry about that.
Key Statistical Concepts
Statistics is the practice or science of collecting and analyzing numerical data in large quantities, especially for the purpose of inferring proportions in a whole from those in a representative sample.
We inherently know that predictions about the future are never 100% accurate. Making predictions about what is likely to happen is based upon probabilities, confidence levels, and confidence intervals.
Probability is the likelihood (from 0% to 100%) that something is going to happen or that something is true.
For example, the probability of Barry Bonds getting a hit in his 2004 season with the San Francisco Giants was 36.2% (36.2 hits for every 100 at-bats), and his probability of getting on base when he batted that same season was 60.9% (60.9 hits or walks for every 100 at-bats…which is absolutely a stunning statistic).
Since predictions happen within a range (because predictions are not 100% certainty), we leverage variances in the data to construct those confidence intervals using confidence levels.
Variance measures the variability of the numbers or observations from the average or mean of that same set of numbers or observations
Confidence level is the percentage of times you expect to reproduce an estimate between the upper and lower bounds of the confidence interval
Confidence interval is the range of values that you expect your estimate to fall between a certain percentage of the time if you run your experiment again or re-sample the population in the same way (Figure 5).
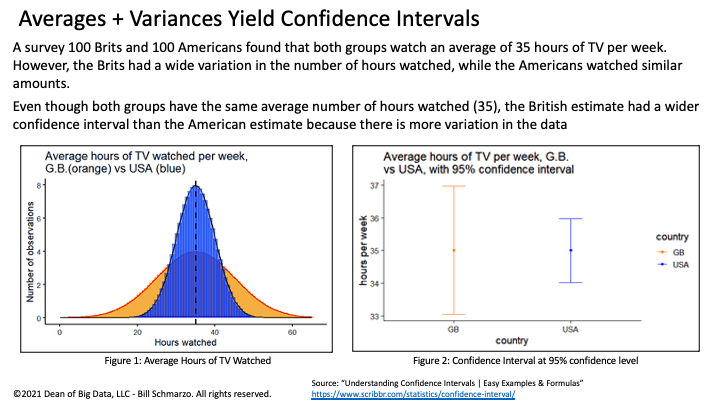
Figure 5: Averages + Variances Yield Confidence Intervals
While statistics is probably no one’s favorite topic (except both my actuarial friends), we need to understand basic statistical concepts so that we can make informed decisions in a world of incomplete and even conflicting information.
Here is a link that provides a nice overview of additional and important statistical concepts: “The 8 Basic Statistics Concepts for Data Science” by Shirley Chen.
Importance of Critical Thinking
Critical Thinking is the judicious and objective analysis, exploration and evaluation of an issue or a subject in order to form a viable and justifiable judgment.
In a day and age when data and even images can be so easily manipulated, it is important to maintain a healthy skepticism. Here are some simple critical thinking rules that can help you make more informed decisions and avoid catastrophic choices (which still doesn’t explain me being a Chicago Cubs fan). See Figure 6.
- Never accept the initial answer as the right answer. It’s too easy to take the initial result and think that it’s good enough. But good enough is usually not good enough, and one needs to invest the time and effort to explore if there is a better “good enough” answer.
- Be skeptical. Never accept someone’s “statement of fact” as “fact.” Learn to question what you read or hear. It’s very easy to accept at face value whatever someone tells you, but that’s a sign of a lazy mind. And learn to discern facts from opinions. You know what they say about opinions…
- Consider the source. When you are gathering requirements, consider the credibility, experience and maybe most importantly, the agenda of the source. Not all sources are of equal value, and the credibility of the source is highly dependent upon the context of the situation (see the article “Reasons Why Doctors Can’t Manage Money”).
- Don’t get happy ears. Don’t listen for the answer that you want to hear. Instead focus on listening for the answers that you didn’t expect to hear. That’s the moment when learning really starts.
- Embrace struggling. The easy answer isn’t always the right answer. In fact, the easy answer is seldom the right answer when it comes to complex situations faced not in the world of data science, but also faced in society and the business world.
- Stay curious; have an insatiable appetite to learn. This is especially true in a world where technologies are changing so rapidly. Curiosity may have killed the cat, but I wouldn’t want a cat making decisions for me anyway.
- Apply the reasonableness test. Is what you are reading making sense from what you have seen or read elsewhere (sorry, the Pope didn’t vote in the last US election)? And while technologies are changing so rapidly, society norms and ethics really aren’t.
- Pause to think. Find a quiet place where you can sequester yourself away to really think about everything that you’ve pulled together. Take the time to think and contemplate before rushing to the answer.
- Conflict is good…and necessary. Life is full of tradeoffs that require striking a delicate balance between numerous competing factors (increase one factor while reducing another). These types of conflicts are the fuel for innovation (see the blog “Embracing Conflict to Fuel Digital Innovation” for more details).
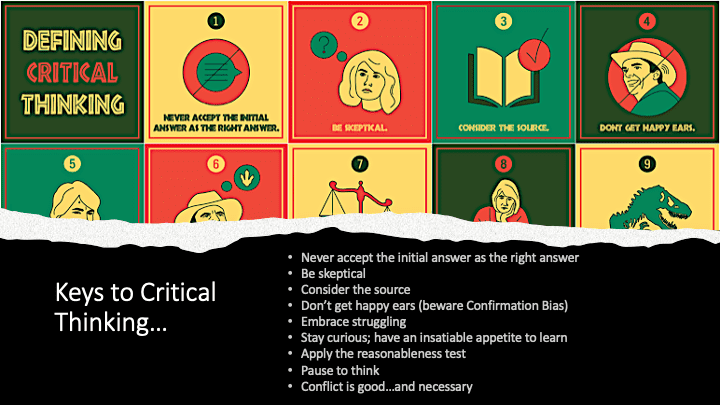
Figure 6: Critical Thinking and Becoming “Students of Data Science”
Summary: Life is About Improving the Odds Before Rolling the Dice
Data Literacy is an awareness of how our personal data is being used by organization who are using advanced analytics to uncover our personal preferences and biases to influence the probabilities around which you make your decisions.
The Data Literacy Education Framework is comprised of 4 subject areas:
- Data Awareness which talked about how everyone needs to be aware how their personal data is being captured and used to influence or manipulate how we think and the decisions that we make.
- Decision Literacy which discussed how humans make models of various complexity to make more informed and accurate decisions.
- AI/ML Literacy is understanding how AI/ML models work as they seek to optimize the KPI’s and metrics that comprise the AI/ML Utility Function (and around which the AI/ML model measures decision effectiveness) as it continuously learns and adapts from the interactions with its environment.
- Prediction Literacy is understanding how we leverage patterns, trends, and relationships to try to make predictions about what is likely to happen so that we can make more accurate decisions.
Finally, life is about rolling the dice, as there are no guarantees that you’ll get the outcomes you expect. Every time you drive a car, every time you walk across the street, every time you fly in an airplane, you are rolling the dice.
Wearing a seatbelt won’t guarantee that you won’t die in a car accident. Wearing a bike helmet won’t guarantee you won’t get hurt in a biking accident. Getting the Covid vaccination won’t guarantee that you won’t catch Covid. It’s all about rolling the dice.
Bottom-line: the practical aspect of data literacy is understanding how probabilities work, and what we can do through research and analysis to make informed decisions that improve the odds that when we do roll the dice, we get an outcome we expected and can live with. Your personal success (and ultimately the success of humankind) is highly dependent upon that understanding.
{kind=link}